 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBhashaVerse : Translation Ecosystem for Indian Subcontinent Languages
Dec 05, 2024This paper focuses on developing translation models and related applications for 36 Indian languages, including Assamese, Awadhi, Bengali, Bhojpuri, Braj, Bodo, Dogri, English, Konkani, Gondi, Gujarati, Hindi, Hinglish, Ho, Kannada, Kangri, Kashmiri (Arabic and Devanagari), Khasi, Mizo, Magahi, Maithili, Malayalam, Marathi, Manipuri (Bengali and Meitei), Nepali, Oriya, Punjabi, Sanskrit, Santali, Sinhala, Sindhi (Arabic and Devanagari), Tamil, Tulu, Telugu, and Urdu. Achieving this requires parallel and other types of corpora for all 36 * 36 language pairs, addressing challenges like script variations, phonetic differences, and syntactic diversity. For instance, languages like Kashmiri and Sindhi, which use multiple scripts, demand script normalization for alignment, while low-resource languages such as Khasi and Santali require synthetic data augmentation to ensure sufficient coverage and quality. To address these challenges, this work proposes strategies for corpus creation by leveraging existing resources, developing parallel datasets, generating domain-specific corpora, and utilizing synthetic data techniques. Additionally, it evaluates machine translation across various dimensions, including standard and discourse-level translation, domain-specific translation, reference-based and reference-free evaluation, error analysis, and automatic post-editing. By integrating these elements, the study establishes a comprehensive framework to improve machine translation quality and enable better cross-lingual communication in India's linguistically diverse ecosystem.
Fine-tuning Pre-trained Named Entity Recognition Models For Indian Languages
May 08, 2024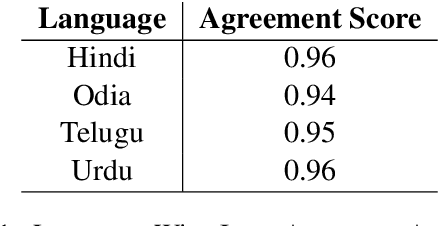
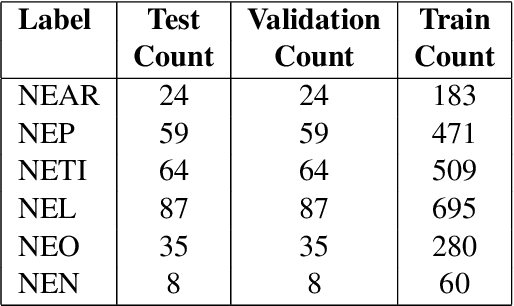
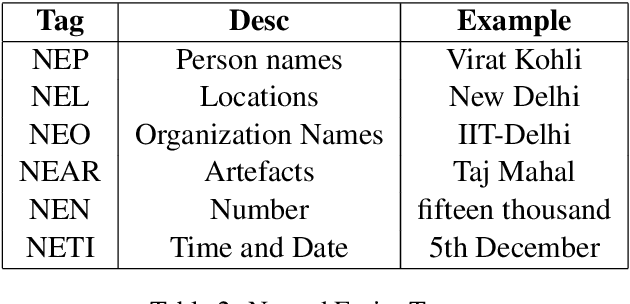
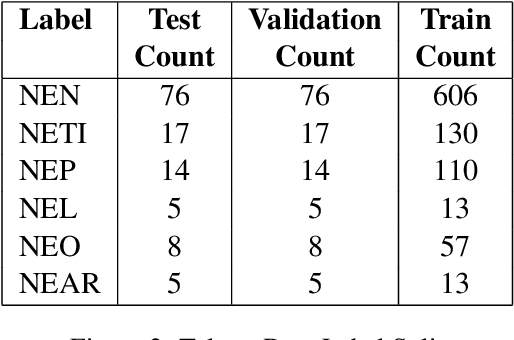
Named Entity Recognition (NER) is a useful component in Natural Language Processing (NLP) applications. It is used in various tasks such as Machine Translation, Summarization, Information Retrieval, and Question-Answering systems. The research on NER is centered around English and some other major languages, whereas limited attention has been given to Indian languages. We analyze the challenges and propose techniques that can be tailored for Multilingual Named Entity Recognition for Indian Languages. We present a human annotated named entity corpora of 40K sentences for 4 Indian languages from two of the major Indian language families. Additionally,we present a multilingual model fine-tuned on our dataset, which achieves an F1 score of 0.80 on our dataset on average. We achieve comparable performance on completely unseen benchmark datasets for Indian languages which affirms the usability of our model.
