 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUntangling Hate Speech Definitions: A Semantic Componential Analysis Across Cultures and Domains
Paper and Code
Nov 11, 2024
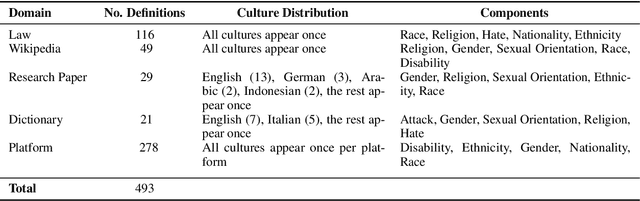

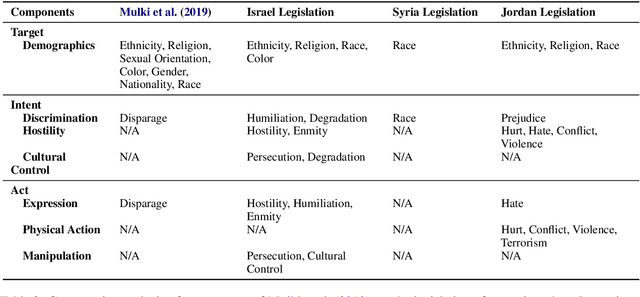
Hate speech relies heavily on cultural influences, leading to varying individual interpretations. For that reason, we propose a Semantic Componential Analysis (SCA) framework for a cross-cultural and cross-domain analysis of hate speech definitions. We create the first dataset of definitions derived from five domains: online dictionaries, research papers, Wikipedia articles, legislation, and online platforms, which are later analyzed into semantic components. Our analysis reveals that the components differ from definition to definition, yet many domains borrow definitions from one another without taking into account the target culture. We conduct zero-shot model experiments using our proposed dataset, employing three popular open-sourced LLMs to understand the impact of different definitions on hate speech detection. Our findings indicate that LLMs are sensitive to definitions: responses for hate speech detection change according to the complexity of definitions used in the prompt.