 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDAS3R: Dynamics-Aware Gaussian Splatting for Static Scene Reconstruction
Dec 27, 2024We propose a novel framework for scene decomposition and static background reconstruction from everyday videos. By integrating the trained motion masks and modeling the static scene as Gaussian splats with dynamics-aware optimization, our method achieves more accurate background reconstruction results than previous works. Our proposed method is termed DAS3R, an abbreviation for Dynamics-Aware Gaussian Splatting for Static Scene Reconstruction. Compared to existing methods, DAS3R is more robust in complex motion scenarios, capable of handling videos where dynamic objects occupy a significant portion of the scene, and does not require camera pose inputs or point cloud data from SLAM-based methods. We compared DAS3R against recent distractor-free approaches on the DAVIS and Sintel datasets; DAS3R demonstrates enhanced performance and robustness with a margin of more than 2 dB in PSNR. The project's webpage can be accessed via \url{https://kai422.github.io/DAS3R/}
Boundary-aware Information Maximization for Self-supervised Medical Image Segmentation
Feb 16, 2022Unsupervised pre-training has been proven as an effective approach to boost various downstream tasks given limited labeled data. Among various methods, contrastive learning learns a discriminative representation by constructing positive and negative pairs. However, it is not trivial to build reasonable pairs for a segmentation task in an unsupervised way. In this work, we propose a novel unsupervised pre-training framework that avoids the drawback of contrastive learning. Our framework consists of two principles: unsupervised over-segmentation as a pre-train task using mutual information maximization and boundary-aware preserving learning. Experimental results on two benchmark medical segmentation datasets reveal our method's effectiveness in improving segmentation performance when few annotated images are available.
Diversified Multi-prototype Representation for Semi-supervised Segmentation
Nov 16, 2021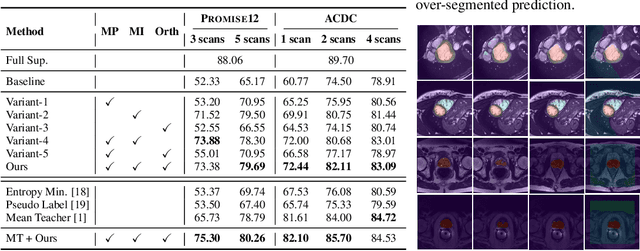
This work considers semi-supervised segmentation as a dense prediction problem based on prototype vector correlation and proposes a simple way to represent each segmentation class with multiple prototypes. To avoid degenerate solutions, two regularization strategies are applied on unlabeled images. The first one leverages mutual information maximization to ensure that all prototype vectors are considered by the network. The second explicitly enforces prototypes to be orthogonal by minimizing their cosine distance. Experimental results on two benchmark medical segmentation datasets reveal our method's effectiveness in improving segmentation performance when few annotated images are available.
Self-Paced Contrastive Learning for Semi-supervised Medical Image Segmentation with Meta-labels
Aug 22, 2021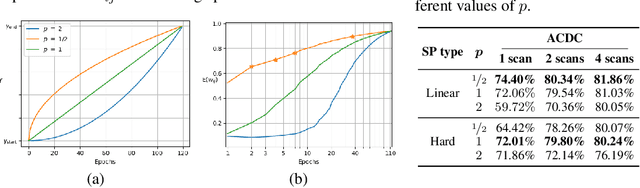
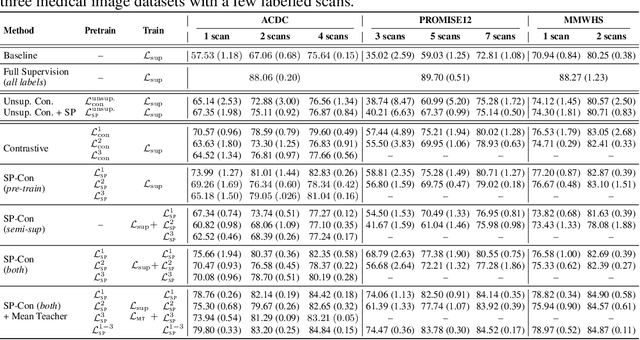
Pre-training a recognition model with contrastive learning on a large dataset of unlabeled data has shown great potential to boost the performance of a downstream task, e.g., image classification. However, in domains such as medical imaging, collecting unlabeled data can be challenging and expensive. In this work, we propose to adapt contrastive learning to work with meta-label annotations, for improving the model's performance in medical image segmentation even when no additional unlabeled data is available. Meta-labels such as the location of a 2D slice in a 3D MRI scan or the type of device used, often come for free during the acquisition process. We use the meta-labels for pre-training the image encoder as well as to regularize a semi-supervised training, in which a reduced set of annotated data is used for training. Finally, to fully exploit the weak annotations, a self-paced learning approach is used to help the learning and discriminate useful labels from noise. Results on three different medical image segmentation datasets show that our approach: i) highly boosts the performance of a model trained on a few scans, ii) outperforms previous contrastive and semi-supervised approaches, and iii) reaches close to the performance of a model trained on the full data.
