 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransfer Attacks and Defenses for Large Language Models on Coding Tasks
Paper and Code
Nov 22, 2023


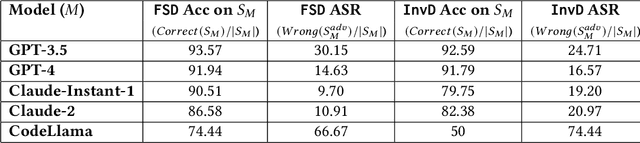
Modern large language models (LLMs), such as ChatGPT, have demonstrated impressive capabilities for coding tasks including writing and reasoning about code. They improve upon previous neural network models of code, such as code2seq or seq2seq, that already demonstrated competitive results when performing tasks such as code summarization and identifying code vulnerabilities. However, these previous code models were shown vulnerable to adversarial examples, i.e. small syntactic perturbations that do not change the program's semantics, such as the inclusion of "dead code" through false conditions or the addition of inconsequential print statements, designed to "fool" the models. LLMs can also be vulnerable to the same adversarial perturbations but a detailed study on this concern has been lacking so far. In this paper we aim to investigate the effect of adversarial perturbations on coding tasks with LLMs. In particular, we study the transferability of adversarial examples, generated through white-box attacks on smaller code models, to LLMs. Furthermore, to make the LLMs more robust against such adversaries without incurring the cost of retraining, we propose prompt-based defenses that involve modifying the prompt to include additional information such as examples of adversarially perturbed code and explicit instructions for reversing adversarial perturbations. Our experiments show that adversarial examples obtained with a smaller code model are indeed transferable, weakening the LLMs' performance. The proposed defenses show promise in improving the model's resilience, paving the way to more robust defensive solutions for LLMs in code-related applications.