 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShadow Unlearning: A Neuro-Semantic Approach to Fidelity-Preserving Faceless Forgetting in LLMs
Jan 07, 2026Machine unlearning aims to selectively remove the influence of specific training samples to satisfy privacy regulations such as the GDPR's 'Right to be Forgotten'. However, many existing methods require access to the data being removed, exposing it to membership inference attacks and potential misuse of Personally Identifiable Information (PII). We address this critical challenge by proposing Shadow Unlearning, a novel paradigm of approximate unlearning, that performs machine unlearning on anonymized forget data without exposing PII. We further propose a novel privacy-preserving framework, Neuro-Semantic Projector Unlearning (NSPU) to achieve Shadow unlearning. To evaluate our method, we compile Multi-domain Fictitious Unlearning (MuFU) forget set across five diverse domains and introduce an evaluation stack to quantify the trade-off between knowledge retention and unlearning effectiveness. Experimental results on various LLMs show that NSPU achieves superior unlearning performance, preserves model utility, and enhances user privacy. Additionally, the proposed approach is at least 10 times more computationally efficient than standard unlearning approaches. Our findings foster a new direction for privacy-aware machine unlearning that balances data protection and model fidelity.
AGIC: Attention-Guided Image Captioning to Improve Caption Relevance
Aug 09, 2025
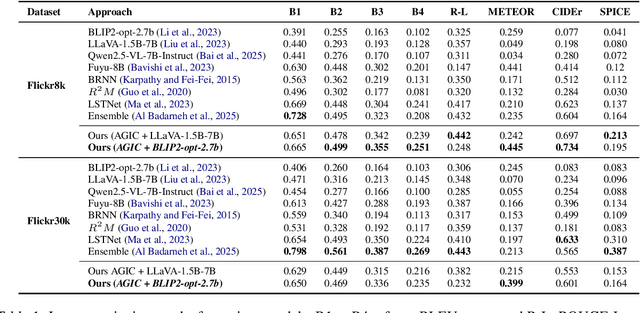
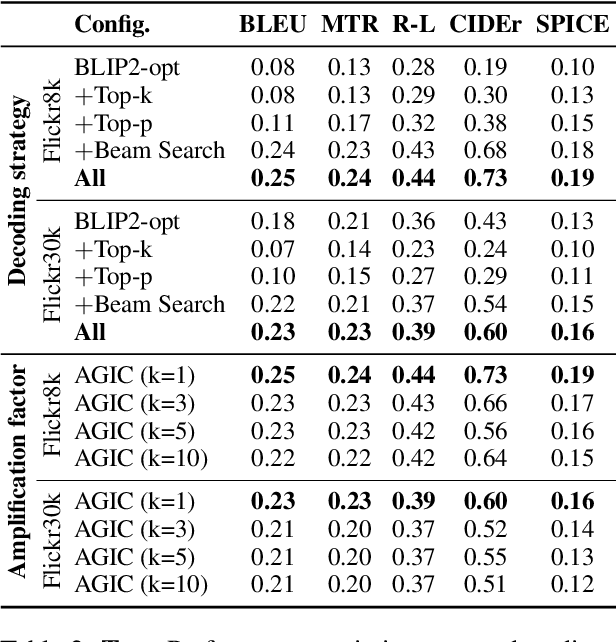
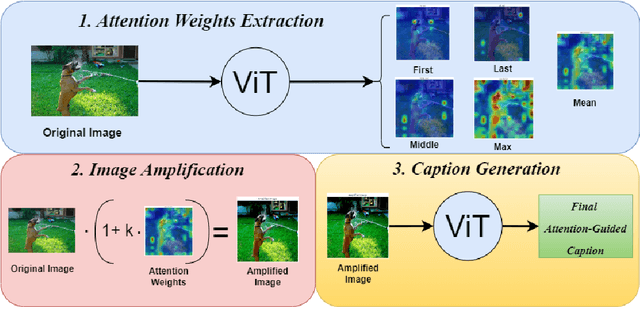
Despite significant progress in image captioning, generating accurate and descriptive captions remains a long-standing challenge. In this study, we propose Attention-Guided Image Captioning (AGIC), which amplifies salient visual regions directly in the feature space to guide caption generation. We further introduce a hybrid decoding strategy that combines deterministic and probabilistic sampling to balance fluency and diversity. To evaluate AGIC, we conduct extensive experiments on the Flickr8k and Flickr30k datasets. The results show that AGIC matches or surpasses several state-of-the-art models while achieving faster inference. Moreover, AGIC demonstrates strong performance across multiple evaluation metrics, offering a scalable and interpretable solution for image captioning.
