 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCompanionCast: A Multi-Agent Conversational AI Framework with Spatial Audio for Social Co-Viewing Experiences
Dec 11, 2025Social presence is central to the enjoyment of watching content together, yet modern media consumption is increasingly solitary. We investigate whether multi-agent conversational AI systems can recreate the dynamics of shared viewing experiences across diverse content types. We present CompanionCast, a general framework for orchestrating multiple role-specialized AI agents that respond to video content using multimodal inputs, speech synthesis, and spatial audio. Distinctly, CompanionCast integrates an LLM-as-a-Judge module that iteratively scores and refines conversations across five dimensions (relevance, authenticity, engagement, diversity, personality consistency). We validate this framework through sports viewing, a domain with rich dynamics and strong social traditions, where a pilot study with soccer fans suggests that multi-agent interaction improves perceived social presence compared to solo viewing. We contribute: (1) a generalizable framework for orchestrating multi-agent conversations around multimodal video content, (2) a novel evaluator-agent pipeline for conversation quality control, and (3) exploratory evidence of increased social presence in AI-mediated co-viewing. We discuss challenges and future directions for applying this approach to diverse viewing contexts including entertainment, education, and collaborative watching experiences.
Measuring Time-Series Dataset Similarity using Wasserstein Distance
Jul 29, 2025The emergence of time-series foundation model research elevates the growing need to measure the (dis)similarity of time-series datasets. A time-series dataset similarity measure aids research in multiple ways, including model selection, finetuning, and visualization. In this paper, we propose a distribution-based method to measure time-series dataset similarity by leveraging the Wasserstein distance. We consider a time-series dataset an empirical instantiation of an underlying multivariate normal distribution (MVN). The similarity between two time-series datasets is thus computed as the Wasserstein distance between their corresponding MVNs. Comprehensive experiments and visualization show the effectiveness of our approach. Specifically, we show how the Wasserstein distance helps identify similar time-series datasets and facilitates inference performance estimation of foundation models in both out-of-distribution and transfer learning evaluation, with high correlations between our proposed measure and the inference loss (>0.60).
Antidote: Post-fine-tuning Safety Alignment for Large Language Models against Harmful Fine-tuning
Aug 18, 2024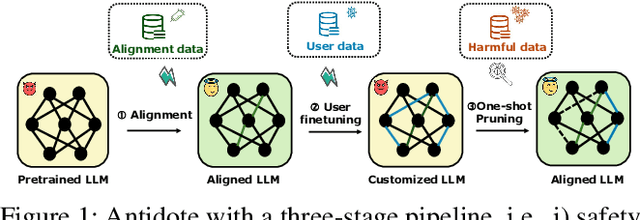
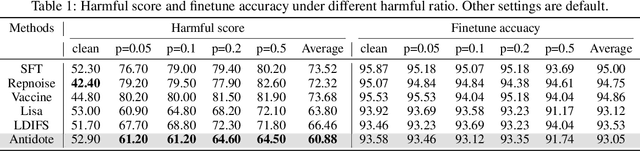
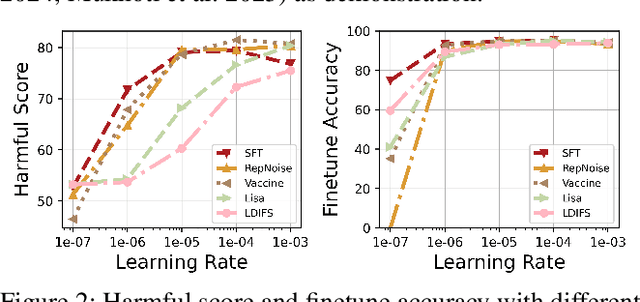
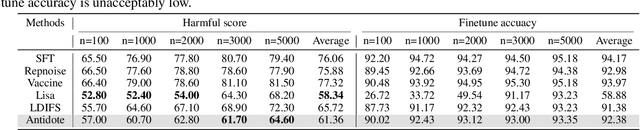
Safety aligned Large Language Models (LLMs) are vulnerable to harmful fine-tuning attacks \cite{qi2023fine}-- a few harmful data mixed in the fine-tuning dataset can break the LLMs's safety alignment. Existing mitigation strategies include alignment stage solutions \cite{huang2024vaccine, rosati2024representation} and fine-tuning stage solutions \cite{huang2024lazy,mukhoti2023fine}. However, our evaluation shows that both categories of defenses fail \textit{when some specific training hyper-parameters are chosen} -- a large learning rate or a large number of training epochs in the fine-tuning stage can easily invalidate the defense, which however, is necessary to guarantee finetune performance. To this end, we propose Antidote, a post-fine-tuning stage solution, which remains \textbf{\textit{agnostic to the training hyper-parameters in the fine-tuning stage}}. Antidote relies on the philosophy that by removing the harmful parameters, the harmful model can be recovered from the harmful behaviors, regardless of how those harmful parameters are formed in the fine-tuning stage. With this philosophy, we introduce a one-shot pruning stage after harmful fine-tuning to remove the harmful weights that are responsible for the generation of harmful content. Despite its embarrassing simplicity, empirical results show that Antidote can reduce harmful score while maintaining accuracy on downstream tasks.