 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultilingual Idioms in Sentences and Conversations Across High-, Medium-, and Low-Resource Languages
Jun 01, 2026Idiomatic expressions pose a major challenge for multilingual NLP because their meanings shift between figurative and literal usage, often requiring context for accurate interpretation. Prior work has focused on high-resource languages typically evaluates isolated idiom-meaning questions, overlooking realistic discourse. We introduce MIDI, a multilingual idiom dataset spanning 3 high-, 3 medium-, and 12 low-resource languages, curated by native speakers. Unlike previous datasets, MIDI provides idioms embedded in both sentence-level and conversational contexts, capturing both literal and figurative readings. Benchmarking state-of-the-art models shows that idiom comprehension degrades in low-resource languages and that, in all resource tiers, literal interpretations are substantially harder than figurative ones. Conversational context improves performance but does not eliminate these disparities. Through controlled tests and interventions on hidden representations, we further separate memorization from reasoning, exposing core limitations of current models.
Typologically-Informed Candidate Reranking for LLM-based Translation into Low-Resource Languages
Feb 01, 2026Large language models trained predominantly on high-resource languages exhibit systematic biases toward dominant typological patterns, leading to structural non-conformance when translating into typologically divergent low-resource languages. We present a framework that leverages linguistic typology to improve translation quality without parallel training data or model retraining. The framework consists of two components: the Universal Metalinguistic Framework (UMF), which represents languages as structured profiles across 16 typological dimensions with divergence-weighted scoring, and the Computational Engine, which operates through linguistic disambiguation during generation and typological compliance scoring during selection. Evaluation across nine language pairs demonstrates intervention rates strongly correlating with typological distance from English. In experiments on 341 English sentences each having different morphological and syntactic phenomena, the framework shows an intervention precision of 48.16% for conservatively treated languages, 28.15% for morphologically dense languages, and 86.26% for structurally profiled languages. The framework requires no parallel training data and operates with any LLM capable of producing multiple candidate outputs, enabling practical deployment for under-resourced languages.
Decoding Fake Narratives in Spreading Hateful Stories: A Dual-Head RoBERTa Model with Multi-Task Learning
Dec 18, 2025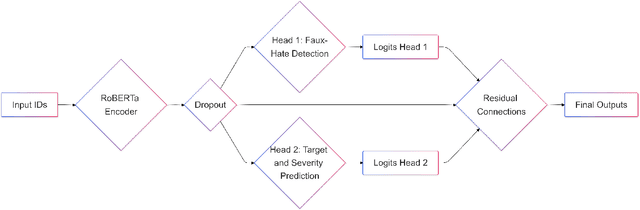
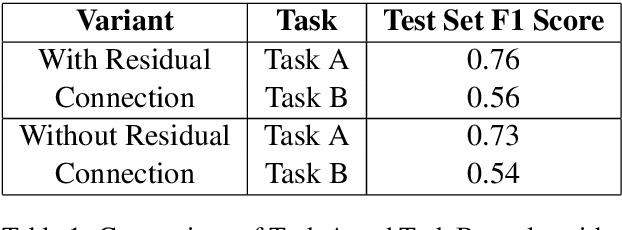
Social media platforms, while enabling global connectivity, have become hubs for the rapid spread of harmful content, including hate speech and fake narratives \cite{davidson2017automated, shu2017fake}. The Faux-Hate shared task focuses on detecting a specific phenomenon: the generation of hate speech driven by fake narratives, termed Faux-Hate. Participants are challenged to identify such instances in code-mixed Hindi-English social media text. This paper describes our system developed for the shared task, addressing two primary sub-tasks: (a) Binary Faux-Hate detection, involving fake and hate speech classification, and (b) Target and Severity prediction, categorizing the intended target and severity of hateful content. Our approach combines advanced natural language processing techniques with domain-specific pretraining to enhance performance across both tasks. The system achieved competitive results, demonstrating the efficacy of leveraging multi-task learning for this complex problem.