Agent Ideate: A Framework for Product Idea Generation from Patents Using Agentic AI
Jul 02, 2025Patents contain rich technical knowledge that can inspire innovative product ideas, yet accessing and interpreting this information remains a challenge. This work explores the use of Large Language Models (LLMs) and autonomous agents to mine and generate product concepts from a given patent. In this work, we design Agent Ideate, a framework for automatically generating product-based business ideas from patents. We experimented with open-source LLMs and agent-based architectures across three domains: Computer Science, Natural Language Processing, and Material Chemistry. Evaluation results show that the agentic approach consistently outperformed standalone LLMs in terms of idea quality, relevance, and novelty. These findings suggest that combining LLMs with agentic workflows can significantly enhance the innovation pipeline by unlocking the untapped potential of business idea generation from patent data.
No LLM is Free From Bias: A Comprehensive Study of Bias Evaluation in Large Language models
Mar 15, 2025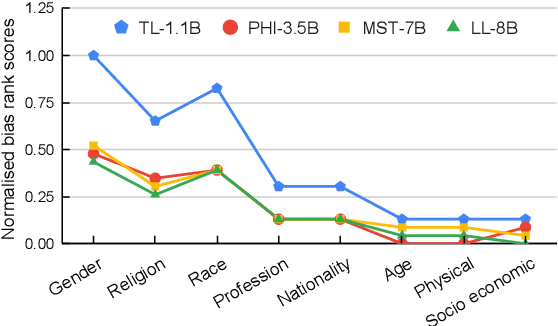
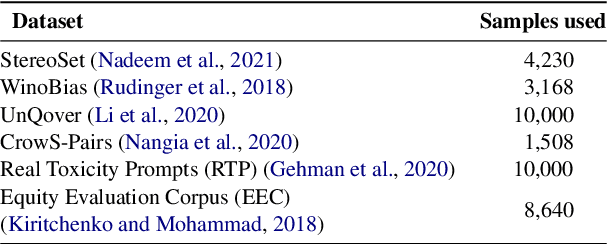
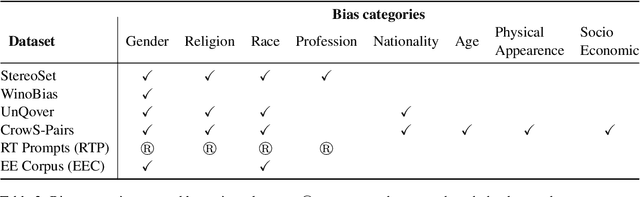

Advancements in Large Language Models (LLMs) have increased the performance of different natural language understanding as well as generation tasks. Although LLMs have breached the state-of-the-art performance in various tasks, they often reflect different forms of bias present in the training data. In the light of this perceived limitation, we provide a unified evaluation of benchmarks using a set of representative LLMs that cover different forms of biases starting from physical characteristics to socio-economic categories. Moreover, we propose five prompting approaches to carry out the bias detection task across different aspects of bias. Further, we formulate three research questions to gain valuable insight in detecting biases in LLMs using different approaches and evaluation metrics across benchmarks. The results indicate that each of the selected LLMs suffer from one or the other form of bias with the LLaMA3.1-8B model being the least biased. Finally, we conclude the paper with the identification of key challenges and possible future directions.
