 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeACR: A Benchmark for Automatic Cohort Retrieval
Jun 20, 2024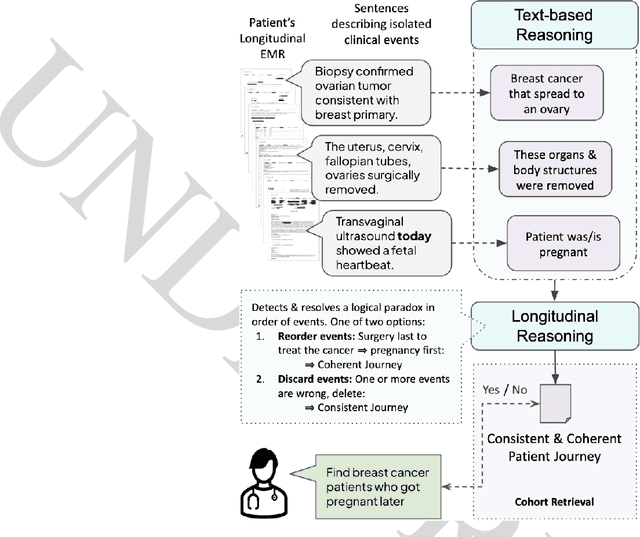
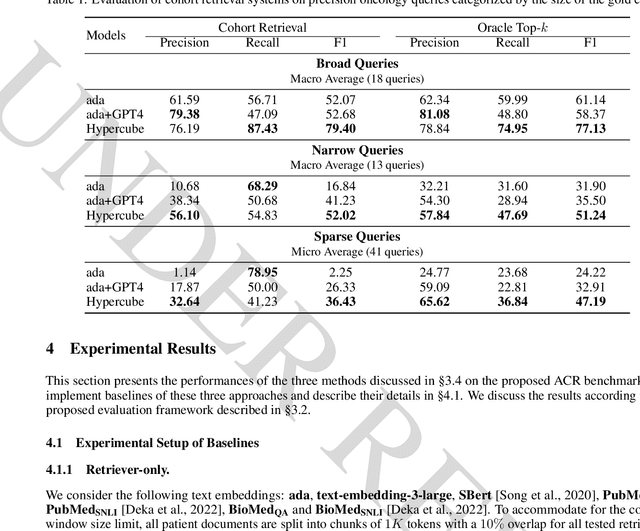
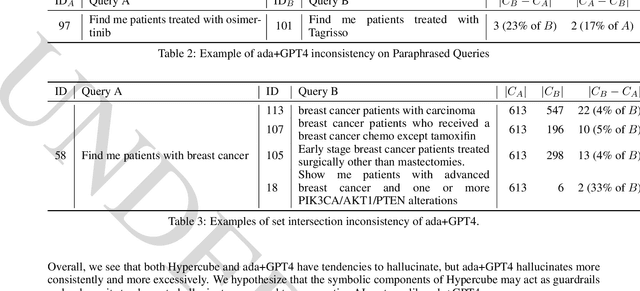
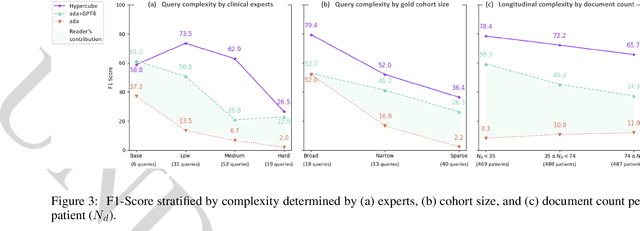
Identifying patient cohorts is fundamental to numerous healthcare tasks, including clinical trial recruitment and retrospective studies. Current cohort retrieval methods in healthcare organizations rely on automated queries of structured data combined with manual curation, which are time-consuming, labor-intensive, and often yield low-quality results. Recent advancements in large language models (LLMs) and information retrieval (IR) offer promising avenues to revolutionize these systems. Major challenges include managing extensive eligibility criteria and handling the longitudinal nature of unstructured Electronic Medical Records (EMRs) while ensuring that the solution remains cost-effective for real-world application. This paper introduces a new task, Automatic Cohort Retrieval (ACR), and evaluates the performance of LLMs and commercial, domain-specific neuro-symbolic approaches. We provide a benchmark task, a query dataset, an EMR dataset, and an evaluation framework. Our findings underscore the necessity for efficient, high-quality ACR systems capable of longitudinal reasoning across extensive patient databases.
