 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMachine Learning Methods for Identifying Atrial Fibrillation Cases and Their Predictors in Patients With Hypertrophic Cardiomyopathy: The HCM-AF-Risk Model
Paper and Code
Sep 19, 2021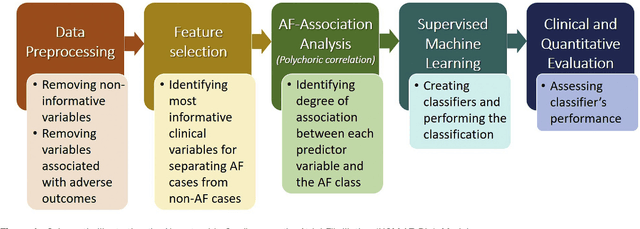
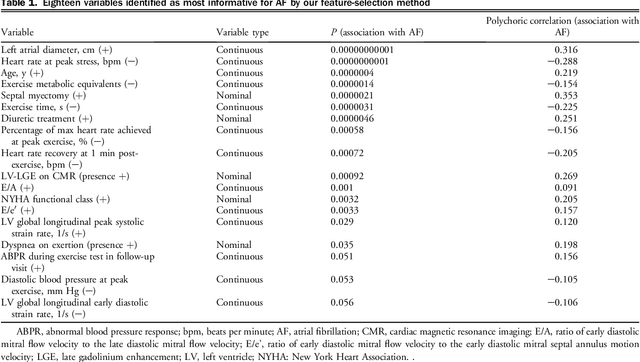
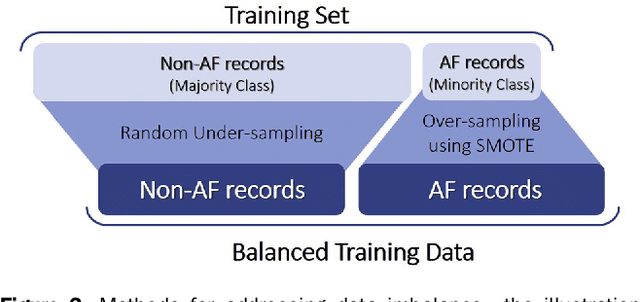
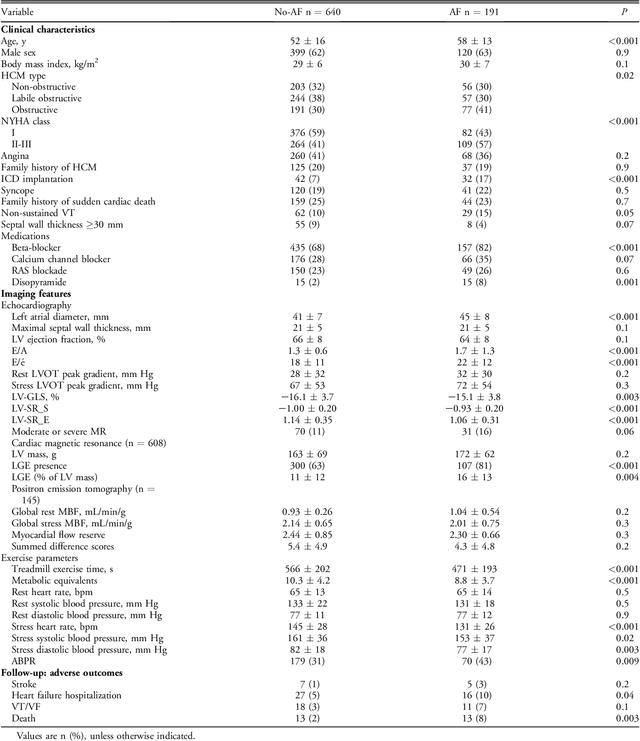
Hypertrophic cardiomyopathy (HCM) patients have a high incidence of atrial fibrillation (AF) and increased stroke risk, even with low risk of congestive heart failure, hypertension, age, diabetes, previous stroke/transient ischemic attack scores. Hence, there is a need to understand the pathophysiology of AF and stroke in HCM. In this retrospective study, we develop and apply a data-driven, machine learning based method to identify AF cases, and clinical and imaging features associated with AF, using electronic health record data. HCM patients with documented paroxysmal/persistent/permanent AF (n = 191) were considered AF cases, and the remaining patients in sinus rhythm (n = 640) were tagged as No-AF. We evaluated 93 clinical variables and the most informative variables useful for distinguishing AF from No-AF cases were selected based on the 2-sample t test and the information gain criterion. We identified 18 highly informative variables that are positively (n = 11) and negatively (n = 7) correlated with AF in HCM. Next, patient records were represented via these 18 variables. Data imbalance resulting from the relatively low number of AF cases was addressed via a combination of oversampling and under-sampling strategies. We trained and tested multiple classifiers under this sampling approach, showing effective classification. Specifically, an ensemble of logistic regression and naive Bayes classifiers, trained based on the 18 variables and corrected for data imbalance, proved most effective for separating AF from No-AF cases (sensitivity = 0.74, specificity = 0.70, C-index = 0.80). Our model is the first machine learning based method for identification of AF cases in HCM. This model demonstrates good performance, addresses data imbalance, and suggests that AF is associated with a more severe cardiac HCM phenotype.