HalluCounter: Reference-free LLM Hallucination Detection in the Wild!
Mar 06, 2025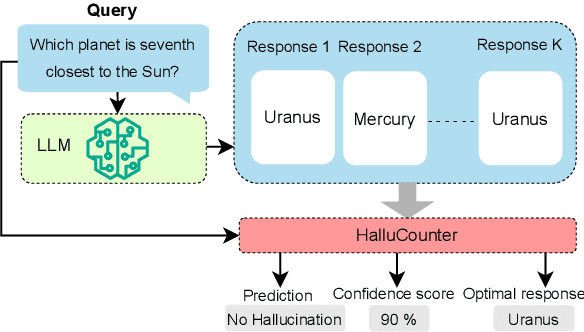

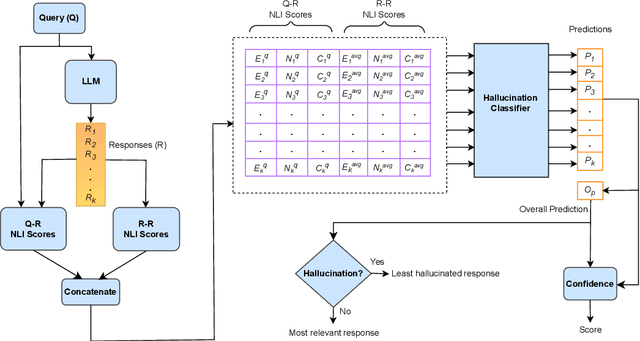
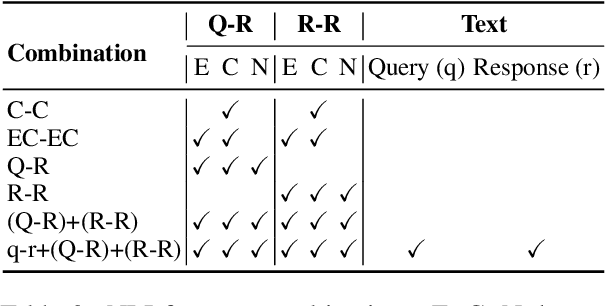
Response consistency-based, reference-free hallucination detection (RFHD) methods do not depend on internal model states, such as generation probabilities or gradients, which Grey-box models typically rely on but are inaccessible in closed-source LLMs. However, their inability to capture query-response alignment patterns often results in lower detection accuracy. Additionally, the lack of large-scale benchmark datasets spanning diverse domains remains a challenge, as most existing datasets are limited in size and scope. To this end, we propose HalluCounter, a novel reference-free hallucination detection method that utilizes both response-response and query-response consistency and alignment patterns. This enables the training of a classifier that detects hallucinations and provides a confidence score and an optimal response for user queries. Furthermore, we introduce HalluCounterEval, a benchmark dataset comprising both synthetically generated and human-curated samples across multiple domains. Our method outperforms state-of-the-art approaches by a significant margin, achieving over 90\% average confidence in hallucination detection across datasets.
No Size Fits All: The Perils and Pitfalls of Leveraging LLMs Vary with Company Size
Jul 21, 2024Large language models (LLMs) are playing a pivotal role in deploying strategic use cases across a range of organizations, from large pan-continental companies to emerging startups. The issues and challenges involved in the successful utilization of LLMs can vary significantly depending on the size of the organization. It is important to study and discuss these pertinent issues of LLM adaptation with a focus on the scale of the industrial concerns and brainstorm possible solutions and prospective directions. Such a study has not been prominently featured in the current research literature. In this study, we adopt a threefold strategy: first, we conduct a case study with industry practitioners to formulate the key research questions; second, we examine existing industrial publications to address these questions; and finally, we provide a practical guide for industries to utilize LLMs more efficiently.