Neural Machine Translation of Clinical Text: An Empirical Investigation into Multilingual Pre-Trained Language Models and Transfer-Learning
Dec 12, 2023We conduct investigations on clinical text machine translation by examining multilingual neural network models using deep learning such as Transformer based structures. Furthermore, to address the language resource imbalance issue, we also carry out experiments using a transfer learning methodology based on massive multilingual pre-trained language models (MMPLMs). The experimental results on three subtasks including 1) clinical case (CC), 2) clinical terminology (CT), and 3) ontological concept (OC) show that our models achieved top-level performances in the ClinSpEn-2022 shared task on English-Spanish clinical domain data. Furthermore, our expert-based human evaluations demonstrate that the small-sized pre-trained language model (PLM) won over the other two extra-large language models by a large margin, in the clinical domain fine-tuning, which finding was never reported in the field. Finally, the transfer learning method works well in our experimental setting using the WMT21fb model to accommodate a new language space Spanish that was not seen at the pre-training stage within WMT21fb itself, which deserves more exploitation for clinical knowledge transformation, e.g. to investigate into more languages. These research findings can shed some light on domain-specific machine translation development, especially in clinical and healthcare fields. Further research projects can be carried out based on our work to improve healthcare text analytics and knowledge transformation.
Predicting Perfect Quality Segments in MT Output with Fine-Tuned OpenAI LLM: Is it possible to capture editing distance patterns from historical data?
Aug 21, 2023Translation Quality Estimation (TQE) is an essential step before deploying the output translation into usage. TQE is also critical in assessing machine translation (MT) and human translation (HT) quality without seeing the reference translations. This work examines whether the state-of-the-art large language models (LLMs) can be fine-tuned for the TQE task and their capability. We take ChatGPT as one example and approach TQE as a binary classification task. Using \textbf{eight language pairs} including English to Italian, German, French, Japanese, Dutch, Portuguese, Turkish, and Chinese training corpora, our experimental results show that fine-tuned ChatGPT via its API can achieve a relatively high score on predicting translation quality, i.e. \textit{if the translation needs to be edited}. However, there is definitely much space to improve the model accuracy, e.g. they are 82.42\% and 83.69\% for English-Italian and English-German respectively using our experimental settings. English-Italiano bilingual Abstract is available in the paper.
Using Massive Multilingual Pre-Trained Language Models Towards Real Zero-Shot Neural Machine Translation in Clinical Domain
Oct 12, 2022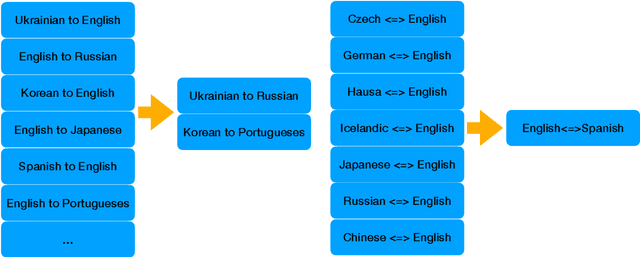


Massively multilingual pre-trained language models (MMPLMs) are developed in recent years demonstrating superpowers and the pre-knowledge they acquire for downstream tasks. In this work, we investigate whether MMPLMs can be applied to zero-shot machine translation (MT) toward entirely new language pairs and new domains. We carry out an experimental investigation using Meta-AI's MMPLMs "wmt21-dense-24-wide-en-X and X-en (WMT21fb)" which were pre-trained on 7 language pairs and 14 translation directions including English to Czech, German, Hausa, Icelandic, Japanese, Russian, and Chinese, and opposite direction. We fine-tune these MMPLMs towards English-Spanish language pair which did not exist at all in their original pre-trained corpora both implicitly and explicitly. We prepare carefully aligned clinical domain data for this fine-tuning, which is different from their original mixed domain knowledge as well. Our experimental result shows that the fine-tuning is very successful using just 250k well-aligned in-domain EN-ES pairs/sentences for three sub-task translation tests: clinical cases, clinical terms, and ontology concepts. It achieves very close evaluation scores to another MMPLM NLLB from Meta-AI, which included Spanish as a high-resource setting in the pre-training. To the best of our knowledge, this is the first work on using MMPLMs towards real zero-shot NMT successfully for totally unseen languages during pre-training, and also the first in clinical domain for such a study.
