 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Robust Multilevel Semantic Cross-Modal Hashing
Paper and Code
Feb 07, 2020
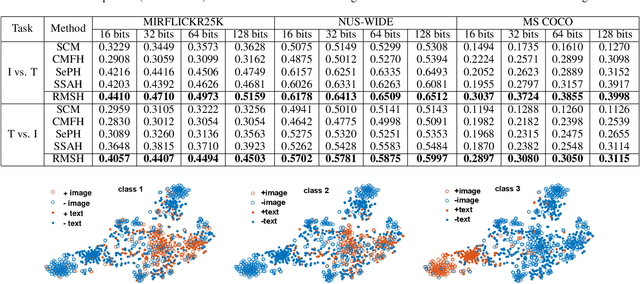

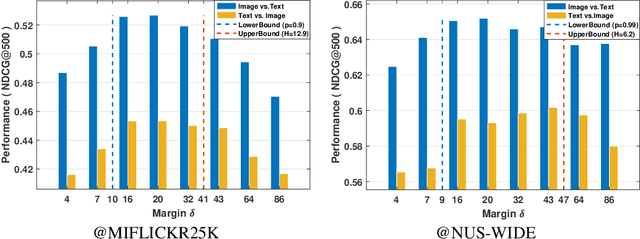
Hashing based cross-modal retrieval has recently made significant progress. But straightforward embedding data from different modalities into a joint Hamming space will inevitably produce false codes due to the intrinsic modality discrepancy and noises. We present a novel Robust Multilevel Semantic Hashing (RMSH) for more accurate cross-modal retrieval. It seeks to preserve fine-grained similarity among data with rich semantics, while explicitly require distances between dissimilar points to be larger than a specific value for strong robustness. For this, we give an effective bound of this value based on the information coding-theoretic analysis, and the above goals are embodied into a margin-adaptive triplet loss. Furthermore, we introduce pseudo-codes via fusing multiple hash codes to explore seldom-seen semantics, alleviating the sparsity problem of similarity information. Experiments on three benchmarks show the validity of the derived bounds, and our method achieves state-of-the-art performance.