Towards Large Language Model driven Reference-less Translation Evaluation for English and Indian Languages
Apr 03, 2024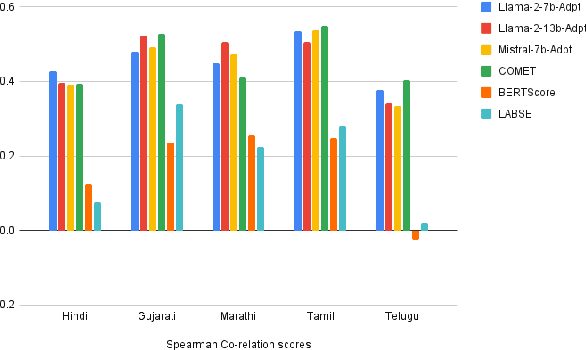
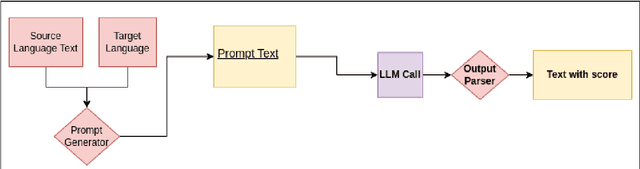
With the primary focus on evaluating the effectiveness of large language models for automatic reference-less translation assessment, this work presents our experiments on mimicking human direct assessment to evaluate the quality of translations in English and Indian languages. We constructed a translation evaluation task where we performed zero-shot learning, in-context example-driven learning, and fine-tuning of large language models to provide a score out of 100, where 100 represents a perfect translation and 1 represents a poor translation. We compared the performance of our trained systems with existing methods such as COMET, BERT-Scorer, and LABSE, and found that the LLM-based evaluator (LLaMA-2-13B) achieves a comparable or higher overall correlation with human judgments for the considered Indian language pairs.
Automatic Data Retrieval for Cross Lingual Summarization
Dec 22, 2023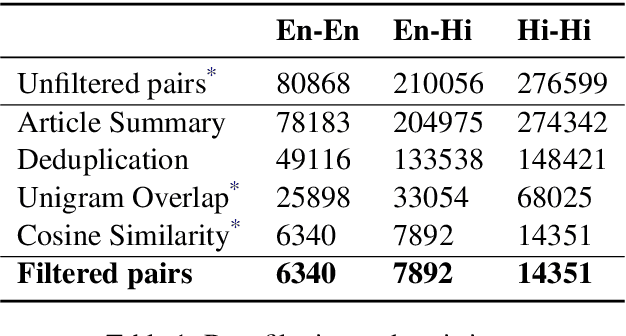
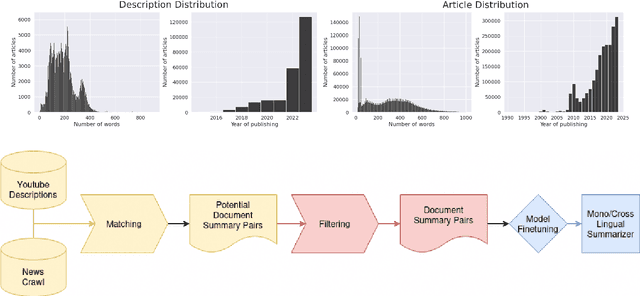
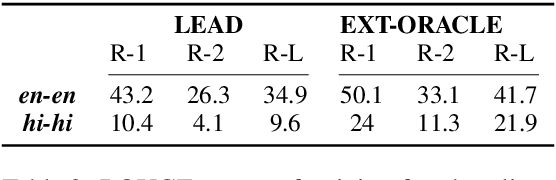
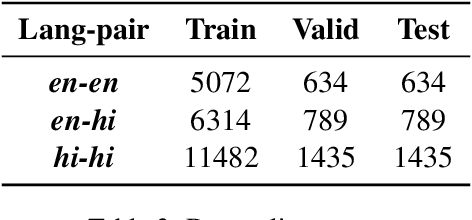
Cross-lingual summarization involves the summarization of text written in one language to a different one. There is a body of research addressing cross-lingual summarization from English to other European languages. In this work, we aim to perform cross-lingual summarization from English to Hindi. We propose pairing up the coverage of newsworthy events in textual and video format can prove to be helpful for data acquisition for cross lingual summarization. We analyze the data and propose methods to match articles to video descriptions that serve as document and summary pairs. We also outline filtering methods over reasonable thresholds to ensure the correctness of the summaries. Further, we make available 28,583 mono and cross-lingual article-summary pairs https://github.com/tingc9/Cross-Sum-News-Aligned. We also build and analyze multiple baselines on the collected data and report error analysis.
