 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHHNAS-AM: Hierarchical Hybrid Neural Architecture Search using Adaptive Mutation Policies
Aug 20, 2025Neural Architecture Search (NAS) has garnered significant research interest due to its capability to discover architectures superior to manually designed ones. Learning text representation is crucial for text classification and other language-related tasks. The NAS model used in text classification does not have a Hybrid hierarchical structure, and there is no restriction on the architecture structure, due to which the search space becomes very large and mostly redundant, so the existing RL models are not able to navigate the search space effectively. Also, doing a flat architecture search leads to an unorganised search space, which is difficult to traverse. For this purpose, we propose HHNAS-AM (Hierarchical Hybrid Neural Architecture Search with Adaptive Mutation Policies), a novel approach that efficiently explores diverse architectural configurations. We introduce a few architectural templates to search on which organise the search spaces, where search spaces are designed on the basis of domain-specific cues. Our method employs mutation strategies that dynamically adapt based on performance feedback from previous iterations using Q-learning, enabling a more effective and accelerated traversal of the search space. The proposed model is fully probabilistic, enabling effective exploration of the search space. We evaluate our approach on the database id (db_id) prediction task, where it consistently discovers high-performing architectures across multiple experiments. On the Spider dataset, our method achieves an 8% improvement in test accuracy over existing baselines.
End-to-End Text-to-SQL with Dataset Selection: Leveraging LLMs for Adaptive Query Generation
Aug 08, 2025Text-to-SQL bridges the gap between natural language and structured database language, thus allowing non-technical users to easily query databases. Traditional approaches model text-to-SQL as a direct translation task, where a given Natural Language Query (NLQ) is mapped to an SQL command. Recent advances in large language models (LLMs) have significantly improved translation accuracy, however, these methods all require that the target database is pre-specified. This becomes problematic in scenarios with multiple extensive databases, where identifying the correct database becomes a crucial yet overlooked step. In this paper, we propose a three-stage end-to-end text-to-SQL framework to identify the user's intended database before generating SQL queries. Our approach leverages LLMs and prompt engineering to extract implicit information from natural language queries (NLQs) in the form of a ruleset. We then train a large db\_id prediction model, which includes a RoBERTa-based finetuned encoder, to predict the correct Database identifier (db\_id) based on both the NLQ and the LLM-generated rules. Finally, we refine the generated SQL by using critic agents to correct errors. Experimental results demonstrate that our framework outperforms the current state-of-the-art models in both database intent prediction and SQL generation accuracy.
No Size Fits All: The Perils and Pitfalls of Leveraging LLMs Vary with Company Size
Jul 21, 2024Large language models (LLMs) are playing a pivotal role in deploying strategic use cases across a range of organizations, from large pan-continental companies to emerging startups. The issues and challenges involved in the successful utilization of LLMs can vary significantly depending on the size of the organization. It is important to study and discuss these pertinent issues of LLM adaptation with a focus on the scale of the industrial concerns and brainstorm possible solutions and prospective directions. Such a study has not been prominently featured in the current research literature. In this study, we adopt a threefold strategy: first, we conduct a case study with industry practitioners to formulate the key research questions; second, we examine existing industrial publications to address these questions; and finally, we provide a practical guide for industries to utilize LLMs more efficiently.
TrustAI at SemEval-2024 Task 8: A Comprehensive Analysis of Multi-domain Machine Generated Text Detection Techniques
Mar 25, 2024The Large Language Models (LLMs) exhibit remarkable ability to generate fluent content across a wide spectrum of user queries. However, this capability has raised concerns regarding misinformation and personal information leakage. In this paper, we present our methods for the SemEval2024 Task8, aiming to detect machine-generated text across various domains in both mono-lingual and multi-lingual contexts. Our study comprehensively analyzes various methods to detect machine-generated text, including statistical, neural, and pre-trained model approaches. We also detail our experimental setup and perform a in-depth error analysis to evaluate the effectiveness of these methods. Our methods obtain an accuracy of 86.9\% on the test set of subtask-A mono and 83.7\% for subtask-B. Furthermore, we also highlight the challenges and essential factors for consideration in future studies.
LLMs with Industrial Lens: Deciphering the Challenges and Prospects -- A Survey
Feb 22, 2024