Examining Large Pre-Trained Language Models for Machine Translation: What You Don't Know About It
Sep 16, 2022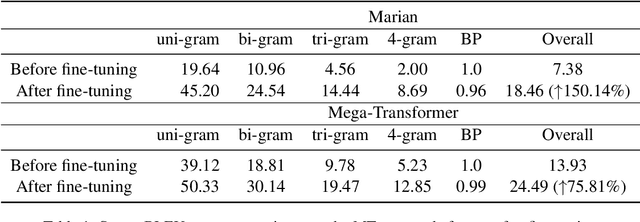
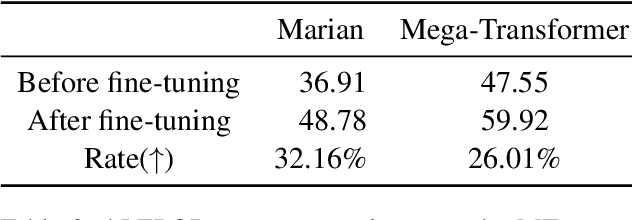

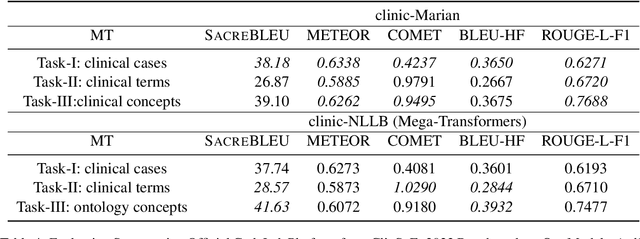
Pre-trained language models (PLMs) often take advantage of the monolingual and multilingual dataset that is freely available online to acquire general or mixed domain knowledge before deployment into specific tasks. Extra-large PLMs (xLPLMs) are proposed very recently to claim supreme performances over smaller-sized PLMs such as in machine translation (MT) tasks. These xLPLMs include Meta-AI's wmt21-dense-24-wide-en-X (2021) and NLLB (2022). In this work, we examine if xLPLMs are absolutely superior to smaller-sized PLMs in fine-tuning toward domain-specific MTs. We use two different in-domain data of different sizes: commercial automotive in-house data and clinical shared task data from the ClinSpEn2022 challenge at WMT2022. We choose popular Marian Helsinki as smaller sized PLM and two massive-sized Mega-Transformers from Meta-AI as xLPLMs. Our experimental investigation shows that 1) on smaller sized in-domain commercial automotive data, xLPLM wmt21-dense-24-wide-en-X indeed shows much better evaluation scores using SacreBLEU and hLEPOR metrics than smaller-sized Marian, even though its score increase rate is lower than Marian after fine-tuning; 2) on relatively larger-size well prepared clinical data fine-tuning, the xLPLM NLLB tends to lose its advantage over smaller-sized Marian on two sub-tasks (clinical terms and ontology concepts) using ClinSpEn offered metrics METEOR, COMET, and ROUGE-L, and totally lost to Marian on Task-1 (clinical cases) on all official metrics including SacreBLEU and BLEU; 3) metrics do not always agree with each other on the same tasks using the same model outputs.