Context-aware virtual adversarial training for anatomically-plausible segmentation
Jul 13, 2021



Despite their outstanding accuracy, semi-supervised segmentation methods based on deep neural networks can still yield predictions that are considered anatomically impossible by clinicians, for instance, containing holes or disconnected regions. To solve this problem, we present a Context-aware Virtual Adversarial Training (CaVAT) method for generating anatomically plausible segmentation. Unlike approaches focusing solely on accuracy, our method also considers complex topological constraints like connectivity which cannot be easily modeled in a differentiable loss function. We use adversarial training to generate examples violating the constraints, so the network can learn to avoid making such incorrect predictions on new examples, and employ the Reinforce algorithm to handle non-differentiable segmentation constraints. The proposed method offers a generic and efficient way to add any constraint on top of any segmentation network. Experiments on two clinically-relevant datasets show our method to produce segmentations that are both accurate and anatomically-plausible in terms of region connectivity.
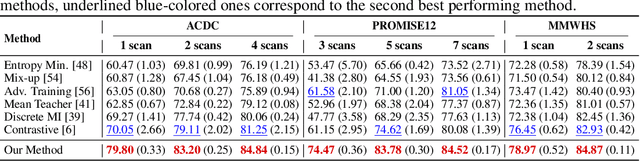
Boosting Semi-supervised Image Segmentation with Global and Local Mutual Information Regularization
Mar 08, 2021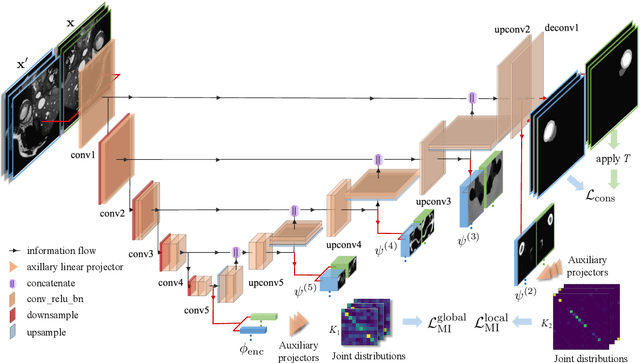
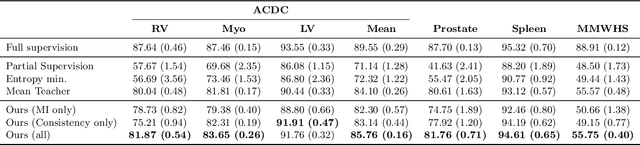

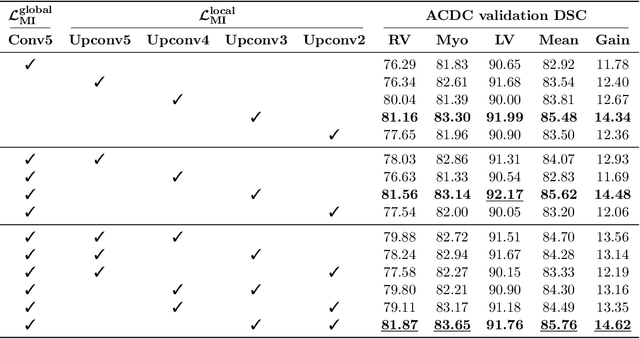
The scarcity of labeled data often impedes the application of deep learning to the segmentation of medical images. Semi-supervised learning seeks to overcome this limitation by leveraging unlabeled examples in the learning process. In this paper, we present a novel semi-supervised segmentation method that leverages mutual information (MI) on categorical distributions to achieve both global representation invariance and local smoothness. In this method, we maximize the MI for intermediate feature embeddings that are taken from both the encoder and decoder of a segmentation network. We first propose a global MI loss constraining the encoder to learn an image representation that is invariant to geometric transformations. Instead of resorting to computationally-expensive techniques for estimating the MI on continuous feature embeddings, we use projection heads to map them to a discrete cluster assignment where MI can be computed efficiently. Our method also includes