* Accepted Paper, Anthology ID: 2024.icon-fauxhate.3, 4 pages, 1 figure, 1 table
Yes-MT's Submission to the Low-Resource Indic Language Translation Shared Task in WMT 2024
Dec 17, 2025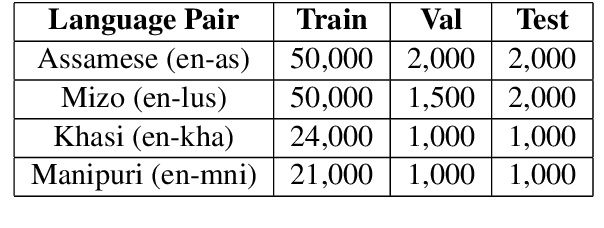
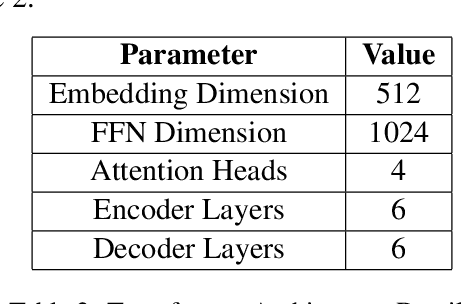
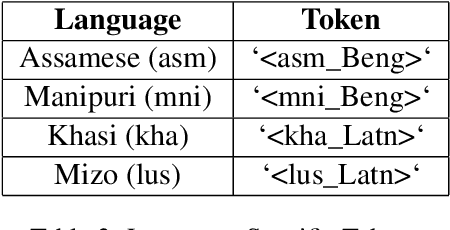
This paper presents the systems submitted by the Yes-MT team for the Low-Resource Indic Language Translation Shared Task at WMT 2024 (Pakray et al., 2024), focusing on translating between English and the Assamese, Mizo, Khasi, and Manipuri languages. The experiments explored various approaches, including fine-tuning pre-trained models like mT5 (Xue et al., 2020) and IndicBart (Dabre et al., 2021) in both multilingual and monolingual settings, LoRA (Hu et al., 2021) fine-tuning IndicTrans2 (Gala et al., 2023), zero-shot and few-shot prompting (Brown, 2020) with large language models (LLMs) like Llama 3 (Dubey et al., 2024) and Mixtral 8x7b (Jiang et al., 2024), LoRA supervised fine-tuning of Llama 3 (Mecklenburg et al., 2024), and training Transformer models (Vaswani, 2017) from scratch. The results were evaluated on the WMT23 Low-Resource Indic Language Translation Shared Task test data using SacreBLEU (Post, 2018) and CHRF (Popovic, 2015), highlighting the challenges of low-resource translation and the potential of LLMs for these tasks, particularly with fine-tuning.
* Accepted at WMT 2024
Rethinking Tokenization for Rich Morphology: The Dominance of Unigram over BPE and Morphological Alignment
Aug 11, 2025Prior work on language modeling showed conflicting findings about whether morphologically aligned approaches to tokenization improve performance, particularly for languages with complex morphology. To investigate this, we select a typologically diverse set of languages: Telugu (agglutinative), Hindi (primarily fusional with some agglutination), and English (fusional). We conduct a comprehensive evaluation of language models -- starting from tokenizer training and extending through the finetuning and downstream task evaluation. To account for the consistent performance differences observed across tokenizer variants, we focus on two key factors: morphological alignment and tokenization quality. To assess morphological alignment of tokenizers in Telugu, we create a dataset containing gold morpheme segmentations of 600 derivational and 7000 inflectional word forms. Our experiments reveal that better morphological alignment correlates positively -- though moderately -- with performance in syntax-based tasks such as Parts-of-Speech tagging, Named Entity Recognition and Dependency Parsing. However, we also find that the tokenizer algorithm (Byte-pair Encoding vs. Unigram) plays a more significant role in influencing downstream performance than morphological alignment alone. Naive Unigram tokenizers outperform others across most settings, though hybrid tokenizers that incorporate morphological segmentation significantly improve performance within the BPE framework. In contrast, intrinsic metrics like Corpus Token Count (CTC) and R\'enyi entropy showed no correlation with downstream performance.
keepitsimple at SemEval-2025 Task 3: LLM-Uncertainty based Approach for Multilingual Hallucination Span Detection
May 23, 2025Identification of hallucination spans in black-box language model generated text is essential for applications in the real world. A recent attempt at this direction is SemEval-2025 Task 3, Mu-SHROOM-a Multilingual Shared Task on Hallucinations and Related Observable Over-generation Errors. In this work, we present our solution to this problem, which capitalizes on the variability of stochastically-sampled responses in order to identify hallucinated spans. Our hypothesis is that if a language model is certain of a fact, its sampled responses will be uniform, while hallucinated facts will yield different and conflicting results. We measure this divergence through entropy-based analysis, allowing for accurate identification of hallucinated segments. Our method is not dependent on additional training and hence is cost-effective and adaptable. In addition, we conduct extensive hyperparameter tuning and perform error analysis, giving us crucial insights into model behavior.
