 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Large Language Model driven Reference-less Translation Evaluation for English and Indian Languages
Apr 03, 2024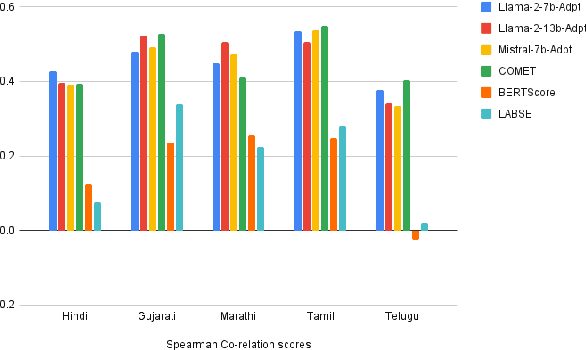
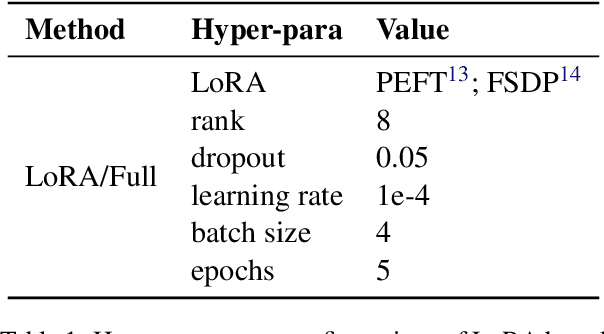
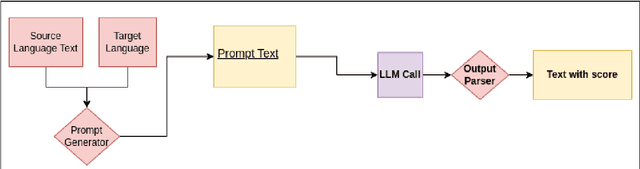
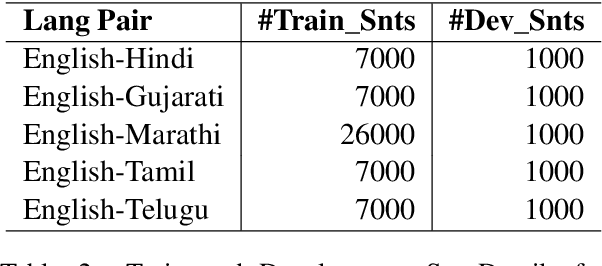
With the primary focus on evaluating the effectiveness of large language models for automatic reference-less translation assessment, this work presents our experiments on mimicking human direct assessment to evaluate the quality of translations in English and Indian languages. We constructed a translation evaluation task where we performed zero-shot learning, in-context example-driven learning, and fine-tuning of large language models to provide a score out of 100, where 100 represents a perfect translation and 1 represents a poor translation. We compared the performance of our trained systems with existing methods such as COMET, BERT-Scorer, and LABSE, and found that the LLM-based evaluator (LLaMA-2-13B) achieves a comparable or higher overall correlation with human judgments for the considered Indian language pairs.
Assessing Post-editing Effort in the English-Hindi Direction
Dec 18, 2021
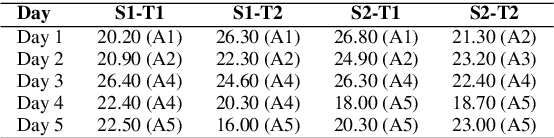
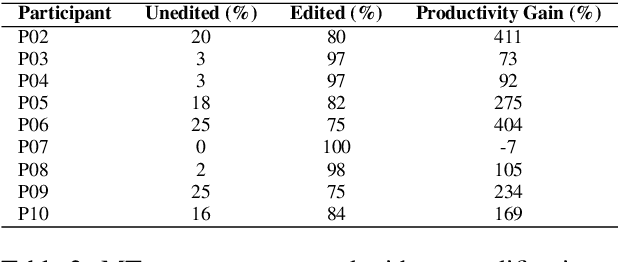
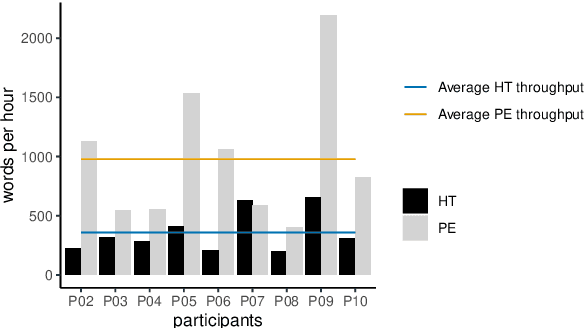
We present findings from a first in-depth post-editing effort estimation study in the English-Hindi direction along multiple effort indicators. We conduct a controlled experiment involving professional translators, who complete assigned tasks alternately, in a translation from scratch and a post-edit condition. We find that post-editing reduces translation time (by 63%), utilizes fewer keystrokes (by 59%), and decreases the number of pauses (by 63%) when compared to translating from scratch. We further verify the quality of translations thus produced via a human evaluation task in which we do not detect any discernible quality differences.