a local MI loss to promote spatial consistency in the feature maps of the decoder and provide a smoother segmentation. Since mutual information does not require a strict ordering of clusters in two different assignments, we incorporate a final consistency regularization loss on the output which helps align the cluster labels throughout the network. We evaluate the method on three challenging publicly-available datasets for medical image segmentation. Experimental results show our method to outperform recently-proposed approaches for semi-supervised segmentation and provide an accuracy near to full supervision while training with very few annotated images
Self-paced and self-consistent co-training for semi-supervised image segmentation
Nov 09, 2020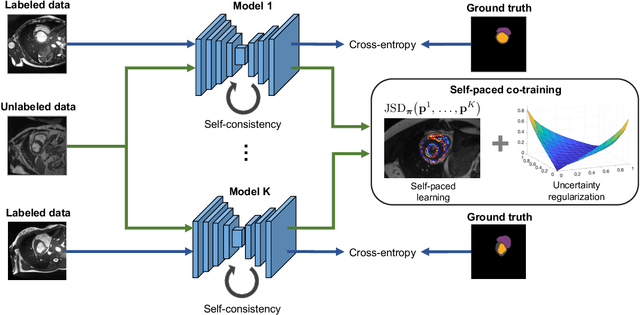
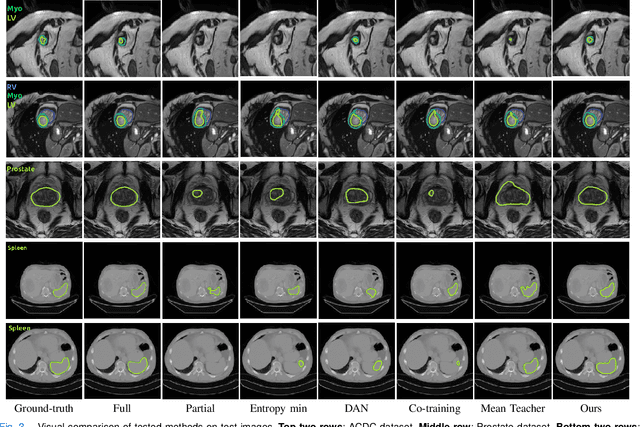

Deep co-training has recently been proposed as an effective approach for image segmentation when annotated data is scarce. In this paper, we improve existing approaches for semi-supervised segmentation with a self-paced and self-consistent co-training method. To help distillate information from unlabeled images, we first design a self-paced learning strategy for co-training that lets jointly-trained neural networks focus on easier-to-segment regions first, and then gradually consider harder ones.This is achieved via an end-to-end differentiable loss inthe form of a generalized Jensen Shannon Divergence(JSD). Moreover, to encourage predictions from different networks to be both consistent and confident, we enhance this generalized JSD loss with an uncertainty regularizer based on entropy. The robustness of individual models is further improved using a self-ensembling loss that enforces their prediction to be consistent across different training iterations. We demonstrate the potential of our method on three challenging image segmentation problems with different image modalities, using small fraction of labeled data. Results show clear advantages in terms of performance compared to the standard co-training baselines and recently proposed state-of-the-art approaches for semi-supervised segmentation
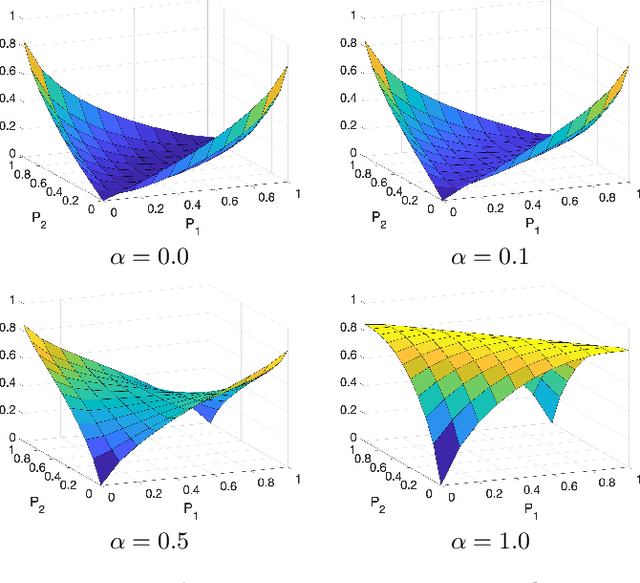
Information based Deep Clustering: An experimental study
Oct 03, 2019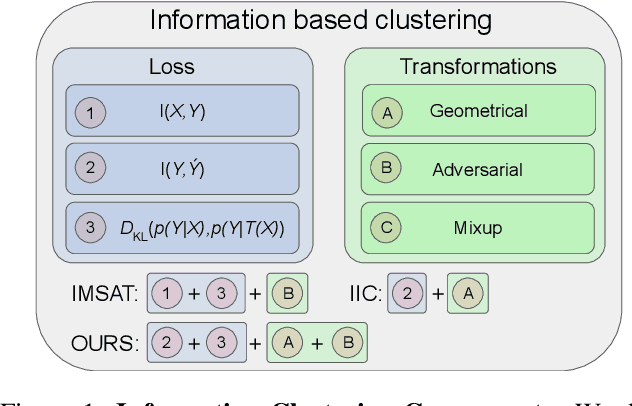

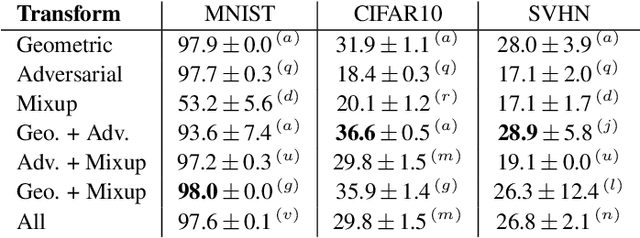

