 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExamining Large Pre-Trained Language Models for Machine Translation: What You Don't Know About It
Paper and Code
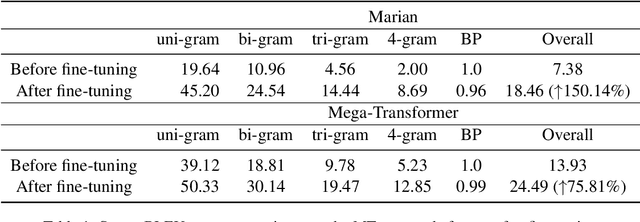
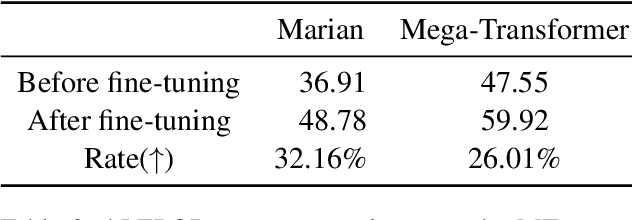

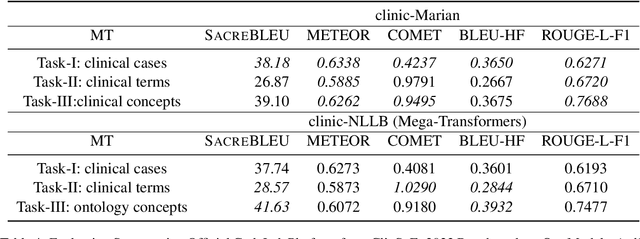
Pre-trained language models (PLMs) often take advantage of the monolingual and multilingual dataset that is freely available online to acquire general or mixed domain knowledge before deployment into specific tasks. Extra-large PLMs (xLPLMs) are proposed very recently to claim supreme performances over smaller-sized PLMs such as in machine translation (MT) tasks. These xLPLMs include Meta-AI's wmt21-dense-24-wide-en-X (2021) and NLLB (2022). In this work, we examine if xLPLMs are absolutely superior to smaller-sized PLMs in fine-tuning toward domain-specific MTs. We use two different in-domain data of different sizes: commercial automotive in-house data and clinical shared task data from the ClinSpEn2022 challenge at WMT2022. We choose popular Marian Helsinki as smaller sized PLM and two massive-sized Mega-Transformers from Meta-AI as xLPLMs. Our experimental investigation shows that 1) on smaller sized in-domain commercial automotive data, xLPLM wmt21-dense-24-wide-en-X indeed shows much better evaluation scores using SacreBLEU and hLEPOR metrics than smaller-sized Marian, even though its score increase rate is lower than Marian after fine-tuning; 2) on relatively larger-size well prepared clinical data fine-tuning, the xLPLM NLLB tends to lose its advantage over smaller-sized Marian on two sub-tasks (clinical terms and ontology concepts) using ClinSpEn offered metrics METEOR, COMET, and ROUGE-L, and totally lost to Marian on Task-1 (clinical cases) on all official metrics including SacreBLEU and BLEU; 3) metrics do not always agree with each other on the same tasks using the same model outputs.