 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCushLEPOR: Customised hLEPOR Metric Using LABSE Distilled Knowledge Model to Improve Agreement with Human Judgements
Paper and Code
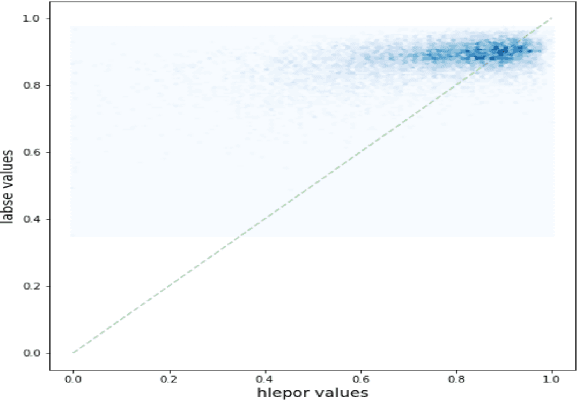
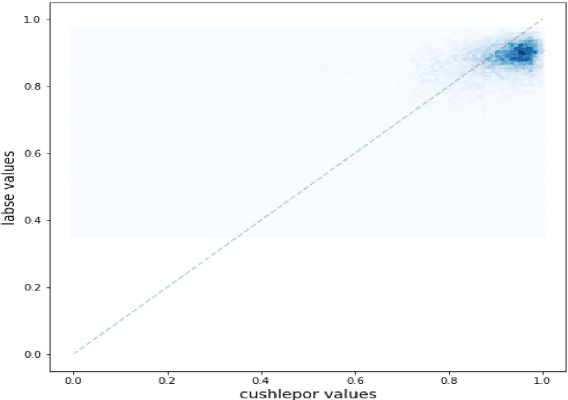
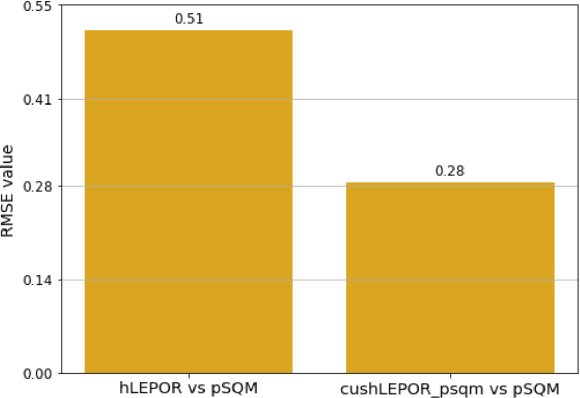
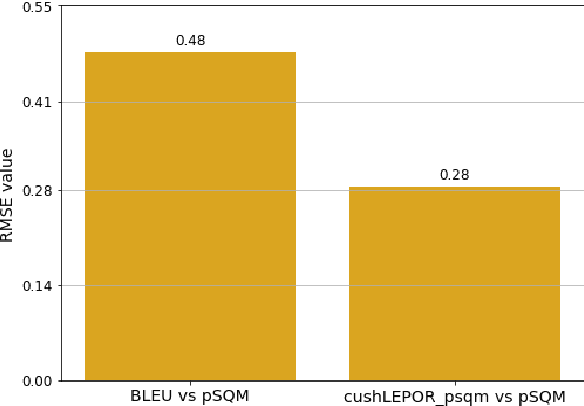
Human evaluation has always been expensive while researchers struggle to trust the automatic metrics. To address this, we propose to customise traditional metrics by taking advantages of the pre-trained language models (PLMs) and the limited available human labelled scores. We first re-introduce the hLEPOR metric factors, followed by the Python portable version we developed which achieved the automatic tuning of the weighting parameters in hLEPOR metric. Then we present the customised hLEPOR (cushLEPOR) which uses LABSE distilled knowledge model to improve the metric agreement with human judgements by automatically optimised factor weights regarding the exact MT language pairs that cushLEPOR is deployed to. We also optimise cushLEPOR towards human evaluation data based on MQM and pSQM framework on English-German and Chinese-English language pairs. The experimental investigations show cushLEPOR boosts hLEPOR performances towards better agreements to PLMs like LABSE with much lower cost, and better agreements to human evaluations including MQM and pSQM scores, and yields much better performances than BLEU (data available at \url{https://github.com/poethan/cushLEPOR}).