 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAssessing Translation capabilities of Large Language Models involving English and Indian Languages
Nov 15, 2023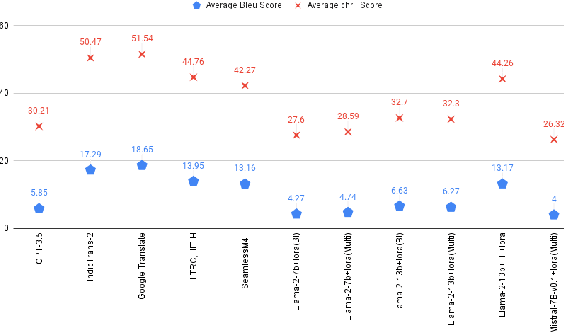

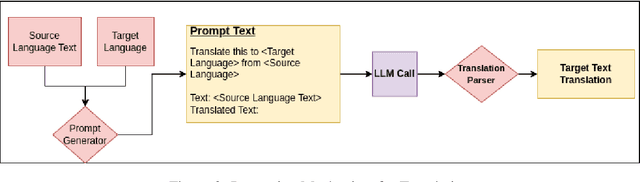
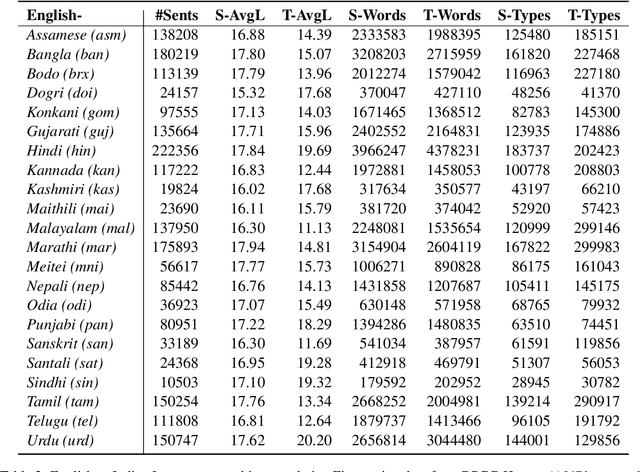
Generative Large Language Models (LLMs) have achieved remarkable advancements in various NLP tasks. In this work, our aim is to explore the multilingual capabilities of large language models by using machine translation as a task involving English and 22 Indian languages. We first investigate the translation capabilities of raw large language models, followed by exploring the in-context learning capabilities of the same raw models. We fine-tune these large language models using parameter efficient fine-tuning methods such as LoRA and additionally with full fine-tuning. Through our study, we have identified the best performing large language model for the translation task involving LLMs, which is based on LLaMA. Our results demonstrate significant progress, with average BLEU scores of 13.42, 15.93, 12.13, 12.30, and 12.07, as well as CHRF scores of 43.98, 46.99, 42.55, 42.42, and 45.39, respectively, using 2-stage fine-tuned LLaMA-13b for English to Indian languages on IN22 (conversational), IN22 (general), flores200-dev, flores200-devtest, and newstest2019 testsets. Similarly, for Indian languages to English, we achieved average BLEU scores of 14.03, 16.65, 16.17, 15.35 and 12.55 along with chrF scores of 36.71, 40.44, 40.26, 39.51, and 36.20, respectively, using fine-tuned LLaMA-13b on IN22 (conversational), IN22 (general), flores200-dev, flores200-devtest, and newstest2019 testsets. Overall, our findings highlight the potential and strength of large language models for machine translation capabilities, including for languages that are currently underrepresented in LLMs.