Verb Categorisation for Hindi Word Problem Solving
Dec 18, 2023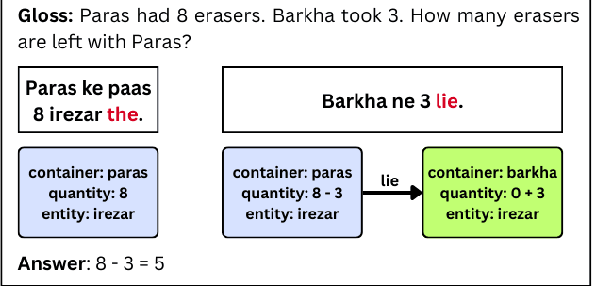



Word problem Solving is a challenging NLP task that deals with solving mathematical problems described in natural language. Recently, there has been renewed interest in developing word problem solvers for Indian languages. As part of this paper, we have built a Hindi arithmetic word problem solver which makes use of verbs. Additionally, we have created verb categorization data for Hindi. Verbs are very important for solving word problems with addition/subtraction operations as they help us identify the set of operations required to solve the word problems. We propose a rule-based solver that uses verb categorisation to identify operations in a word problem and generate answers for it. To perform verb categorisation, we explore several approaches and present a comparative study.
Assessing Translation capabilities of Large Language Models involving English and Indian Languages
Nov 15, 2023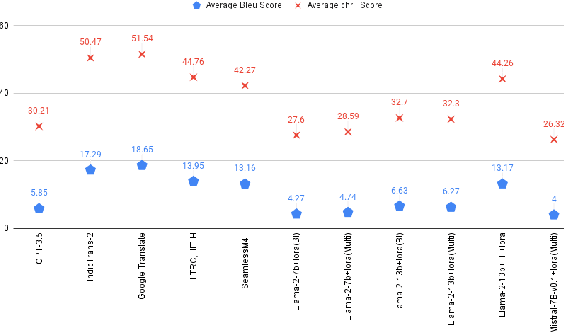

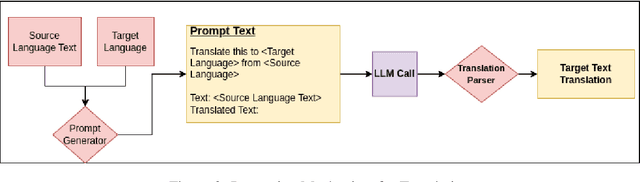
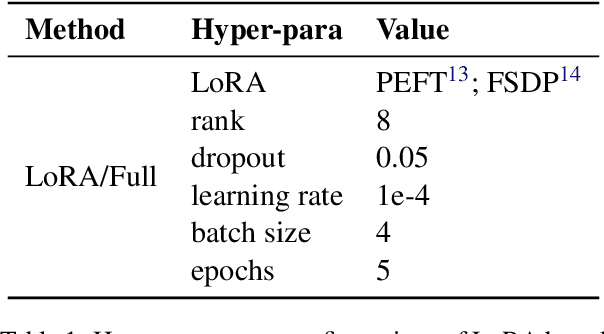
Generative Large Language Models (LLMs) have achieved remarkable advancements in various NLP tasks. In this work, our aim is to explore the multilingual capabilities of large language models by using machine translation as a task involving English and 22 Indian languages. We first investigate the translation capabilities of raw large language models, followed by exploring the in-context learning capabilities of the same raw models. We fine-tune these large language models using parameter efficient fine-tuning methods such as LoRA and additionally with full fine-tuning. Through our study, we have identified the best performing large language model for the translation task involving LLMs, which is based on LLaMA. Our results demonstrate significant progress, with average BLEU scores of 13.42, 15.93, 12.13, 12.30, and 12.07, as well as CHRF scores of 43.98, 46.99, 42.55, 42.42, and 45.39, respectively, using 2-stage fine-tuned LLaMA-13b for English to Indian languages on IN22 (conversational), IN22 (general), flores200-dev, flores200-devtest, and newstest2019 testsets. Similarly, for Indian languages to English, we achieved average BLEU scores of 14.03, 16.65, 16.17, 15.35 and 12.55 along with chrF scores of 36.71, 40.44, 40.26, 39.51, and 36.20, respectively, using fine-tuned LLaMA-13b on IN22 (conversational), IN22 (general), flores200-dev, flores200-devtest, and newstest2019 testsets. Overall, our findings highlight the potential and strength of large language models for machine translation capabilities, including for languages that are currently underrepresented in LLMs.
