 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArtificial Neural Networks to Recognize Speakers Division from Continuous Bengali Speech
Apr 18, 2024



Voice based applications are ruling over the era of automation because speech has a lot of factors that determine a speakers information as well as speech. Modern Automatic Speech Recognition (ASR) is a blessing in the field of Human-Computer Interaction (HCI) for efficient communication among humans and devices using Artificial Intelligence technology. Speech is one of the easiest mediums of communication because it has a lot of identical features for different speakers. Nowadays it is possible to determine speakers and their identity using their speech in terms of speaker recognition. In this paper, we presented a method that will provide a speakers geographical identity in a certain region using continuous Bengali speech. We consider eight different divisions of Bangladesh as the geographical region. We applied the Mel Frequency Cepstral Coefficient (MFCC) and Delta features on an Artificial Neural Network to classify speakers division. We performed some preprocessing tasks like noise reduction and 8-10 second segmentation of raw audio before feature extraction. We used our dataset of more than 45 hours of audio data from 633 individual male and female speakers. We recorded the highest accuracy of 85.44%.
Machine Learning Technique Based Fake News Detection
Sep 18, 2023

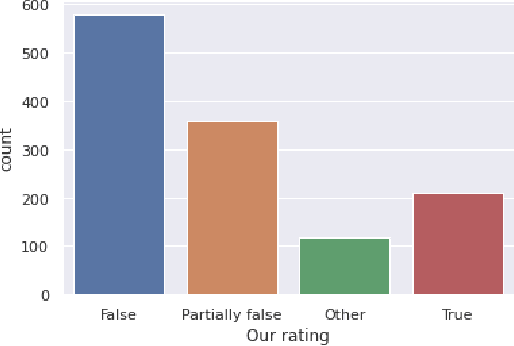

False news has received attention from both the general public and the scholarly world. Such false information has the ability to affect public perception, giving nefarious groups the chance to influence the results of public events like elections. Anyone can share fake news or facts about anyone or anything for their personal gain or to cause someone trouble. Also, information varies depending on the part of the world it is shared on. Thus, in this paper, we have trained a model to classify fake and true news by utilizing the 1876 news data from our collected dataset. We have preprocessed the data to get clean and filtered texts by following the Natural Language Processing approaches. Our research conducts 3 popular Machine Learning (Stochastic gradient descent, Na\"ive Bayes, Logistic Regression,) and 2 Deep Learning (Long-Short Term Memory, ASGD Weight-Dropped LSTM, or AWD-LSTM) algorithms. After we have found our best Naive Bayes classifier with 56% accuracy and an F1-macro score of an average of 32%.
Zero- and Few-Shot Prompting with LLMs: A Comparative Study with Fine-tuned Models for Bangla Sentiment Analysis
Aug 21, 2023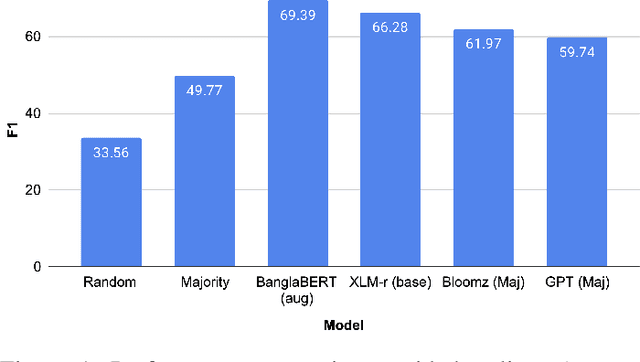
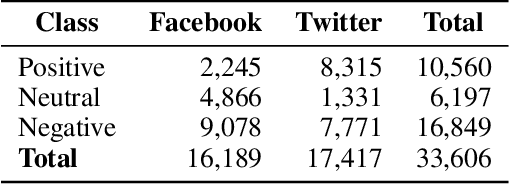
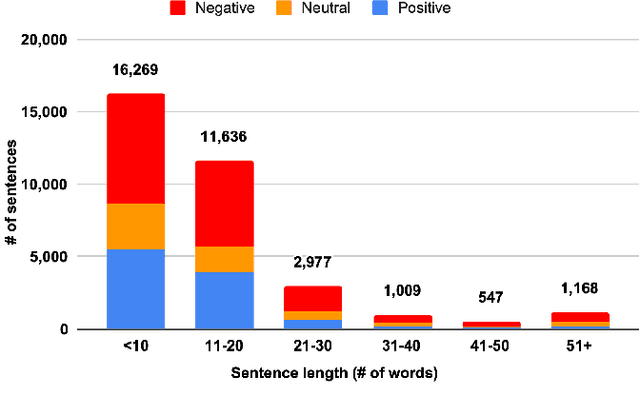
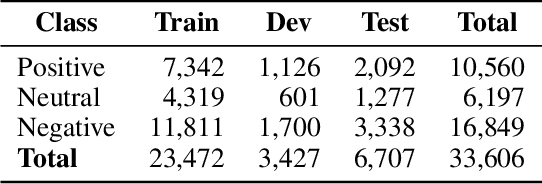
