 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging Automatic CAD Annotations for Supervised Learning in 3D Scene Understanding
Apr 18, 2025High-level 3D scene understanding is essential in many applications. However, the challenges of generating accurate 3D annotations make development of deep learning models difficult. We turn to recent advancements in automatic retrieval of synthetic CAD models, and show that data generated by such methods can be used as high-quality ground truth for training supervised deep learning models. More exactly, we employ a pipeline akin to the one previously used to automatically annotate objects in ScanNet scenes with their 9D poses and CAD models. This time, we apply it to the recent ScanNet++ v1 dataset, which previously lacked such annotations. Our findings demonstrate that it is not only possible to train deep learning models on these automatically-obtained annotations but that the resulting models outperform those trained on manually annotated data. We validate this on two distinct tasks: point cloud completion and single-view CAD model retrieval and alignment. Our results underscore the potential of automatic 3D annotations to enhance model performance while significantly reducing annotation costs. To support future research in 3D scene understanding, we will release our annotations, which we call SCANnotate++, along with our trained models.
PyTorchGeoNodes: Enabling Differentiable Shape Programs for 3D Shape Reconstruction
Apr 16, 2024



We propose PyTorchGeoNodes, a differentiable module for reconstructing 3D objects from images using interpretable shape programs. In comparison to traditional CAD model retrieval methods, the use of shape programs for 3D reconstruction allows for reasoning about the semantic properties of reconstructed objects, editing, low memory footprint, etc. However, the utilization of shape programs for 3D scene understanding has been largely neglected in past works. As our main contribution, we enable gradient-based optimization by introducing a module that translates shape programs designed in Blender, for example, into efficient PyTorch code. We also provide a method that relies on PyTorchGeoNodes and is inspired by Monte Carlo Tree Search (MCTS) to jointly optimize discrete and continuous parameters of shape programs and reconstruct 3D objects for input scenes. In our experiments, we apply our algorithm to reconstruct 3D objects in the ScanNet dataset and evaluate our results against CAD model retrieval-based reconstructions. Our experiments indicate that our reconstructions match well the input scenes while enabling semantic reasoning about reconstructed objects.
HOC-Search: Efficient CAD Model and Pose Retrieval from RGB-D Scans
Sep 12, 2023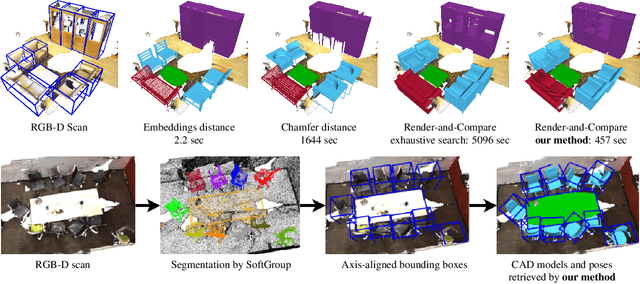
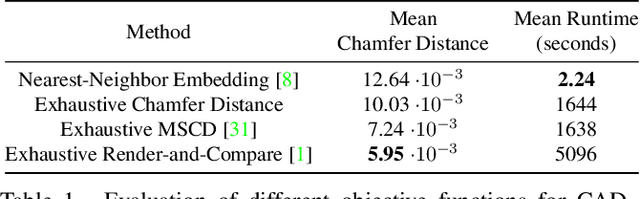
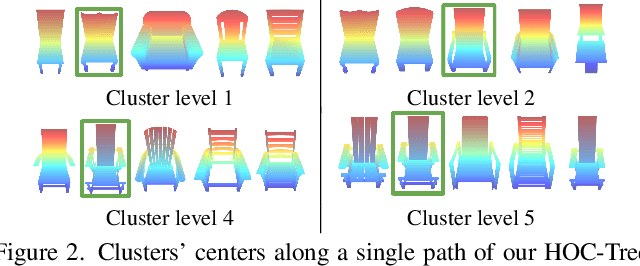
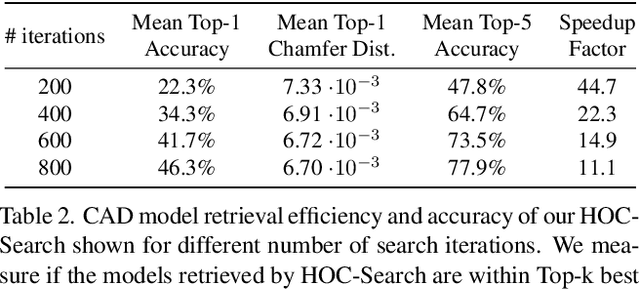
We present an automated and efficient approach for retrieving high-quality CAD models of objects and their poses in a scene captured by a moving RGB-D camera. We first investigate various objective functions to measure similarity between a candidate CAD object model and the available data, and the best objective function appears to be a "render-and-compare" method comparing depth and mask rendering. We thus introduce a fast-search method that approximates an exhaustive search based on this objective function for simultaneously retrieving the object category, a CAD model, and the pose of an object given an approximate 3D bounding box. This method involves a search tree that organizes the CAD models and object properties including object category and pose for fast retrieval and an algorithm inspired by Monte Carlo Tree Search, that efficiently searches this tree. We show that this method retrieves CAD models that fit the real objects very well, with a speed-up factor of 10x to 120x compared to exhaustive search.
Automatically Annotating Indoor Images with CAD Models via RGB-D Scans
Dec 22, 2022



