 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging Newswire Treebanks for Parsing Conversational Data with Argument Scrambling
Feb 13, 2019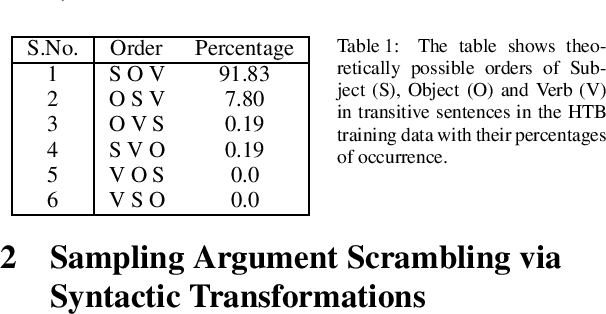
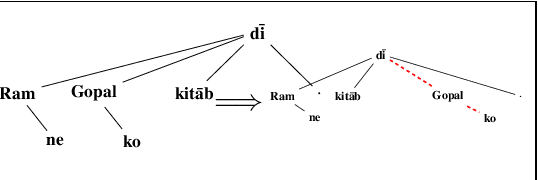
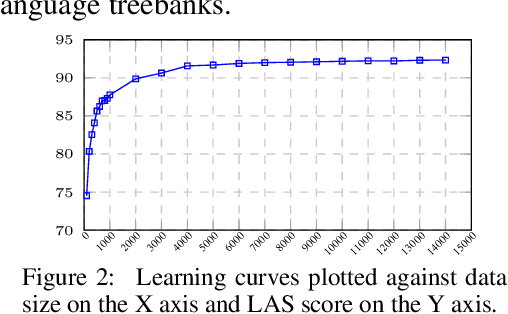
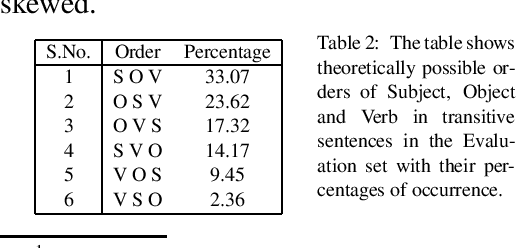
We investigate the problem of parsing conversational data of morphologically-rich languages such as Hindi where argument scrambling occurs frequently. We evaluate a state-of-the-art non-linear transition-based parsing system on a new dataset containing 506 dependency trees for sentences from Bollywood (Hindi) movie scripts and Twitter posts of Hindi monolingual speakers. We show that a dependency parser trained on a newswire treebank is strongly biased towards the canonical structures and degrades when applied to conversational data. Inspired by Transformational Generative Grammar, we mitigate the sampling bias by generating all theoretically possible alternative word orders of a clause from the existing (kernel) structures in the treebank. Training our parser on canonical and transformed structures improves performance on conversational data by around 9% LAS over the baseline newswire parser.
* Proceedings of the 15th International Conference on Parsing Technologies, pages 61-66, Pisa, Italy; September 20-22, 2017. Association for Computational Linguistics
Universal Dependency Parsing for Hindi-English Code-switching
Apr 24, 2018

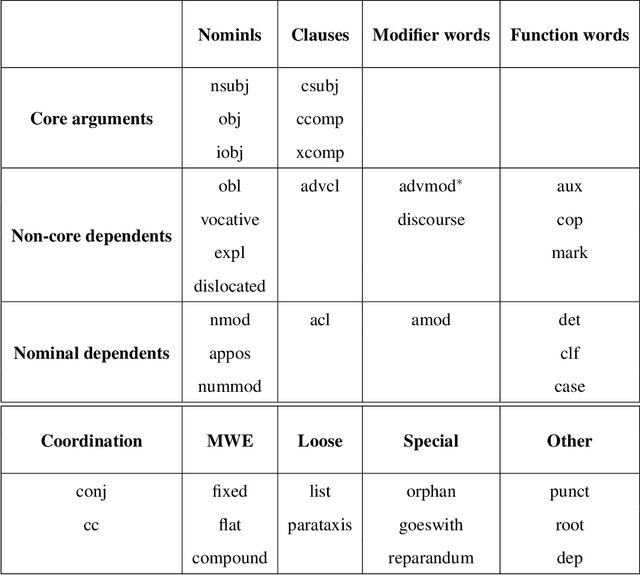

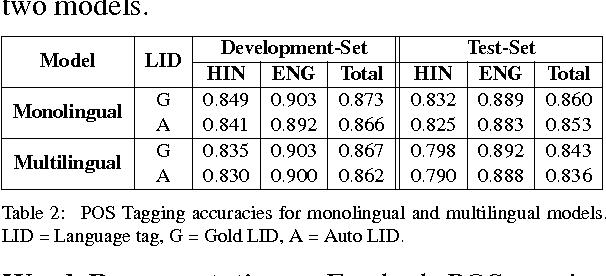
Code-switching is a phenomenon of mixing grammatical structures of two or more languages under varied social constraints. The code-switching data differ so radically from the benchmark corpora used in NLP community that the application of standard technologies to these data degrades their performance sharply. Unlike standard corpora, these data often need to go through additional processes such as language identification, normalization and/or back-transliteration for their efficient processing. In this paper, we investigate these indispensable processes and other problems associated with syntactic parsing of code-switching data and propose methods to mitigate their effects. In particular, we study dependency parsing of code-switching data of Hindi and English multilingual speakers from Twitter. We present a treebank of Hindi-English code-switching tweets under Universal Dependencies scheme and propose a neural stacking model for parsing that efficiently leverages part-of-speech tag and syntactic tree annotations in the code-switching treebank and the preexisting Hindi and English treebanks. We also present normalization and back-transliteration models with a decoding process tailored for code-switching data. Results show that our neural stacking parser is 1.5% LAS points better than the augmented parsing model and our decoding process improves results by 3.8% LAS points over the first-best normalization and/or back-transliteration.
Joining Hands: Exploiting Monolingual Treebanks for Parsing of Code-mixing Data
Mar 31, 2017

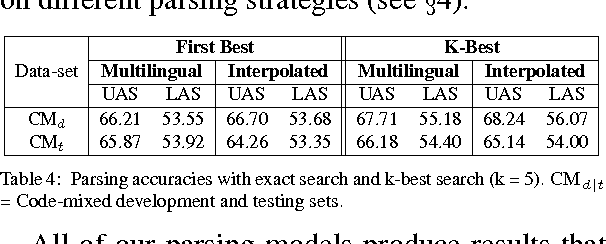
In this paper, we propose efficient and less resource-intensive strategies for parsing of code-mixed data. These strategies are not constrained by in-domain annotations, rather they leverage pre-existing monolingual annotated resources for training. We show that these methods can produce significantly better results as compared to an informed baseline. Besides, we also present a data set of 450 Hindi and English code-mixed tweets of Hindi multilingual speakers for evaluation. The data set is manually annotated with Universal Dependencies.