 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMachine Learning Methods for Identifying Atrial Fibrillation Cases and Their Predictors in Patients With Hypertrophic Cardiomyopathy: The HCM-AF-Risk Model
Sep 19, 2021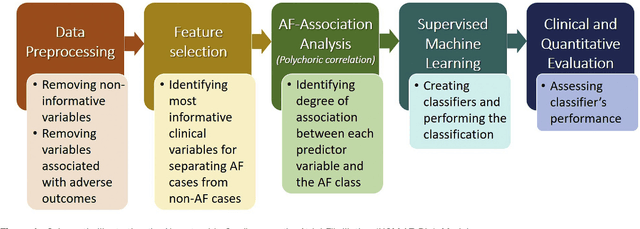
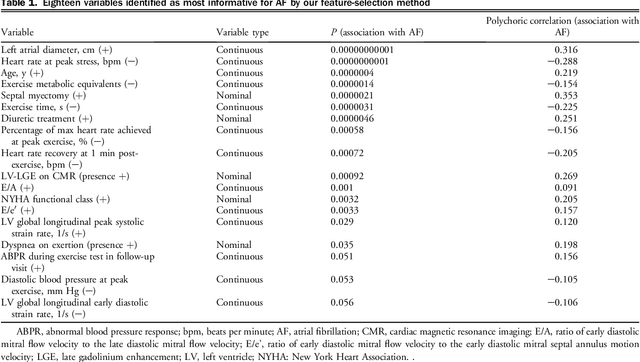
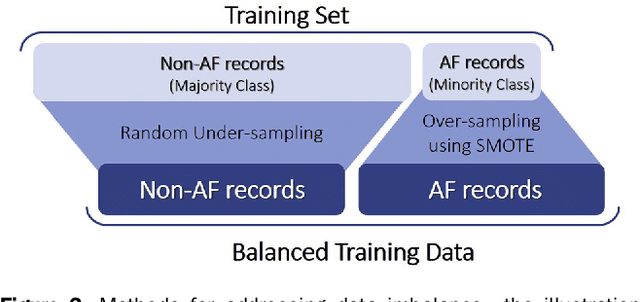
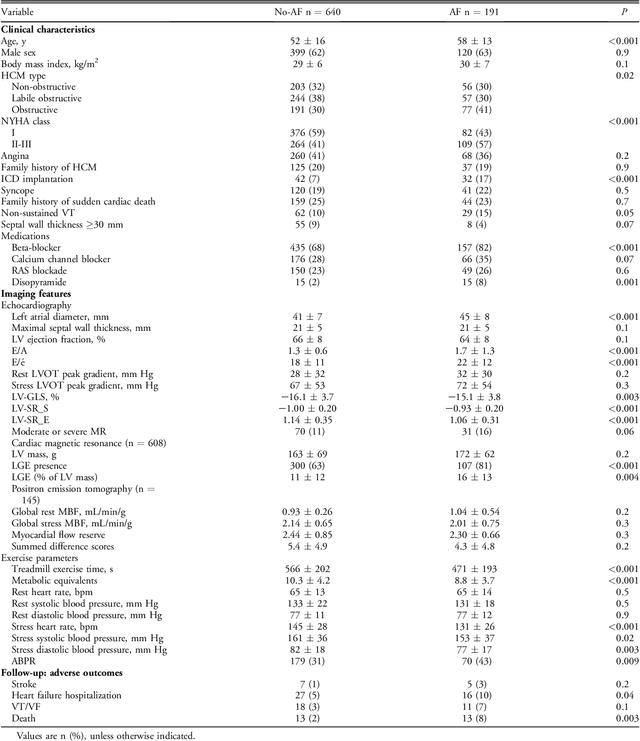
Hypertrophic cardiomyopathy (HCM) patients have a high incidence of atrial fibrillation (AF) and increased stroke risk, even with low risk of congestive heart failure, hypertension, age, diabetes, previous stroke/transient ischemic attack scores. Hence, there is a need to understand the pathophysiology of AF and stroke in HCM. In this retrospective study, we develop and apply a data-driven, machine learning based method to identify AF cases, and clinical and imaging features associated with AF, using electronic health record data. HCM patients with documented paroxysmal/persistent/permanent AF (n = 191) were considered AF cases, and the remaining patients in sinus rhythm (n = 640) were tagged as No-AF. We evaluated 93 clinical variables and the most informative variables useful for distinguishing AF from No-AF cases were selected based on the 2-sample t test and the information gain criterion. We identified 18 highly informative variables that are positively (n = 11) and negatively (n = 7) correlated with AF in HCM. Next, patient records were represented via these 18 variables. Data imbalance resulting from the relatively low number of AF cases was addressed via a combination of oversampling and under-sampling strategies. We trained and tested multiple classifiers under this sampling approach, showing effective classification. Specifically, an ensemble of logistic regression and naive Bayes classifiers, trained based on the 18 variables and corrected for data imbalance, proved most effective for separating AF from No-AF cases (sensitivity = 0.74, specificity = 0.70, C-index = 0.80). Our model is the first machine learning based method for identification of AF cases in HCM. This model demonstrates good performance, addresses data imbalance, and suggests that AF is associated with a more severe cardiac HCM phenotype.
