 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBigDL 2.0: Seamless Scaling of AI Pipelines from Laptops to Distributed Cluster
Apr 03, 2022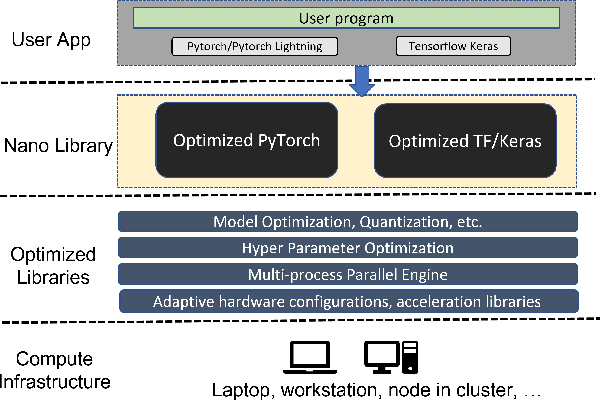



Most AI projects start with a Python notebook running on a single laptop; however, one usually needs to go through a mountain of pains to scale it to handle larger dataset (for both experimentation and production deployment). These usually entail many manual and error-prone steps for the data scientists to fully take advantage of the available hardware resources (e.g., SIMD instructions, multi-processing, quantization, memory allocation optimization, data partitioning, distributed computing, etc.). To address this challenge, we have open sourced BigDL 2.0 at https://github.com/intel-analytics/BigDL/ under Apache 2.0 license (combining the original BigDL and Analytics Zoo projects); using BigDL 2.0, users can simply build conventional Python notebooks on their laptops (with possible AutoML support), which can then be transparently accelerated on a single node (with up-to 9.6x speedup in our experiments), and seamlessly scaled out to a large cluster (across several hundreds servers in real-world use cases). BigDL 2.0 has already been adopted by many real-world users (such as Mastercard, Burger King, Inspur, etc.) in production.
BigDL: A Distributed Deep Learning Framework for Big Data
Jun 25, 2018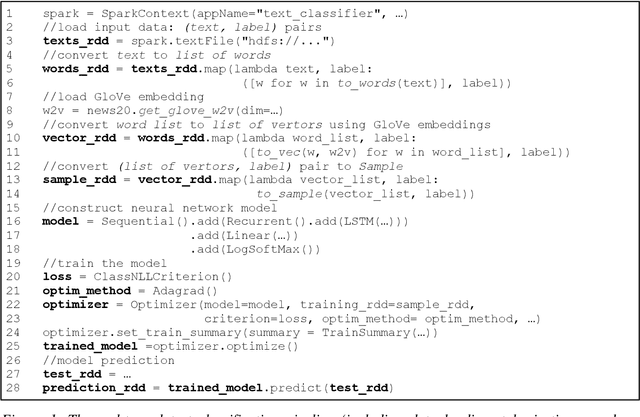
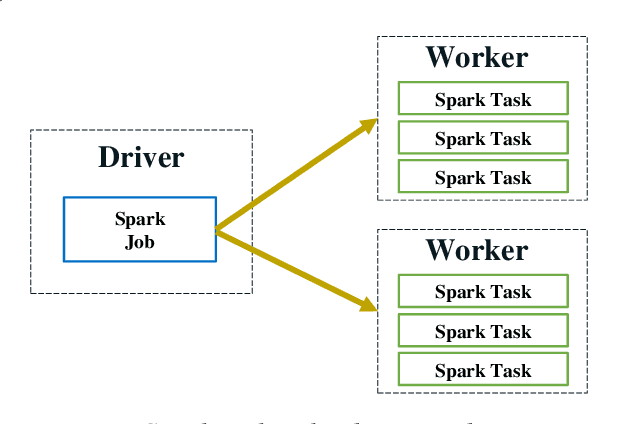

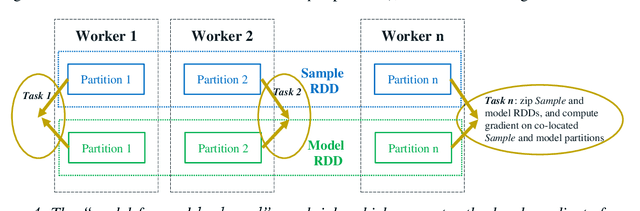
In this paper, we present BigDL, a distributed deep learning framework for Big Data platforms and workflows. It is implemented on top of Apache Spark, and allows users to write their deep learning applications as standard Spark programs (running directly on large-scale big data clusters in a distributed fashion). It provides an expressive, "data-analytics integrated" deep learning programming model, so that users can easily build the end-to-end analytics + AI pipelines under a unified programming paradigm; by implementing an AllReduce like operation using existing primitives in Spark (e.g., shuffle, broadcast, and in-memory data persistence), it also provides a highly efficient "parameter server" style architecture, so as to achieve highly scalable, data-parallel distributed training. Since its initial open source release, BigDL users have built many analytics and deep learning applications (e.g., object detection, sequence-to-sequence generation, visual similarity, neural recommendations, fraud detection, etc.) on Spark.