Exploring News Summarization and Enrichment in a Highly Resource-Scarce Indian Language: A Case Study of Mizo
Apr 25, 2024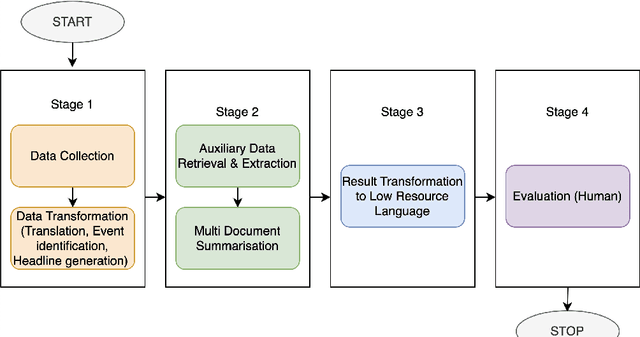



Obtaining sufficient information in one's mother tongue is crucial for satisfying the information needs of the users. While high-resource languages have abundant online resources, the situation is less than ideal for very low-resource languages. Moreover, the insufficient reporting of vital national and international events continues to be a worry, especially in languages with scarce resources, like \textbf{Mizo}. In this paper, we conduct a study to investigate the effectiveness of a simple methodology designed to generate a holistic summary for Mizo news articles, which leverages English-language news to supplement and enhance the information related to the corresponding news events. Furthermore, we make available 500 Mizo news articles and corresponding enriched holistic summaries. Human evaluation confirms that our approach significantly enhances the information coverage of Mizo news articles. The mizo dataset and code can be accessed at \url{https://github.com/barvin04/mizo_enrichment
TrustAI at SemEval-2024 Task 8: A Comprehensive Analysis of Multi-domain Machine Generated Text Detection Techniques
Mar 25, 2024The Large Language Models (LLMs) exhibit remarkable ability to generate fluent content across a wide spectrum of user queries. However, this capability has raised concerns regarding misinformation and personal information leakage. In this paper, we present our methods for the SemEval2024 Task8, aiming to detect machine-generated text across various domains in both mono-lingual and multi-lingual contexts. Our study comprehensively analyzes various methods to detect machine-generated text, including statistical, neural, and pre-trained model approaches. We also detail our experimental setup and perform a in-depth error analysis to evaluate the effectiveness of these methods. Our methods obtain an accuracy of 86.9\% on the test set of subtask-A mono and 83.7\% for subtask-B. Furthermore, we also highlight the challenges and essential factors for consideration in future studies.
LimGen: Probing the LLMs for Generating Suggestive Limitations of Research Papers
Mar 22, 2024



Examining limitations is a crucial step in the scholarly research reviewing process, revealing aspects where a study might lack decisiveness or require enhancement. This aids readers in considering broader implications for further research. In this article, we present a novel and challenging task of Suggestive Limitation Generation (SLG) for research papers. We compile a dataset called LimGen, encompassing 4068 research papers and their associated limitations from the ACL anthology. We investigate several approaches to harness large language models (LLMs) for producing suggestive limitations, by thoroughly examining the related challenges, practical insights, and potential opportunities. Our LimGen dataset and code can be accessed at https://github.com/armbf/LimGen.
LLMs with Industrial Lens: Deciphering the Challenges and Prospects -- A Survey
Feb 22, 2024



Large language models (LLMs) have become the secret ingredient driving numerous industrial applications, showcasing their remarkable versatility across a diverse spectrum of tasks. From natural language processing and sentiment analysis to content generation and personalized recommendations, their unparalleled adaptability has facilitated widespread adoption across industries. This transformative shift driven by LLMs underscores the need to explore the underlying associated challenges and avenues for enhancement in their utilization. In this paper, our objective is to unravel and evaluate the obstacles and opportunities inherent in leveraging LLMs within an industrial context. To this end, we conduct a survey involving a group of industry practitioners, develop four research questions derived from the insights gathered, and examine 68 industry papers to address these questions and derive meaningful conclusions.