 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCompressive sensing based privacy for fall detection
Jan 10, 2020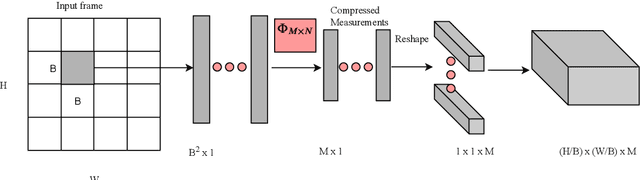

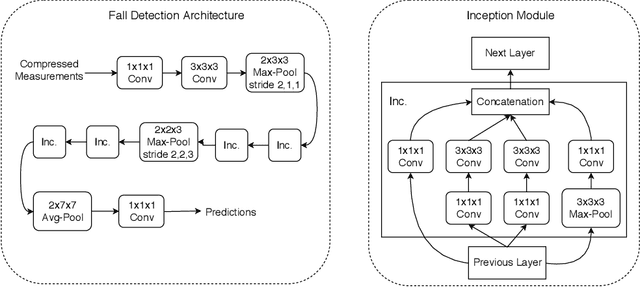
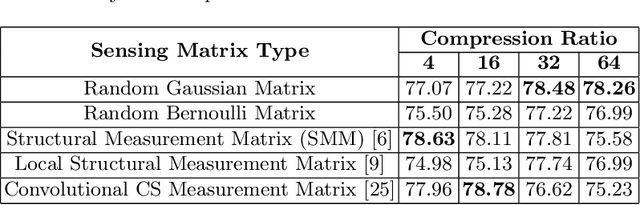
Fall detection holds immense importance in the field of healthcare, where timely detection allows for instant medical assistance. In this context, we propose a 3D ConvNet architecture which consists of 3D Inception modules for fall detection. The proposed architecture is a custom version of Inflated 3D (I3D) architecture, that takes compressed measurements of video sequence as spatio-temporal input, obtained from compressive sensing framework, rather than video sequence as input, as in the case of I3D convolutional neural network. This is adopted since privacy raises a huge concern for patients being monitored through these RGB cameras. The proposed framework for fall detection is flexible enough with respect to a wide variety of measurement matrices. Ten action classes randomly selected from Kinetics-400 with no fall examples, are employed to train our 3D ConvNet post compressive sensing with different types of sensing matrices on the original video clips. Our results show that 3D ConvNet performance remains unchanged with different sensing matrices. Also, the performance obtained with Kinetics pre-trained 3D ConvNet on compressively sensed fall videos from benchmark datasets is better than the state-of-the-art techniques.
Few Shot Speaker Recognition using Deep Neural Networks
Apr 17, 2019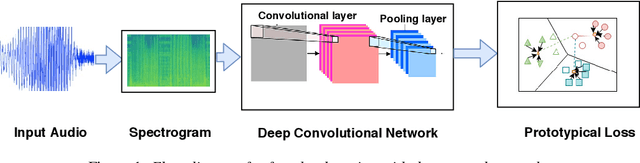

The recent advances in deep learning are mostly driven by availability of large amount of training data. However, availability of such data is not always possible for specific tasks such as speaker recognition where collection of large amount of data is not possible in practical scenarios. Therefore, in this paper, we propose to identify speakers by learning from only a few training examples. To achieve this, we use a deep neural network with prototypical loss where the input to the network is a spectrogram. For output, we project the class feature vectors into a common embedding space, followed by classification. Further, we show the effectiveness of capsule net in a few shot learning setting. To this end, we utilize an auto-encoder to learn generalized feature embeddings from class-specific embeddings obtained from capsule network. We provide exhaustive experiments on publicly available datasets and competitive baselines, demonstrating the superiority and generalization ability of the proposed few shot learning pipelines.