 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging Automatic CAD Annotations for Supervised Learning in 3D Scene Understanding
Apr 18, 2025High-level 3D scene understanding is essential in many applications. However, the challenges of generating accurate 3D annotations make development of deep learning models difficult. We turn to recent advancements in automatic retrieval of synthetic CAD models, and show that data generated by such methods can be used as high-quality ground truth for training supervised deep learning models. More exactly, we employ a pipeline akin to the one previously used to automatically annotate objects in ScanNet scenes with their 9D poses and CAD models. This time, we apply it to the recent ScanNet++ v1 dataset, which previously lacked such annotations. Our findings demonstrate that it is not only possible to train deep learning models on these automatically-obtained annotations but that the resulting models outperform those trained on manually annotated data. We validate this on two distinct tasks: point cloud completion and single-view CAD model retrieval and alignment. Our results underscore the potential of automatic 3D annotations to enhance model performance while significantly reducing annotation costs. To support future research in 3D scene understanding, we will release our annotations, which we call SCANnotate++, along with our trained models.
ICG-MVSNet: Learning Intra-view and Cross-view Relationships for Guidance in Multi-View Stereo
Mar 27, 2025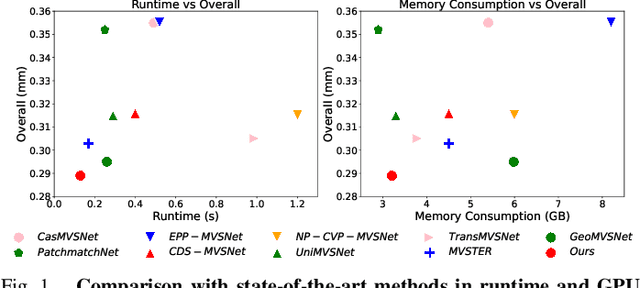
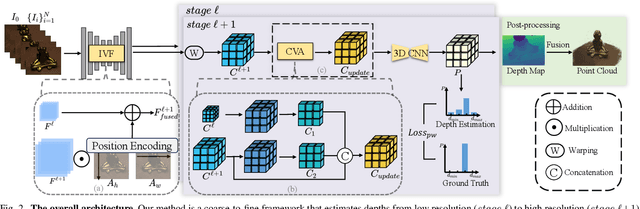
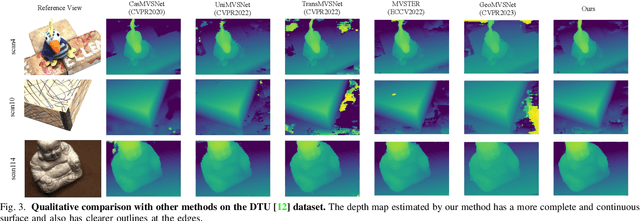

Multi-view Stereo (MVS) aims to estimate depth and reconstruct 3D point clouds from a series of overlapping images. Recent learning-based MVS frameworks overlook the geometric information embedded in features and correlations, leading to weak cost matching. In this paper, we propose ICG-MVSNet, which explicitly integrates intra-view and cross-view relationships for depth estimation. Specifically, we develop an intra-view feature fusion module that leverages the feature coordinate correlations within a single image to enhance robust cost matching. Additionally, we introduce a lightweight cross-view aggregation module that efficiently utilizes the contextual information from volume correlations to guide regularization. Our method is evaluated on the DTU dataset and Tanks and Temples benchmark, consistently achieving competitive performance against state-of-the-art works, while requiring lower computational resources.
Reality's Canvas, Language's Brush: Crafting 3D Avatars from Monocular Video
Dec 08, 2023