Recently, two methods have shown outstanding performance for clustering images and jointly learning the feature representation. The first, called Information Maximiz-ing Self-Augmented Training (IMSAT), maximizes the mutual information between input and clusters while using a regularization term based on virtual adversarial examples. The second, named Invariant Information Clustering (IIC), maximizes the mutual information between the clustering of a sample and its geometrically transformed version. These methods use mutual information in distinct ways and leverage different kinds of transformations. This work proposes a comprehensive analysis of transformation and losses for deep clustering, where we compare numerous combinations of these two components and evaluate how they interact with one another. Results suggest that mutual information between a sample and its transformed representation leads to state-of-the-art performance for deep clustering, especially when used jointly with geometrical and adversarial transformations.
Boosting Image Recognition with Non-differentiable Constraints
Oct 02, 2019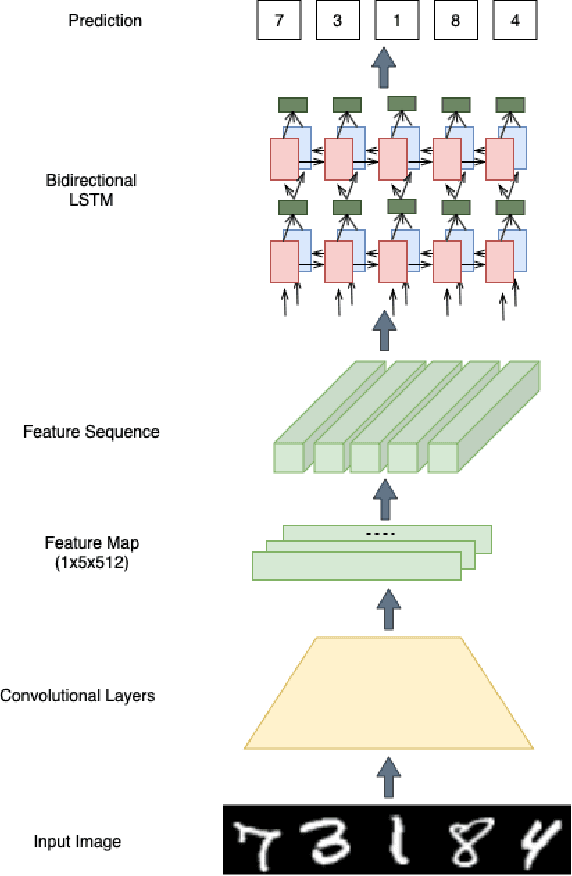



In this paper, we study the problem of image recognition with non-differentiable constraints. A lot of real-life recognition applications require a rich output structure with deterministic constraints that are discrete or modeled by a non-differentiable function. A prime example is recognizing digit sequences, which are restricted by such rules (e.g., \textit{container code detection}, \textit{social insurance number recognition}, etc.). We investigate the usefulness of adding non-differentiable constraints in learning for the task of digit sequence recognition. Toward this goal, we synthesize six different datasets from MNIST and Cropped SVHN, with three discrete rules inspired by real-life protocols. To deal with the non-differentiability of these rules, we propose a reinforcement learning approach based on the policy gradient method. We find that incorporating this rule-based reinforcement can effectively increase the accuracy for all datasets and provide a good inductive bias which improves the model even with limited data. On one of the datasets, MNIST\_Rule2, models trained with rule-based reinforcement increase the accuracy by 4.7\% for 2000 samples and 23.6\% for 500 samples. We further test our model against synthesized adversarial examples, e.g., blocking out digits, and observe that adding our rule-based reinforcement increases the model robustness with a relatively smaller performance drop.