CathAI: Fully Automated Interpretation of Coronary Angiograms Using Neural Networks
Jun 14, 2021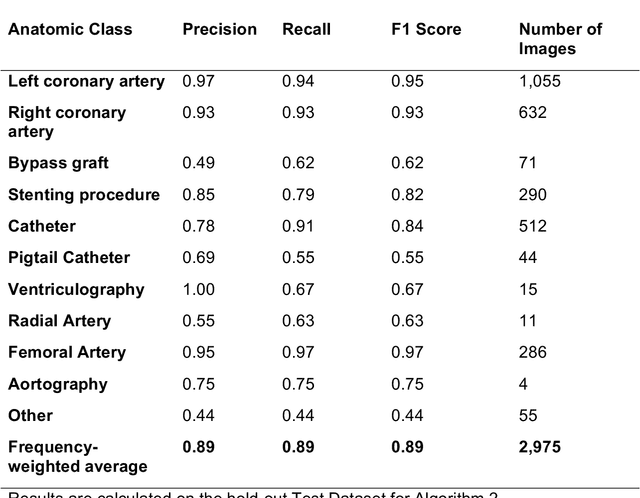
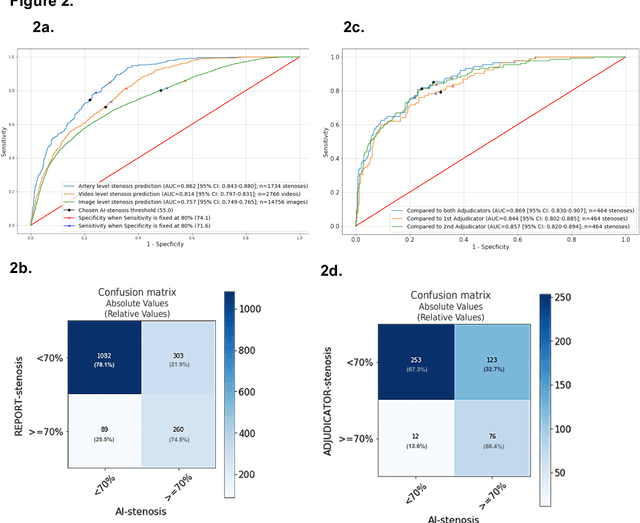
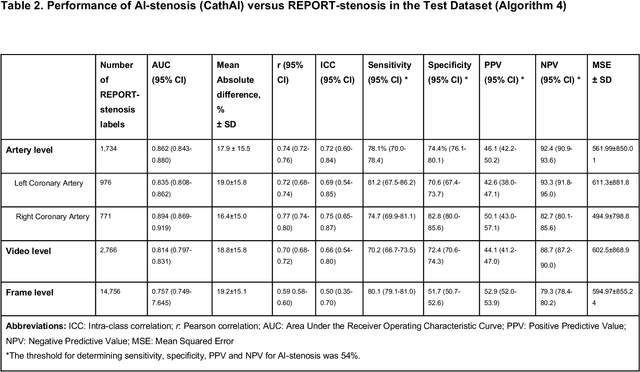
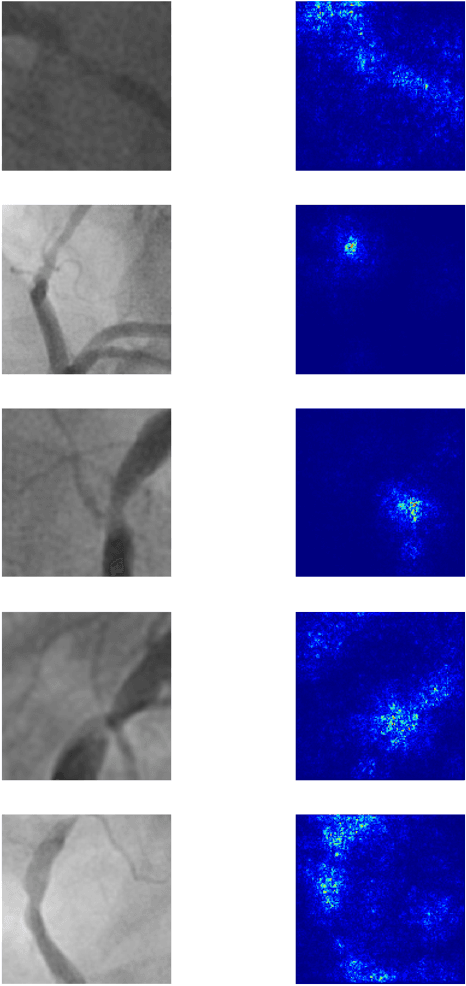
Coronary heart disease (CHD) is the leading cause of adult death in the United States and worldwide, and for which the coronary angiography procedure is the primary gateway for diagnosis and clinical management decisions. The standard-of-care for interpretation of coronary angiograms depends upon ad-hoc visual assessment by the physician operator. However, ad-hoc visual interpretation of angiograms is poorly reproducible, highly variable and bias prone. Here we show for the first time that fully-automated angiogram interpretation to estimate coronary artery stenosis is possible using a sequence of deep neural network algorithms. The algorithmic pipeline we developed--called CathAI--achieves state-of-the art performance across the sequence of tasks required to accomplish automated interpretation of unselected, real-world angiograms. CathAI (Algorithms 1-2) demonstrated positive predictive value, sensitivity and F1 score of >=90% to identify the projection angle overall and >=93% for left or right coronary artery angiogram detection, the primary anatomic structures of interest. To predict obstructive coronary artery stenosis (>=70% stenosis), CathAI (Algorithm 4) exhibited an area under the receiver operating characteristic curve (AUC) of 0.862 (95% CI: 0.843-0.880). When externally validated in a healthcare