Building Odia Shallow Parser
Apr 19, 2022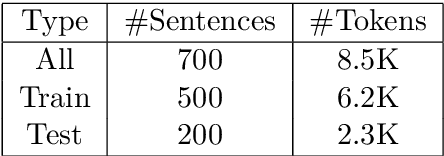
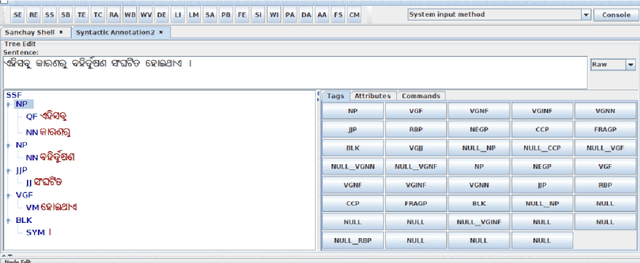

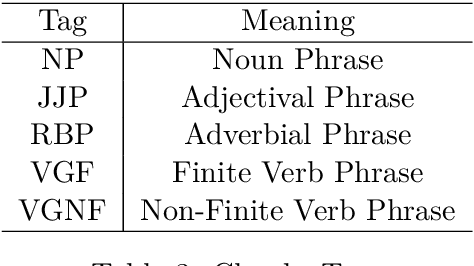
Shallow parsing is an essential task for many NLP applications like machine translation, summarization, sentiment analysis, aspect identification and many more. Quality annotated corpora is critical for building accurate shallow parsers. Many Indian languages are resource poor with respect to the availability of corpora in general. So, this paper is an attempt towards creating quality corpora for shallow parsers. The contribution of this paper is two folds: creation pos and chunk annotated corpora for Odia and development of baseline systems for pos tagging and chunking in Odia.
Assessing Post-editing Effort in the English-Hindi Direction
Dec 18, 2021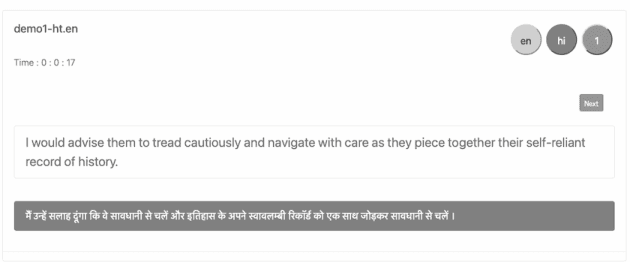
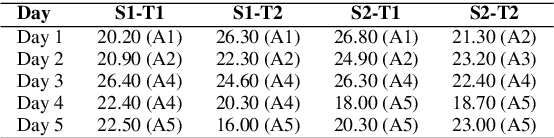
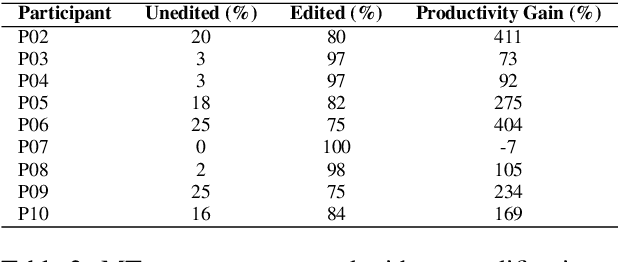
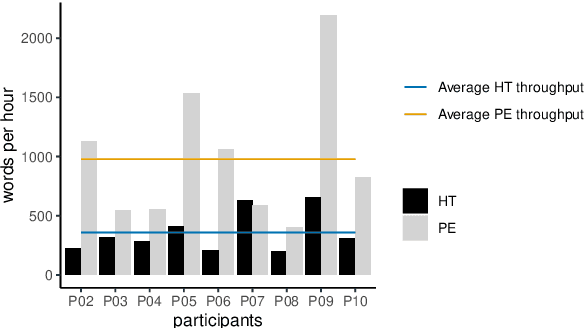
We present findings from a first in-depth post-editing effort estimation study in the English-Hindi direction along multiple effort indicators. We conduct a controlled experiment involving professional translators, who complete assigned tasks alternately, in a translation from scratch and a post-edit condition. We find that post-editing reduces translation time (by 63%), utilizes fewer keystrokes (by 59%), and decreases the number of pauses (by 63%) when compared to translating from scratch. We further verify the quality of translations thus produced via a human evaluation task in which we do not detect any discernible quality differences.
