 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUNITER: Learning UNiversal Image-TExt Representations
Sep 25, 2019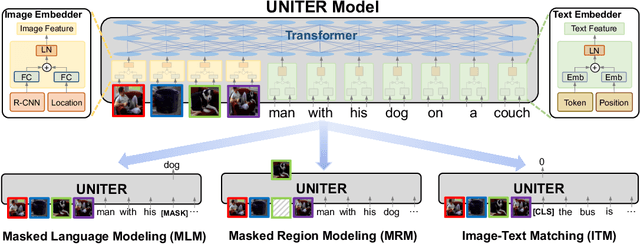

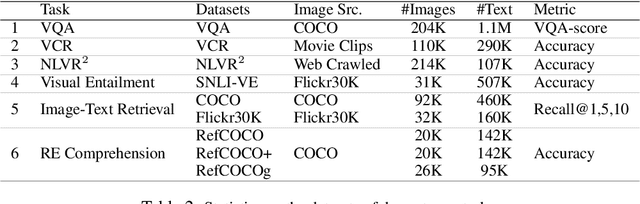
Joint image-text embedding is the bedrock for most Vision-and-Language (V+L) tasks, where multimodality inputs are jointly processed for visual and textual understanding. In this paper, we introduce UNITER, a UNiversal Image-TExt Representation, learned through large-scale pre-training over four image-text datasets (COCO, Visual Genome, Conceptual Captions, and SBU Captions), which can power heterogeneous downstream V+L tasks with joint multimodal embeddings. We design three pre-training tasks: Masked Language Modeling (MLM), Image-Text Matching (ITM), and Masked Region Modeling (MRM, with three variants). Different from concurrent work on multimodal pre-training that apply joint random masking to both modalities, we use conditioned masking on pre-training tasks (i.e., masked language/region modeling is conditioned on full observation of image/text). Comprehensive analysis shows that conditioned masking yields better performance than unconditioned masking. We also conduct a thorough ablation study to find an optimal setting for the combination of pre-training tasks. Extensive experiments show that UNITER achieves new state of the art across six V+L tasks (over nine datasets), including Visual Question Answering, Image-Text Retrieval, Referring Expression Comprehension, Visual Commonsense Reasoning, Visual Entailment, and NLVR2.
Morphological Constraints for Phrase Pivot Statistical Machine Translation
Sep 12, 2016


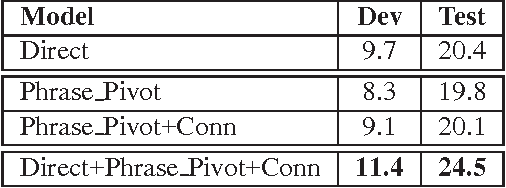
The lack of parallel data for many language pairs is an important challenge to statistical machine translation (SMT). One common solution is to pivot through a third language for which there exist parallel corpora with the source and target languages. Although pivoting is a robust technique, it introduces some low quality translations especially when a poor morphology language is used as the pivot between rich morphology languages. In this paper, we examine the use of synchronous morphology constraint features to improve the quality of phrase pivot SMT. We compare hand-crafted constraints to those learned from limited parallel data between source and target languages. The learned morphology constraints are based on projected align- ments between the source and target phrases in the pivot phrase table. We show positive results on Hebrew-Arabic SMT (pivoting on English). We get 1.5 BLEU points over a phrase pivot baseline and 0.8 BLEU points over a system combination baseline with a direct model built from parallel data.
* 13 pages; Proceedings of MT Summit XV, vol.1: MT Researchers' Track; Miami, Oct 30 - Nov 3, 2015
Egyptian Arabic to English Statistical Machine Translation System for NIST OpenMT'2015
Jun 18, 2016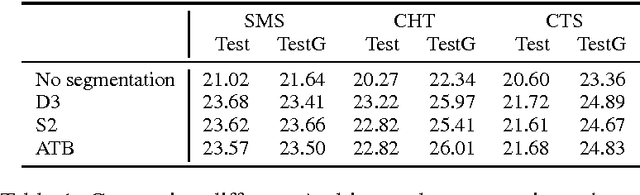



The paper describes the Egyptian Arabic-to-English statistical machine translation (SMT) system that the QCRI-Columbia-NYUAD (QCN) group submitted to the NIST OpenMT'2015 competition. The competition focused on informal dialectal Arabic, as used in SMS, chat, and speech. Thus, our efforts focused on processing and standardizing Arabic, e.g., using tools such as 3arrib and MADAMIRA. We further trained a phrase-based SMT system using state-of-the-art features and components such as operation sequence model, class-based language model, sparse features, neural network joint model, genre-based hierarchically-interpolated language model, unsupervised transliteration mining, phrase-table merging, and hypothesis combination. Our system ranked second on all three genres.