CushLEPOR: Customised hLEPOR Metric Using LABSE Distilled Knowledge Model to Improve Agreement with Human Judgements
Aug 30, 2021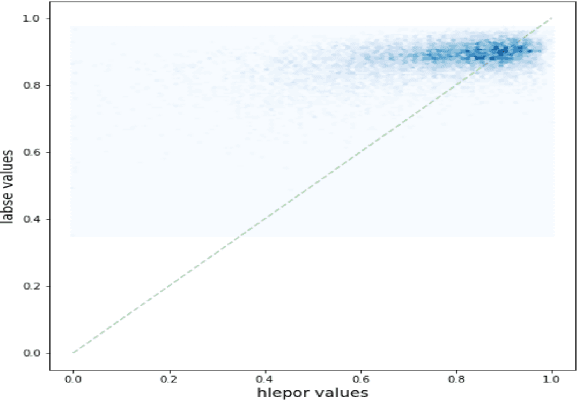
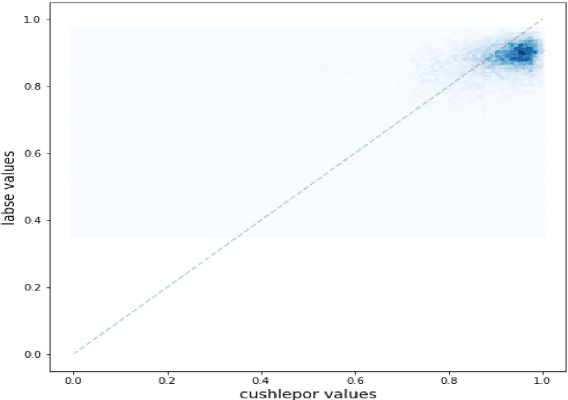
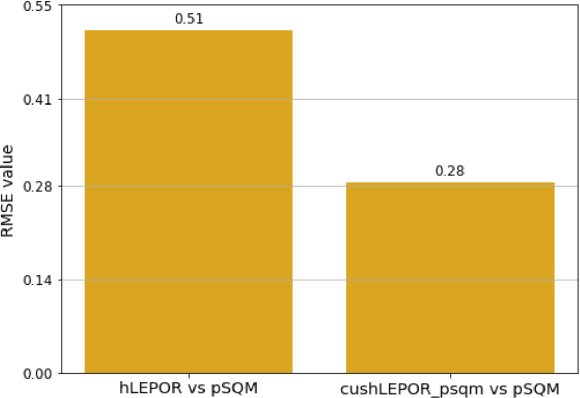
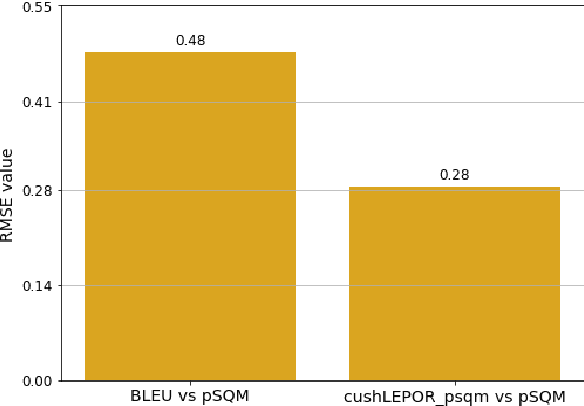
Human evaluation has always been expensive while researchers struggle to trust the automatic metrics. To address this, we propose to customise traditional metrics by taking advantages of the pre-trained language models (PLMs) and the limited available human labelled scores. We first re-introduce the hLEPOR metric factors, followed by the Python portable version we developed which achieved the automatic tuning of the weighting parameters in hLEPOR metric. Then we present the customised hLEPOR (cushLEPOR) which uses LABSE distilled knowledge model to improve the metric agreement with human judgements by automatically optimised factor weights regarding the exact MT language pairs that cushLEPOR is deployed to. We also optimise cushLEPOR towards human evaluation data based on MQM and pSQM framework on English-German and Chinese-English language pairs. The experimental investigations show cushLEPOR boosts hLEPOR performances towards better agreements to PLMs like LABSE with much lower cost, and better agreements to human evaluations including MQM and pSQM scores, and yields much better performances than BLEU (data available at \url{https://github.com/poethan/cushLEPOR}).