system in another country, CathAI AUC was 0.869 (95% CI: 0.830-0.907) to predict obstructive coronary artery stenosis. Our results demonstrate that multiple purpose-built neural networks can function in sequence to accomplish the complex series of tasks required for automated analysis of real-world angiograms. Deployment of CathAI may serve to increase standardization and reproducibility in coronary stenosis assessment, while providing a robust foundation to accomplish future tasks for algorithmic angiographic interpretation.
Using Multitask Learning to Improve 12-Lead Electrocardiogram Classification
Dec 04, 2018
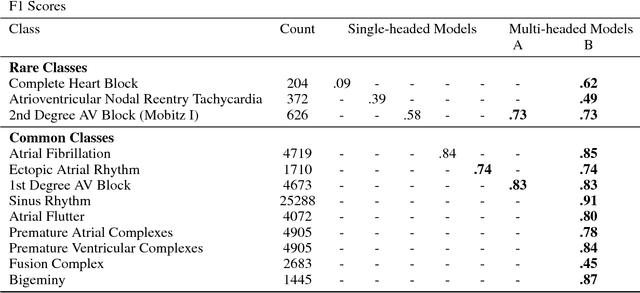
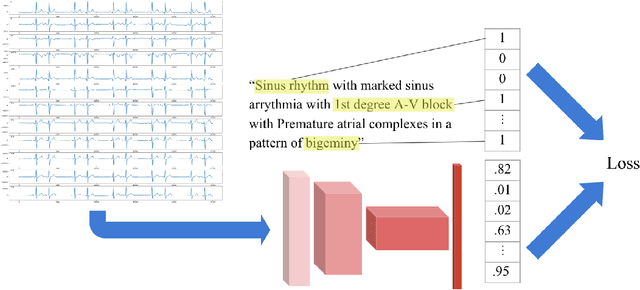
We develop a multi-task convolutional neural network (CNN) to classify multiple diagnoses from 12-lead electrocardiograms (ECGs) using a dataset comprised of over 40,000 ECGs, with labels derived from cardiologist clinical interpretations. Since many clinically important classes can occur in low frequencies, approaches are needed to improve performance on rare classes. We compare the performance of several single-class classifiers on rare classes to a multi-headed classifier across all available classes. We demonstrate that the addition of common classes can significantly improve CNN performance on rarer classes when compared to a model trained on the rarer class in isolation. Using this method, we develop a model with high performance as measured by F1 score on multiple clinically relevant classes compared against the gold-standard cardiologist interpretation.
