Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploiting Spatial-Temporal Semantic Consistency for Video Scene Parsing
Paper and Code
Sep 06, 2021

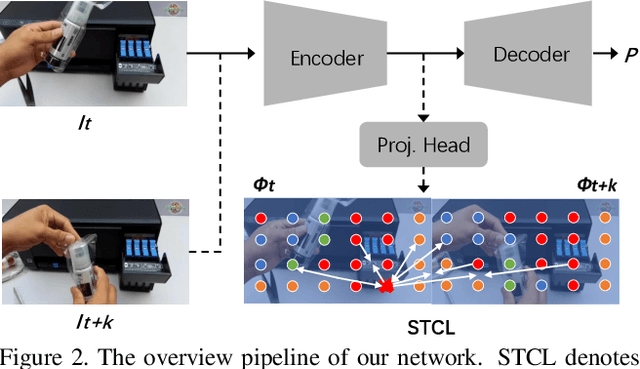

Compared with image scene parsing, video scene parsing introduces temporal information, which can effectively improve the consistency and accuracy of prediction. In this paper, we propose a Spatial-Temporal Semantic Consistency method to capture class-exclusive context information. Specifically, we design a spatial-temporal consistency loss to constrain the semantic consistency in spatial and temporal dimensions. In addition, we adopt an pseudo-labeling strategy to enrich the training dataset. We obtain the scores of 59.84% and 58.85% mIoU on development (test part 1) and testing set of VSPW, respectively. And our method wins the 1st place on VSPW challenge at ICCV2021.
* 1st Place technical report for "The 1st Video Scene Parsing in the
Wild Challenge" at ICCV2021
View paper on