The rapid expansion of the digital world has propelled sentiment analysis into a critical tool across diverse sectors such as marketing, politics, customer service, and healthcare. While there have been significant advancements in sentiment analysis for widely spoken languages, low-resource languages, such as Bangla, remain largely under-researched due to resource constraints. Furthermore, the recent unprecedented performance of Large Language Models (LLMs) in various applications highlights the need to evaluate them in the context of low-resource languages. In this study, we present a sizeable manually annotated dataset encompassing 33,605 Bangla news tweets and Facebook comments. We also investigate zero- and few-shot in-context learning with several language models, including Flan-T5, GPT-4, and Bloomz, offering a comparative analysis against fine-tuned models. Our findings suggest that monolingual transformer-based models consistently outperform other models, even in zero and few-shot scenarios. To foster continued exploration, we intend to make this dataset and our research tools publicly available to the broader research community. In the spirit of further research, we plan to make this dataset and our experimental resources publicly accessible to the wider research community.
Z-Index at CheckThat! Lab 2022: Check-Worthiness Identification on Tweet Text
Jul 15, 2022
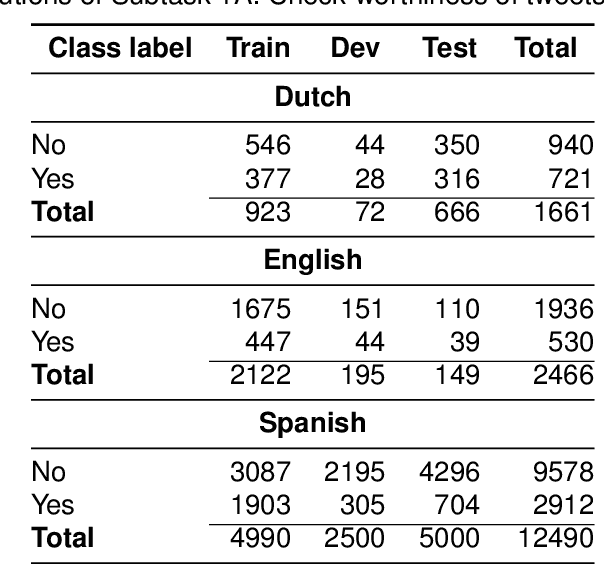
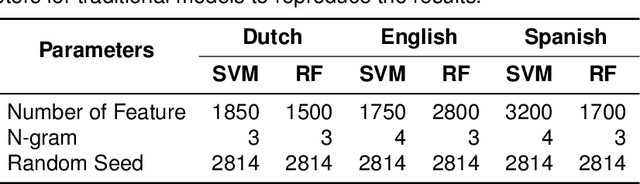

The wide use of social media and digital technologies facilitates sharing various news and information about events and activities. Despite sharing positive information misleading and false information is also spreading on social media. There have been efforts in identifying such misleading information both manually by human experts and automatic tools. Manual effort does not scale well due to the high volume of information, containing factual claims, are appearing online. Therefore, automatically identifying check-worthy claims can be very useful for human experts. In this study, we describe our participation in Subtask-1A: Check-worthiness of tweets (English, Dutch and Spanish) of CheckThat! lab at CLEF 2022. We performed standard preprocessing steps and applied different models to identify whether a given text is worthy of fact checking or not. We use the oversampling technique to balance the dataset and applied SVM and Random Forest (RF) with TF-IDF representations. We also used BERT multilingual (BERT-m) and XLM-RoBERTa-base pre-trained models for the experiments. We used BERT-m for the official submissions and our systems ranked as 3rd, 5th, and 12th in Spanish, Dutch, and English, respectively. In further experiments, our evaluation shows that transformer models (BERT-m and XLM-RoBERTa-base) outperform the SVM and RF in Dutch and English languages where a different scenario is observed for Spanish.