Recent advancements in 3D avatar generation excel with multi-view supervision for photorealistic models. However, monocular counterparts lag in quality despite broader applicability. We propose ReCaLab to close this gap. ReCaLab is a fully-differentiable pipeline that learns high-fidelity 3D human avatars from just a single RGB video. A pose-conditioned deformable NeRF is optimized to volumetrically represent a human subject in canonical T-pose. The canonical representation is then leveraged to efficiently associate viewpoint-agnostic textures using 2D-3D correspondences. This enables to separately generate albedo and shading which jointly compose an RGB prediction. The design allows to control intermediate results for human pose, body shape, texture, and lighting with text prompts. An image-conditioned diffusion model thereby helps to animate appearance and pose of the 3D avatar to create video sequences with previously unseen human motion. Extensive experiments show that ReCaLab outperforms previous monocular approaches in terms of image quality for image synthesis tasks. ReCaLab even outperforms multi-view methods that leverage up to 19x more synchronized videos for the task of novel pose rendering. Moreover, natural language offers an intuitive user interface for creative manipulation of 3D human avatars.
PatchComplete: Learning Multi-Resolution Patch Priors for 3D Shape Completion on Unseen Categories
Jun 10, 2022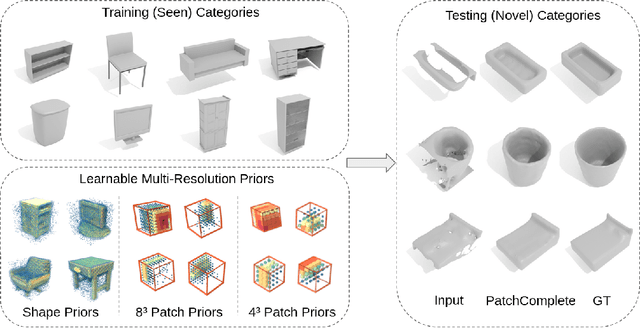
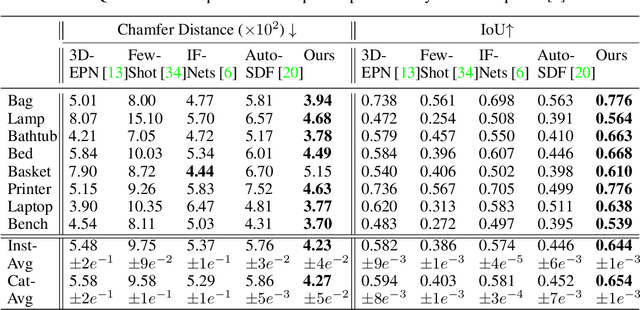

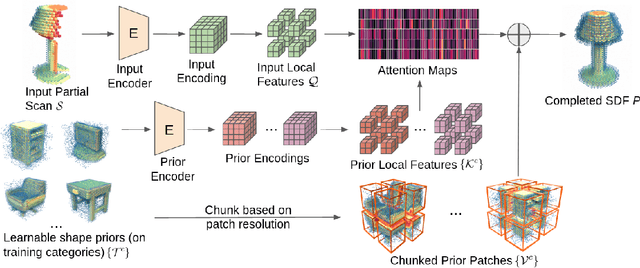
While 3D shape representations enable powerful reasoning in many visual and perception applications, learning 3D shape priors tends to be constrained to the specific categories trained on, leading to an inefficient learning process, particularly for general applications with unseen categories. Thus, we propose PatchComplete, which learns effective shape priors based on multi-resolution local patches, which are often more general than full shapes (e.g., chairs and tables often both share legs) and thus enable geometric reasoning about unseen class categories. To learn these shared substructures, we learn multi-resolution patch priors across all train categories, which are then associated to input partial shape observations by attention across the patch priors, and finally decoded into a complete shape reconstruction. Such patch-based priors avoid overfitting to specific train categories and enable reconstruction on entirely unseen categories at test time. We demonstrate the effectiveness of our approach on synthetic ShapeNet data as well as challenging real-scanned objects from ScanNet, which include noise and clutter, improving over state of the art in novel-category shape completion by 19.3% in chamfer distance on ShapeNet, and 9.0% for ScanNet.