Discretely-constrained deep network for weakly supervised segmentation
Aug 15, 2019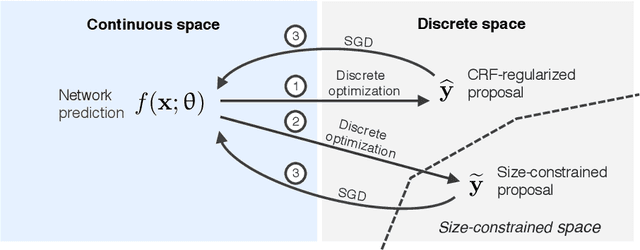
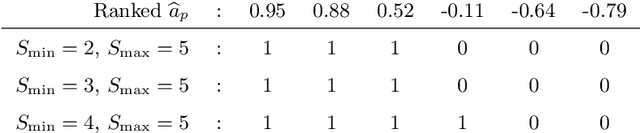
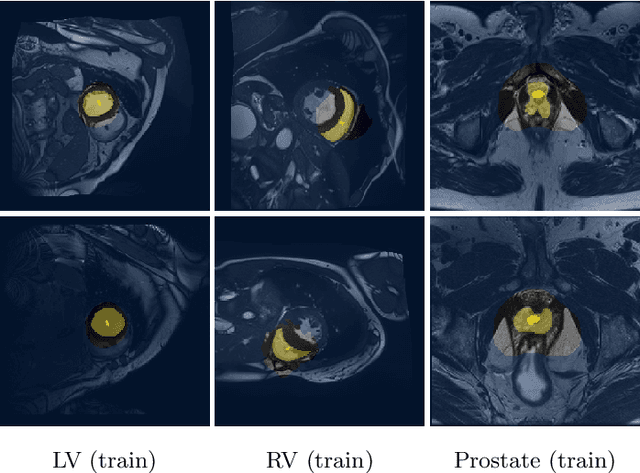
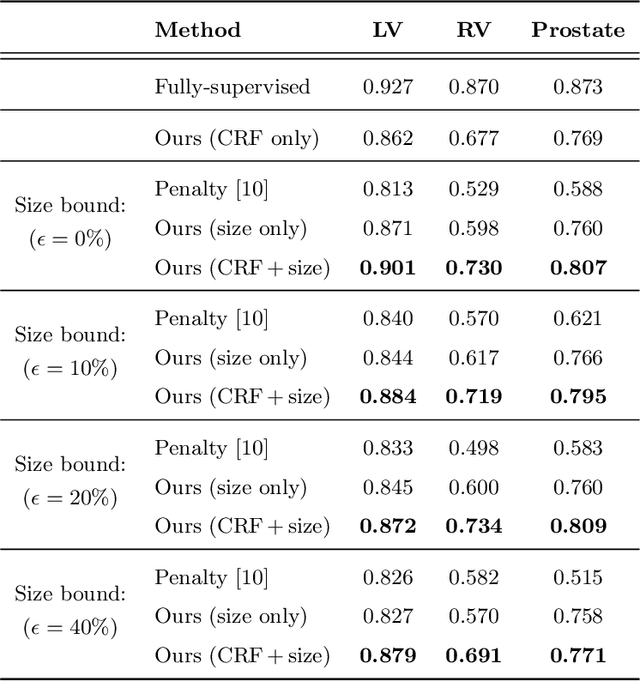
An efficient strategy for weakly-supervised segmentation is to impose constraints or regularization priors on target regions. Recent efforts have focused on incorporating such constraints in the training of convolutional neural networks (CNN), however this has so far been done within a continuous optimization framework. Yet, various segmentation constraints and regularization can be modeled and optimized more efficiently in a discrete formulation. This paper proposes a method, based on the alternating direction method of multipliers (ADMM) algorithm, to train a CNN with discrete constraints and regularization priors. This method is applied to the segmentation of medical images with weak annotations, where both size constraints and boundary length regularization are enforced. Experiments on a benchmark cardiac segmentation dataset show our method to yield a performance near to full supervision.