 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLAILA: A Large Trait-Based Dataset for Arabic Automated Essay Scoring
Dec 30, 2025Automated Essay Scoring (AES) has gained increasing attention in recent years, yet research on Arabic AES remains limited due to the lack of publicly available datasets. To address this, we introduce LAILA, the largest publicly available Arabic AES dataset to date, comprising 7,859 essays annotated with holistic and trait-specific scores on seven dimensions: relevance, organization, vocabulary, style, development, mechanics, and grammar. We detail the dataset design, collection, and annotations, and provide benchmark results using state-of-the-art Arabic and English models in prompt-specific and cross-prompt settings. LAILA fills a critical need in Arabic AES research, supporting the development of robust scoring systems.
TRATES: Trait-Specific Rubric-Assisted Cross-Prompt Essay Scoring
May 20, 2025Research on holistic Automated Essay Scoring (AES) is long-dated; yet, there is a notable lack of attention for assessing essays according to individual traits. In this work, we propose TRATES, a novel trait-specific and rubric-based cross-prompt AES framework that is generic yet specific to the underlying trait. The framework leverages a Large Language Model (LLM) that utilizes the trait grading rubrics to generate trait-specific features (represented by assessment questions), then assesses those features given an essay. The trait-specific features are eventually combined with generic writing-quality and prompt-specific features to train a simple classical regression model that predicts trait scores of essays from an unseen prompt. Experiments show that TRATES achieves a new state-of-the-art performance across all traits on a widely-used dataset, with the generated LLM-based features being the most significant.
Graded Relevance Scoring of Written Essays with Dense Retrieval
May 08, 2024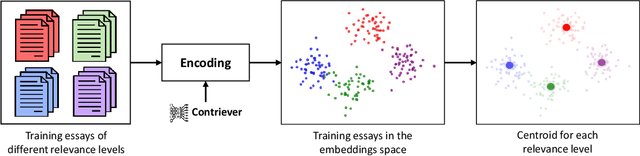
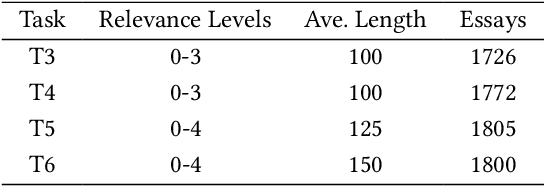
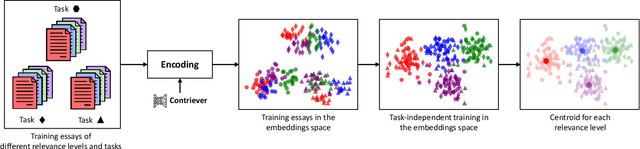
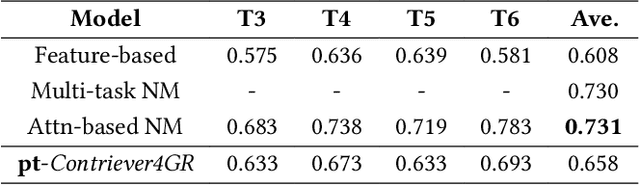
Automated Essay Scoring automates the grading process of essays, providing a great advantage for improving the writing proficiency of students. While holistic essay scoring research is prevalent, a noticeable gap exists in scoring essays for specific quality traits. In this work, we focus on the relevance trait, which measures the ability of the student to stay on-topic throughout the entire essay. We propose a novel approach for graded relevance scoring of written essays that employs dense retrieval encoders. Dense representations of essays at different relevance levels then form clusters in the embeddings space, such that their centroids are potentially separate enough to effectively represent their relevance levels. We hence use the simple 1-Nearest-Neighbor classification over those centroids to determine the relevance level of an unseen essay. As an effective unsupervised dense encoder, we leverage Contriever, which is pre-trained with contrastive learning and demonstrated comparable performance to supervised dense retrieval models. We tested our approach on both task-specific (i.e., training and testing on same task) and cross-task (i.e., testing on unseen task) scenarios using the widely used ASAP++ dataset. Our method establishes a new state-of-the-art performance in the task-specific scenario, while its extension for the cross-task scenario exhibited a performance that is on par with the state-of-the-art model for that scenario. We also analyzed the performance of our approach in a more practical few-shot scenario, showing that it can significantly reduce the labeling cost while sacrificing only 10% of its effectiveness.
Can Large Language Models Automatically Score Proficiency of Written Essays?
Mar 10, 2024



Although several methods were proposed to address the problem of automated essay scoring (AES) in the last 50 years, there is still much to desire in terms of effectiveness. Large Language Models (LLMs) are transformer-based models that demonstrate extraordinary capabilities on various tasks. In this paper, we test the ability of LLMs, given their powerful linguistic knowledge, to analyze and effectively score written essays. We experimented with two popular LLMs, namely ChatGPT and Llama. We aim to check if these models can do this task and, if so, how their performance is positioned among the state-of-the-art (SOTA) models across two levels, holistically and per individual writing trait. We utilized prompt-engineering tactics in designing four different prompts to bring their maximum potential to this task. Our experiments conducted on the ASAP dataset revealed several interesting observations. First, choosing the right prompt depends highly on the model and nature of the task. Second, the two LLMs exhibited comparable average performance in AES, with a slight advantage for ChatGPT. Finally, despite the performance gap between the two LLMs and SOTA models in terms of predictions, they provide feedback to enhance the quality of the essays, which can potentially help both teachers and students.