 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOverview of the CLEF-2019 CheckThat!: Automatic Identification and Verification of Claims
Paper and Code
Sep 25, 2021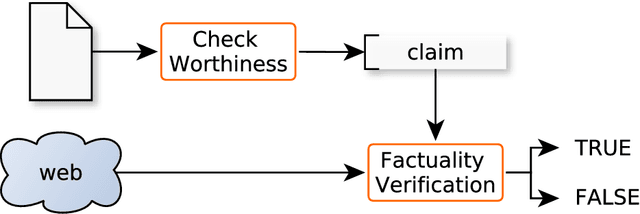
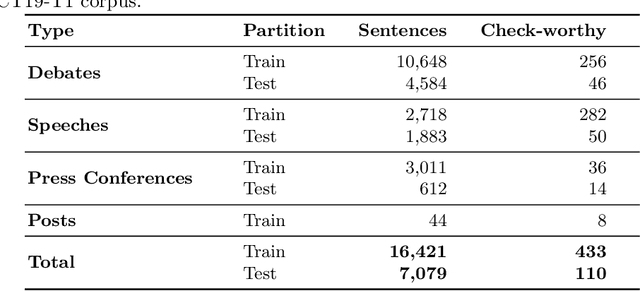


We present an overview of the second edition of the CheckThat! Lab at CLEF 2019. The lab featured two tasks in two different languages: English and Arabic. Task 1 (English) challenged the participating systems to predict which claims in a political debate or speech should be prioritized for fact-checking. Task 2 (Arabic) asked to (A) rank a given set of Web pages with respect to a check-worthy claim based on their usefulness for fact-checking that claim, (B) classify these same Web pages according to their degree of usefulness for fact-checking the target claim, (C) identify useful passages from these pages, and (D) use the useful pages to predict the claim's factuality. CheckThat! provided a full evaluation framework, consisting of data in English (derived from fact-checking sources) and Arabic (gathered and annotated from scratch) and evaluation based on mean average precision (MAP) and normalized discounted cumulative gain (nDCG) for ranking, and F1 for classification. A total of 47 teams registered to participate in this lab, and fourteen of them actually submitted runs (compared to nine last year). The evaluation results show that the most successful approaches to Task 1 used various neural networks and logistic regression. As for Task 2, learning-to-rank was used by the highest scoring runs for subtask A, while different classifiers were used in the other subtasks. We release to the research community all datasets from the lab as well as the evaluation scripts, which should enable further research in the important tasks of check-worthiness estimation and automatic claim verification.