Large language models (LLMs) have become the secret ingredient driving numerous industrial applications, showcasing their remarkable versatility across a diverse spectrum of tasks. From natural language processing and sentiment analysis to content generation and personalized recommendations, their unparalleled adaptability has facilitated widespread adoption across industries. This transformative shift driven by LLMs underscores the need to explore the underlying associated challenges and avenues for enhancement in their utilization. In this paper, our objective is to unravel and evaluate the obstacles and opportunities inherent in leveraging LLMs within an industrial context. To this end, we conduct a survey involving a group of industry practitioners, develop four research questions derived from the insights gathered, and examine 68 industry papers to address these questions and derive meaningful conclusions.
Few Shot Speaker Recognition using Deep Neural Networks
Apr 17, 2019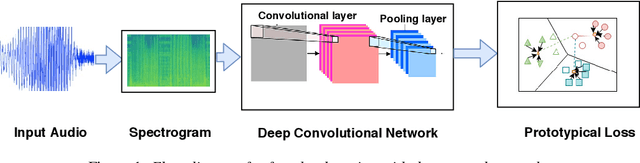
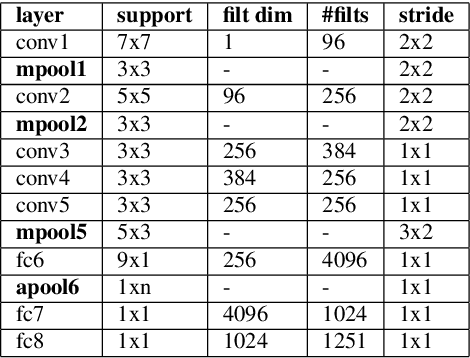

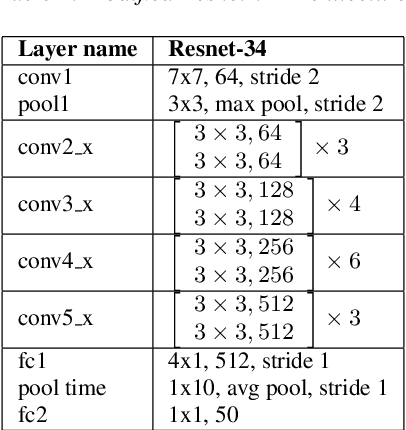
The recent advances in deep learning are mostly driven by availability of large amount of training data. However, availability of such data is not always possible for specific tasks such as speaker recognition where collection of large amount of data is not possible in practical scenarios. Therefore, in this paper, we propose to identify speakers by learning from only a few training examples. To achieve this, we use a deep neural network with prototypical loss where the input to the network is a spectrogram. For output, we project the class feature vectors into a common embedding space, followed by classification. Further, we show the effectiveness of capsule net in a few shot learning setting. To this end, we utilize an auto-encoder to learn generalized feature embeddings from class-specific embeddings obtained from capsule network. We provide exhaustive experiments on publicly available datasets and competitive baselines, demonstrating the superiority and generalization ability of the proposed few shot learning pipelines.
Deep Embedding using Bayesian Risk Minimization with Application to Sketch Recognition
Dec 06, 2018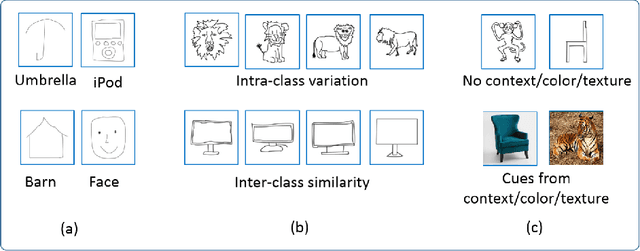



In this paper, we address the problem of hand-drawn sketch recognition. Inspired by the Bayesian decision theory, we present a deep metric learning loss with the objective to minimize the Bayesian risk of misclassification. We estimate this risk for every mini-batch during training, and learn robust deep embeddings by backpropagating it to a deep neural network in an end-to-end trainable paradigm. Our learnt embeddings are discriminative and robust despite of intra-class variations and inter-class similarities naturally present in hand-drawn sketch images. Outperforming the state of the art on sketch recognition, our method achieves 82.2% and 88.7% on TU-Berlin-250 and TU-Berlin-160 benchmarks respectively.