 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAceNAS: Learning to Rank Ace Neural Architectures with Weak Supervision of Weight Sharing
Paper and Code
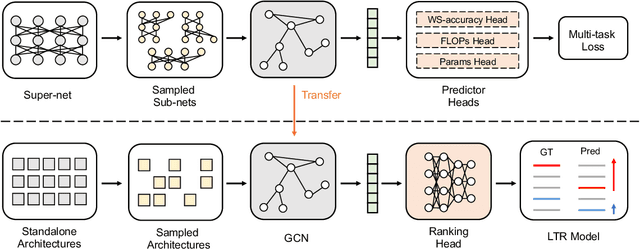
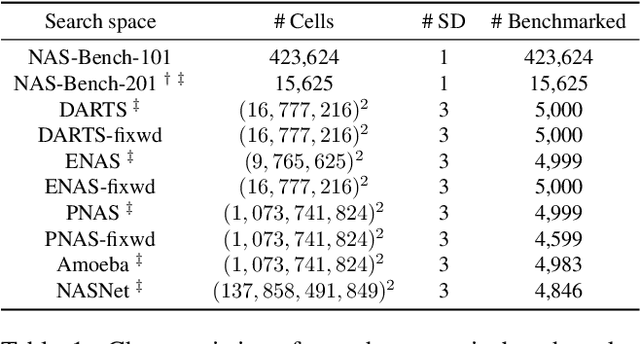
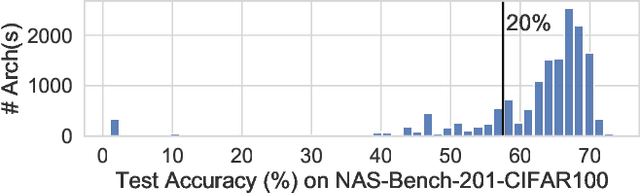
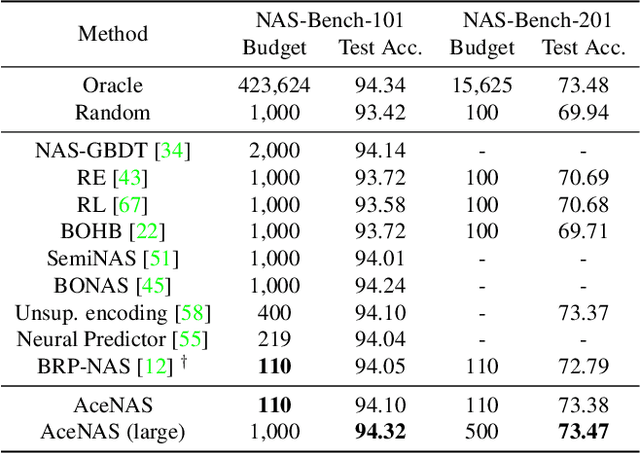
Architecture performance predictors have been widely used in neural architecture search (NAS). Although they are shown to be simple and effective, the optimization objectives in previous arts (e.g., precise accuracy estimation or perfect ranking of all architectures in the space) did not capture the ranking nature of NAS. In addition, a large number of ground-truth architecture-accuracy pairs are usually required to build a reliable predictor, making the process too computationally expensive. To overcome these, in this paper, we look at NAS from a novel point of view and introduce Learning to Rank (LTR) methods to select the best (ace) architectures from a space. Specifically, we propose to use Normalized Discounted Cumulative Gain (NDCG) as the target metric and LambdaRank as the training algorithm. We also propose to leverage weak supervision from weight sharing by pretraining architecture representation on weak labels obtained from the super-net and then finetuning the ranking model using a small number of architectures trained from scratch. Extensive experiments on NAS benchmarks and large-scale search spaces demonstrate that our approach outperforms SOTA with a significantly reduced search cost.