Sample-efficient Linguistic Generalizations through Program Synthesis: Experiments with Phonology Problems
Jun 11, 2021

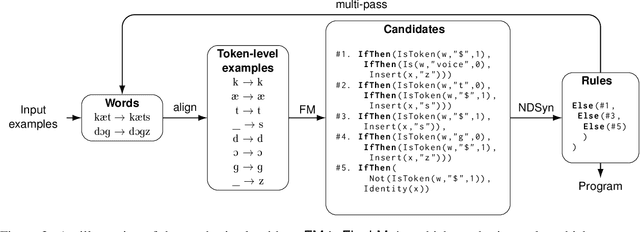

Neural models excel at extracting statistical patterns from large amounts of data, but struggle to learn patterns or reason about language from only a few examples. In this paper, we ask: Can we learn explicit rules that generalize well from only a few examples? We explore this question using program synthesis. We develop a synthesis model to learn phonology rules as programs in a domain-specific language. We test the ability of our models to generalize from few training examples using our new dataset of problems from the Linguistics Olympiad, a challenging set of tasks that require strong linguistic reasoning ability. In addition to being highly sample-efficient, our approach generates human-readable programs, and allows control over the generalizability of the learnt programs.
Leveraging Newswire Treebanks for Parsing Conversational Data with Argument Scrambling
Feb 13, 2019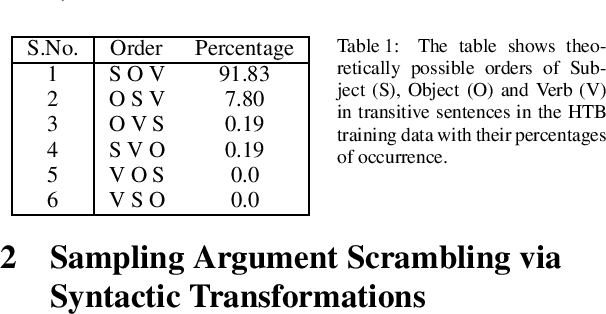
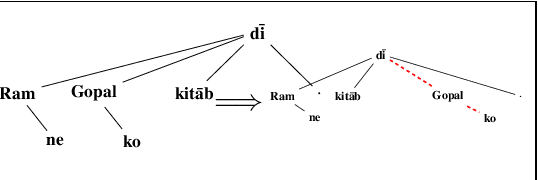
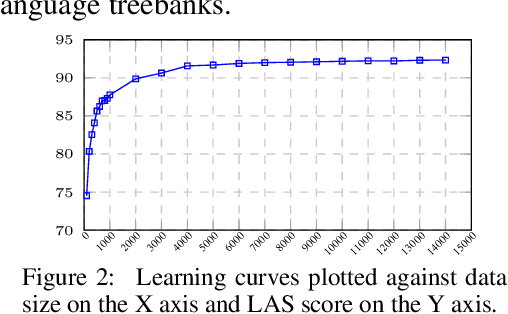
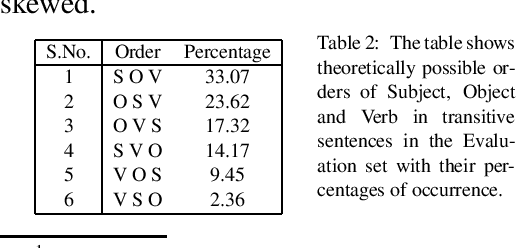
We investigate the problem of parsing conversational data of morphologically-rich languages such as Hindi where argument scrambling occurs frequently. We evaluate a state-of-the-art non-linear transition-based parsing system on a new dataset containing 506 dependency trees for sentences from Bollywood (Hindi) movie scripts and Twitter posts of Hindi monolingual speakers. We show that a dependency parser trained on a newswire treebank is strongly biased towards the canonical structures and degrades when applied to conversational data. Inspired by Transformational Generative Grammar, we mitigate the sampling bias by generating all theoretically possible alternative word orders of a clause from the existing (kernel) structures in the treebank. Training our parser on canonical and transformed structures improves performance on conversational data by around 9% LAS over the baseline newswire parser.
* Proceedings of the 15th International Conference on Parsing Technologies, pages 61-66, Pisa, Italy; September 20-22, 2017. Association for Computational Linguistics