DeepHeart: Semi-Supervised Sequence Learning for Cardiovascular Risk Prediction
Feb 07, 2018
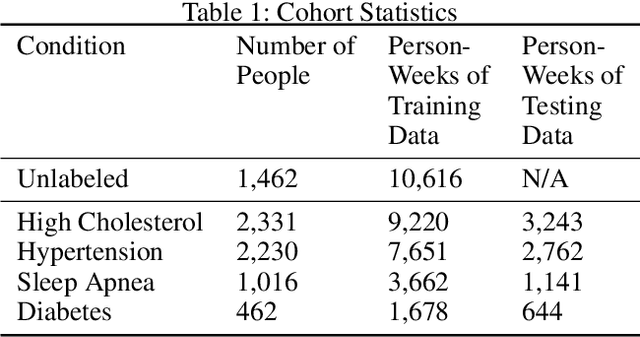
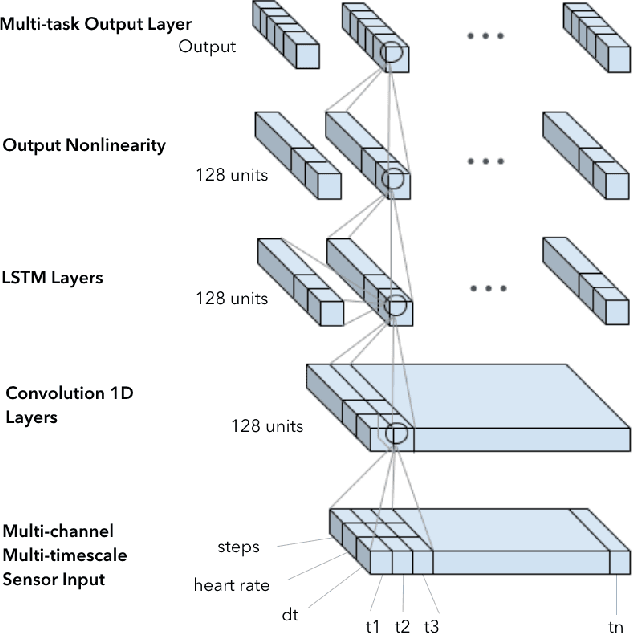
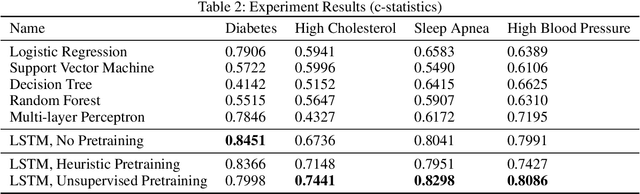
We train and validate a semi-supervised, multi-task LSTM on 57,675 person-weeks of data from off-the-shelf wearable heart rate sensors, showing high accuracy at detecting multiple medical conditions, including diabetes (0.8451), high cholesterol (0.7441), high blood pressure (0.8086), and sleep apnea (0.8298). We compare two semi-supervised train- ing methods, semi-supervised sequence learning and heuristic pretraining, and show they outperform hand-engineered biomarkers from the medical literature. We believe our work suggests a new approach to patient risk stratification based on cardiovascular risk scores derived from popular wearables such as Fitbit, Apple Watch, or Android Wear.