 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUncertainty in Language Models: Assessment through Rank-Calibration
Paper and Code
Apr 04, 2024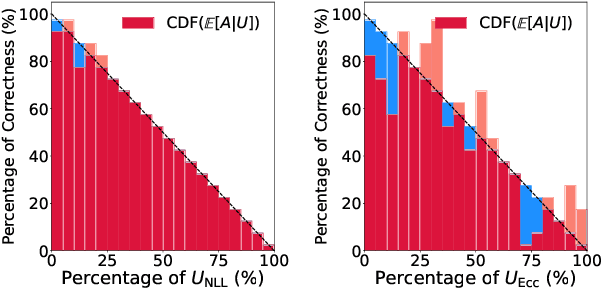

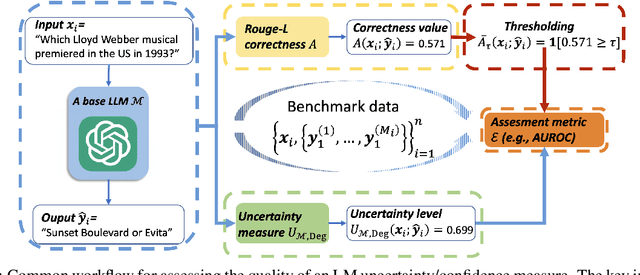
Language Models (LMs) have shown promising performance in natural language generation. However, as LMs often generate incorrect or hallucinated responses, it is crucial to correctly quantify their uncertainty in responding to given inputs. In addition to verbalized confidence elicited via prompting, many uncertainty measures ($e.g.$, semantic entropy and affinity-graph-based measures) have been proposed. However, these measures can differ greatly, and it is unclear how to compare them, partly because they take values over different ranges ($e.g.$, $[0,\infty)$ or $[0,1]$). In this work, we address this issue by developing a novel and practical framework, termed $Rank$-$Calibration$, to assess uncertainty and confidence measures for LMs. Our key tenet is that higher uncertainty (or lower confidence) should imply lower generation quality, on average. Rank-calibration quantifies deviations from this ideal relationship in a principled manner, without requiring ad hoc binary thresholding of the correctness score ($e.g.$, ROUGE or METEOR). The broad applicability and the granular interpretability of our methods are demonstrated empirically.