Fine-tuning Pre-trained Named Entity Recognition Models For Indian Languages
May 08, 2024
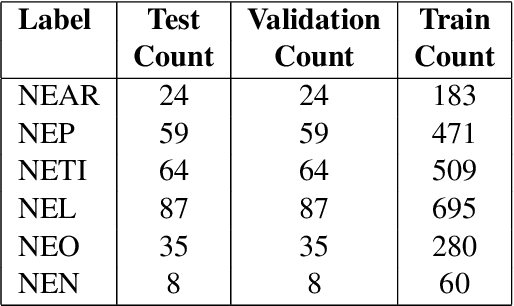
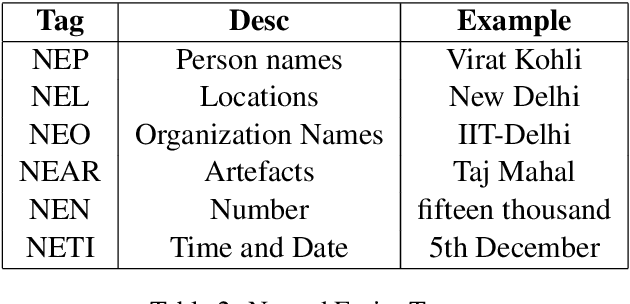
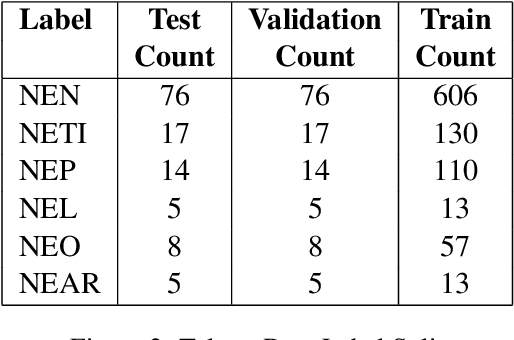
Named Entity Recognition (NER) is a useful component in Natural Language Processing (NLP) applications. It is used in various tasks such as Machine Translation, Summarization, Information Retrieval, and Question-Answering systems. The research on NER is centered around English and some other major languages, whereas limited attention has been given to Indian languages. We analyze the challenges and propose techniques that can be tailored for Multilingual Named Entity Recognition for Indian Languages. We present a human annotated named entity corpora of 40K sentences for 4 Indian languages from two of the major Indian language families. Additionally,we present a multilingual model fine-tuned on our dataset, which achieves an F1 score of 0.80 on our dataset on average. We achieve comparable performance on completely unseen benchmark datasets for Indian languages which affirms the usability of our model.
