 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFIPGNet:Pyramid grafting network with feature interaction strategies
Jul 04, 2024
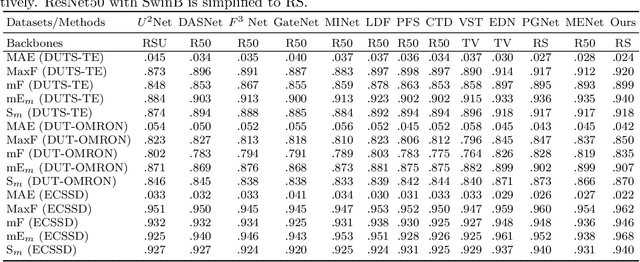
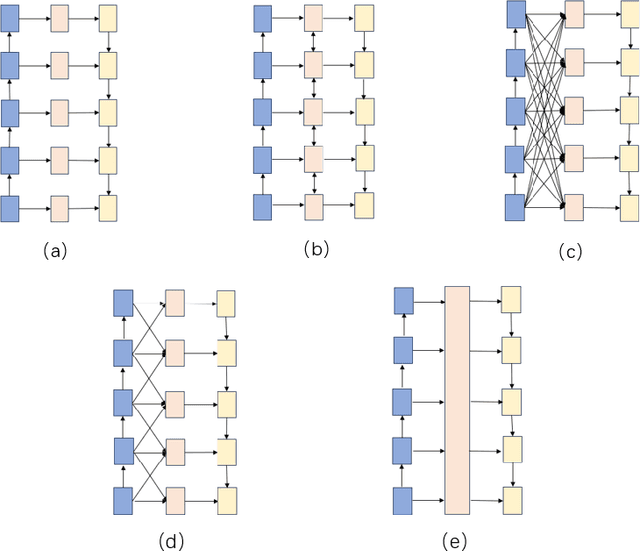
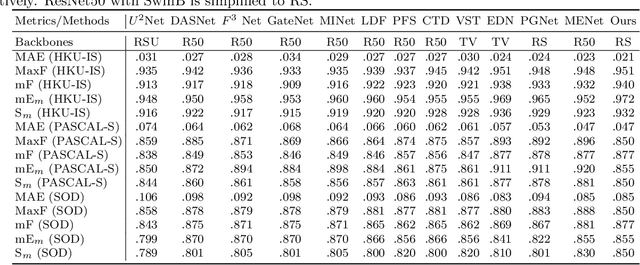
Salient object detection is designed to identify the objects in an image that attract the most visual attention.Currently, the most advanced method of significance object detection adopts pyramid grafting network architecture.However, pyramid-graft network architecture still has the problem of failing to accurately locate significant targets.We observe that this is mainly due to the fact that current salient object detection methods simply aggregate different scale features, ignoring the correlation between different scale features.To overcome these problems, we propose a new salience object detection framework(FIPGNet),which is a pyramid graft network with feature interaction strategies.Specifically, we propose an attention-mechanism based feature interaction strategy (FIA) that innovatively introduces spatial agent Cross Attention (SACA) to achieve multi-level feature interaction, highlighting important spatial regions from a spatial perspective, thereby enhancing salient regions.And the channel proxy Cross Attention Module (CCM), which is used to effectively connect the features extracted by the backbone network and the features processed using the spatial proxy cross attention module, eliminating inconsistencies.Finally, under the action of these two modules, the prominent target location problem in the current pyramid grafting network model is solved.Experimental results on six challenging datasets show that the proposed method outperforms the current 12 salient object detection methods on four indicators.
Adaptive Step-size Perception Unfolding Network with Non-local Hybrid Attention for Hyperspectral Image Reconstruction
Jul 04, 2024



Deep unfolding methods and transformer architecture have recently shown promising results in hyperspectral image (HSI) reconstruction. However, there still exist two issues: (1) in the data subproblem, most methods represents the stepsize utilizing a learnable parameter. Nevertheless, for different spectral channel, error between features and ground truth is unequal. (2) Transformer struggles to balance receptive field size with pixel-wise detail information. To overcome the aforementioned drawbacks, We proposed an adaptive step-size perception unfolding network (ASPUN), a deep unfolding network based on FISTA algorithm, which uses an adaptive step-size perception module to estimate the update step-size of each spectral channel. In addition, we design a Non-local Hybrid Attention Transformer(NHAT) module for fully leveraging the receptive field advantage of transformer. By plugging the NLHA into the Non-local Information Aggregation (NLIA) module, the unfolding network can achieve better reconstruction results. Experimental results show that our ASPUN is superior to the existing SOTA algorithms and achieves the best performance.
Multi-level Reliable Guidance for Unpaired Multi-view Clustering
Jul 02, 2024In this paper, we address the challenging problem of unpaired multi-view clustering (UMC), aiming to perform effective joint clustering using unpaired observed samples across multiple views. Commonly, traditional incomplete multi-view clustering (IMC) methods often depend on paired samples to capture complementary information between views. However, the strategy becomes impractical in UMC due to the absence of paired samples. Although some researchers have attempted to tackle the issue by preserving consistent cluster structures across views, they frequently neglect the confidence of these cluster structures, especially for boundary samples and uncertain cluster structures during the initial training. Therefore, we propose a method called Multi-level Reliable Guidance for UMC (MRG-UMC), which leverages multi-level clustering to aid in learning a trustworthy cluster structure across inner-view, cross-view, and common-view, respectively. Specifically, within each view, multi-level clustering fosters a trustworthy cluster structure across different levels and reduces clustering error. In cross-view learning, reliable view guidance enhances the confidence of the cluster structures in other views. Similarly, within the multi-level framework, the incorporation of a common view aids in aligning different views, thereby reducing the clustering error and uncertainty of cluster structure. Finally, as evidenced by extensive experiments, our method for UMC demonstrates significant efficiency improvements compared to 20 state-of-the-art methods.
Unpaired Multi-view Clustering via Reliable View Guidance
Apr 27, 2024



This paper focuses on unpaired multi-view clustering (UMC), a challenging problem where paired observed samples are unavailable across multiple views. The goal is to perform effective joint clustering using the unpaired observed samples in all views. In incomplete multi-view clustering, existing methods typically rely on sample pairing between views to capture their complementary. However, that is not applicable in the case of UMC. Hence, we aim to extract the consistent cluster structure across views. In UMC, two challenging issues arise: uncertain cluster structure due to lack of label and uncertain pairing relationship due to absence of paired samples. We assume that the view with a good cluster structure is the reliable view, which acts as a supervisor to guide the clustering of the other views. With the guidance of reliable views, a more certain cluster structure of these views is obtained while achieving alignment between reliable views and other views. Then we propose Reliable view Guidance with one reliable view (RG-UMC) and multiple reliable views (RGs-UMC) for UMC. Specifically, we design alignment modules with one reliable view and multiple reliable views, respectively, to adaptively guide the optimization process. Also, we utilize the compactness module to enhance the relationship of samples within the same cluster. Meanwhile, an orthogonal constraint is applied to latent representation to obtain discriminate features. Extensive experiments show that both RG-UMC and RGs-UMC outperform the best state-of-the-art method by an average of 24.14\% and 29.42\% in NMI, respectively.