We present an automatic method for annotating images of indoor scenes with the CAD models of the objects by relying on RGB-D scans. Through a visual evaluation by 3D experts, we show that our method retrieves annotations that are at least as accurate as manual annotations, and can thus be used as ground truth without the burden of manually annotating 3D data. We do this using an analysis-by-synthesis approach, which compares renderings of the CAD models with the captured scene. We introduce a 'cloning procedure' that identifies objects that have the same geometry, to annotate these objects with the same CAD models. This allows us to obtain complete annotations for the ScanNet dataset and the recent ARKitScenes dataset.
Depth-aware Object Segmentation and Grasp Detection for Robotic Picking Tasks
Nov 22, 2021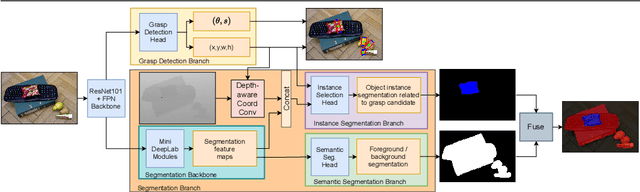

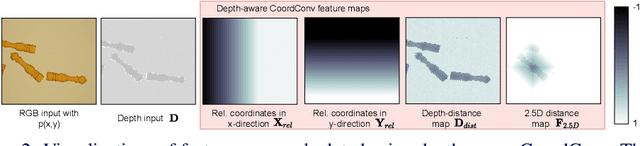
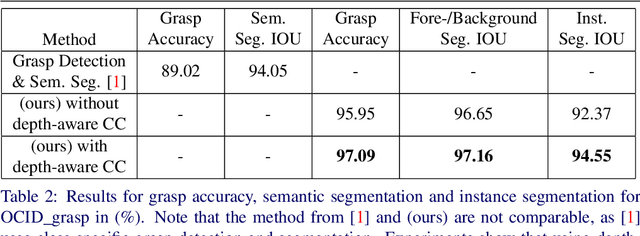
In this paper, we present a novel deep neural network architecture for joint class-agnostic object segmentation and grasp detection for robotic picking tasks using a parallel-plate gripper. We introduce depth-aware Coordinate Convolution (CoordConv), a method to increase accuracy for point proposal based object instance segmentation in complex scenes without adding any additional network parameters or computation complexity. Depth-aware CoordConv uses depth data to extract prior information about the location of an object to achieve highly accurate object instance segmentation. These resulting segmentation masks, combined with predicted grasp candidates, lead to a complete scene description for grasping using a parallel-plate gripper. We evaluate the accuracy of grasp detection and instance segmentation on challenging robotic picking datasets, namely Sil\'eane and OCID_grasp, and show the benefit of joint grasp detection and segmentation on a real-world robotic picking task.
End-to-end Trainable Deep Neural Network for Robotic Grasp Detection and Semantic Segmentation from RGB
Jul 12, 2021
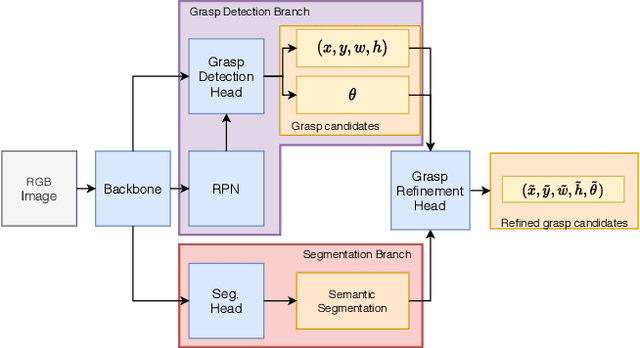


In this work, we introduce a novel, end-to-end trainable CNN-based architecture to deliver high quality results for grasp detection suitable for a parallel-plate gripper, and semantic segmentation. Utilizing this, we propose a novel refinement module that takes advantage of previously calculated grasp detection and semantic segmentation and further increases grasp detection accuracy. Our proposed network delivers state-of-the-art accuracy on two popular grasp dataset, namely Cornell and Jacquard. As additional contribution, we provide a novel dataset extension for the OCID dataset, making it possible to evaluate grasp detection in highly challenging scenes. Using this dataset, we show that semantic segmentation can additionally be used to assign grasp candidates to object classes, which can be used to pick specific objects in the scene.