Exploring News Summarization and Enrichment in a Highly Resource-Scarce Indian Language: A Case Study of Mizo
Apr 25, 2024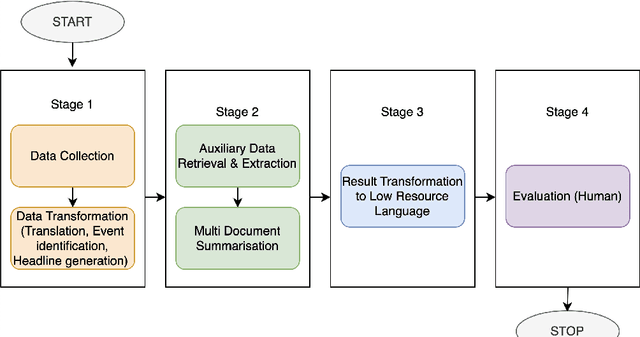



Obtaining sufficient information in one's mother tongue is crucial for satisfying the information needs of the users. While high-resource languages have abundant online resources, the situation is less than ideal for very low-resource languages. Moreover, the insufficient reporting of vital national and international events continues to be a worry, especially in languages with scarce resources, like \textbf{Mizo}. In this paper, we conduct a study to investigate the effectiveness of a simple methodology designed to generate a holistic summary for Mizo news articles, which leverages English-language news to supplement and enhance the information related to the corresponding news events. Furthermore, we make available 500 Mizo news articles and corresponding enriched holistic summaries. Human evaluation confirms that our approach significantly enhances the information coverage of Mizo news articles. The mizo dataset and code can be accessed at \url{https://github.com/barvin04/mizo_enrichment
Assessing Translation capabilities of Large Language Models involving English and Indian Languages
Nov 15, 2023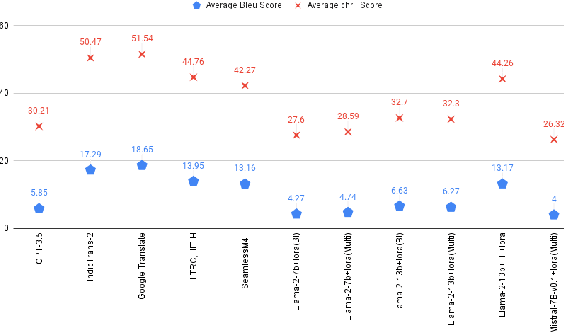

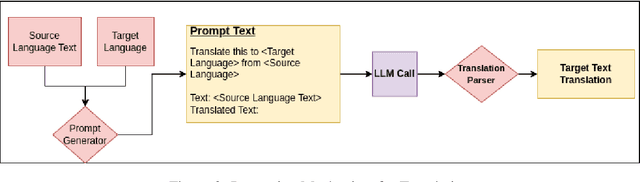
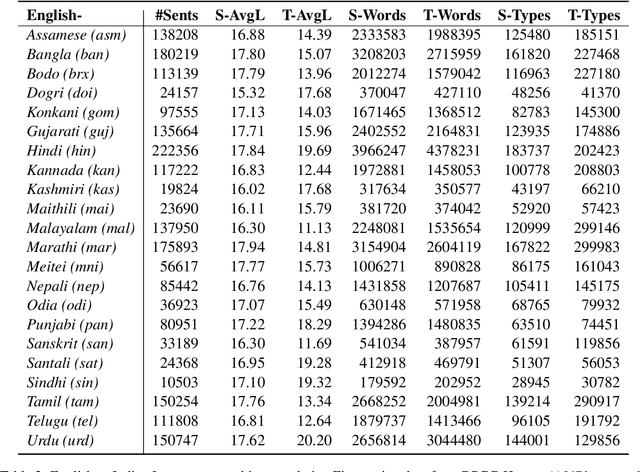
Generative Large Language Models (LLMs) have achieved remarkable advancements in various NLP tasks. In this work, our aim is to explore the multilingual capabilities of large language models by using machine translation as a task involving English and 22 Indian languages. We first investigate the translation capabilities of raw large language models, followed by exploring the in-context learning capabilities of the same raw models. We fine-tune these large language models using parameter efficient fine-tuning methods such as LoRA and additionally with full fine-tuning. Through our study, we have identified the best performing large language model for the translation task involving LLMs, which is based on LLaMA. Our results demonstrate significant progress, with average BLEU scores of 13.42, 15.93, 12.13, 12.30, and 12.07, as well as CHRF scores of 43.98, 46.99, 42.55, 42.42, and 45.39, respectively, using 2-stage fine-tuned LLaMA-13b for English to Indian languages on IN22 (conversational), IN22 (general), flores200-dev, flores200-devtest, and newstest2019 testsets. Similarly, for Indian languages to English, we achieved average BLEU scores of 14.03, 16.65, 16.17, 15.35 and 12.55 along with chrF scores of 36.71, 40.44, 40.26, 39.51, and 36.20, respectively, using fine-tuned LLaMA-13b on IN22 (conversational), IN22 (general), flores200-dev, flores200-devtest, and newstest2019 testsets. Overall, our findings highlight the potential and strength of large language models for machine translation capabilities, including for languages that are currently underrepresented in LLMs.