 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeORBIT: A Unified Simulation Framework for Interactive Robot Learning Environments
Jan 10, 2023



We present ORBIT, a unified and modular framework for robot learning powered by NVIDIA Isaac Sim. It offers a modular design to easily and efficiently create robotic environments with photo-realistic scenes and fast and accurate rigid and deformable body simulation. With ORBIT, we provide a suite of benchmark tasks of varying difficulty -- from single-stage cabinet opening and cloth folding to multi-stage tasks such as room reorganization. To support working with diverse observations and action spaces, we include fixed-arm and mobile manipulators with different physically-based sensors and motion generators. ORBIT allows training reinforcement learning policies and collecting large demonstration datasets from hand-crafted or expert solutions in a matter of minutes by leveraging GPU-based parallelization. In summary, we offer an open-sourced framework that readily comes with 16 robotic platforms, 4 sensor modalities, 10 motion generators, more than 20 benchmark tasks, and wrappers to 4 learning libraries. With this framework, we aim to support various research areas, including representation learning, reinforcement learning, imitation learning, and task and motion planning. We hope it helps establish interdisciplinary collaborations in these communities, and its modularity makes it easily extensible for more tasks and applications in the future. For videos, documentation, and code: https://isaac-orbit.github.io/.
Geometric Fabrics: Generalizing Classical Mechanics to Capture the Physics of Behavior
Sep 21, 2021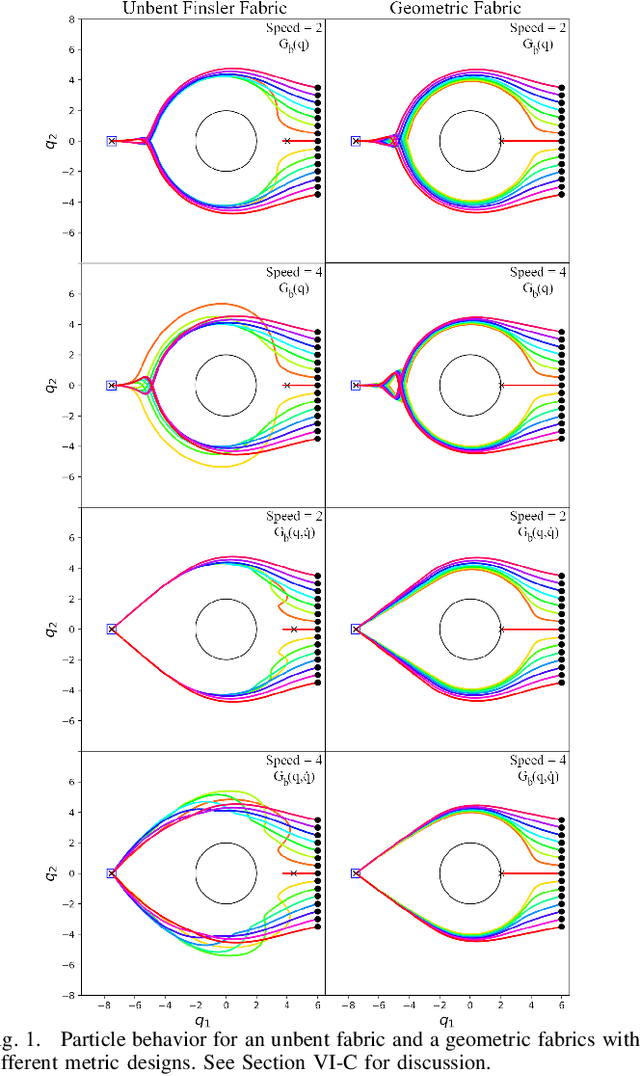
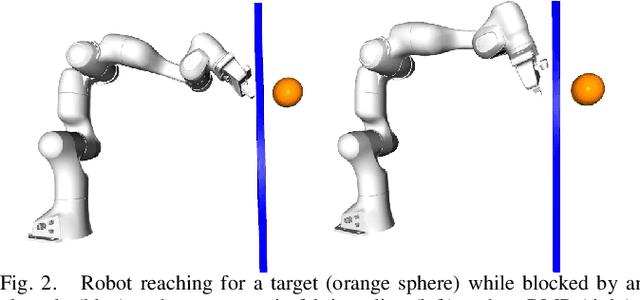
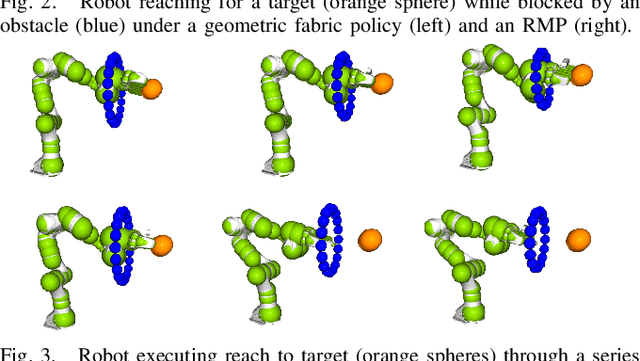
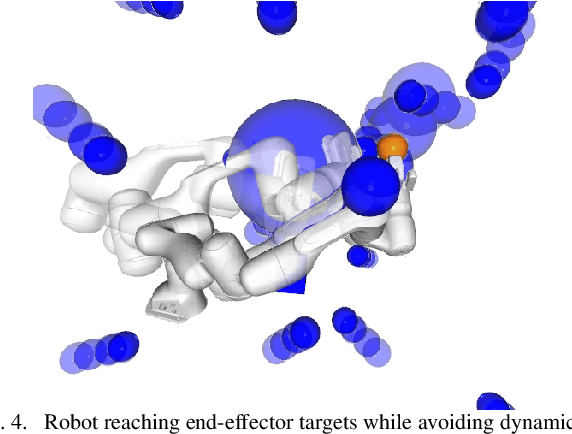
Classical mechanical systems are central to controller design in energy shaping methods of geometric control. However, their expressivity is limited by position-only metrics and the intimate link between metric and geometry. Recent work on Riemannian Motion Policies (RMPs) has shown that shedding these restrictions results in powerful design tools, but at the expense of theoretical guarantees. In this work, we generalize classical mechanics to what we call geometric fabrics, whose expressivity and theory enable the design of systems that outperform RMPs in practice. Geometric fabrics strictly generalize classical mechanics forming a new physics of behavior by first generalizing them to Finsler geometries and then explicitly bending them to shape their behavior. We develop the theory of fabrics and present both a collection of controlled experiments examining their theoretical properties and a set of robot system experiments showing improved performance over a well-engineered and hardened implementation of RMPs, our current state-of-the-art in controller design.
GLiDE: Generalizable Quadrupedal Locomotion in Diverse Environments with a Centroidal Model
Apr 22, 2021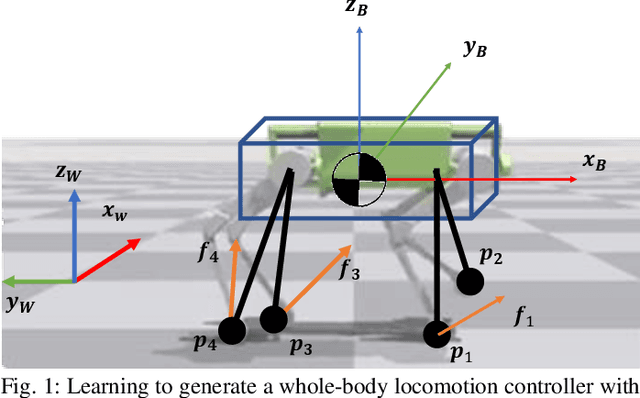
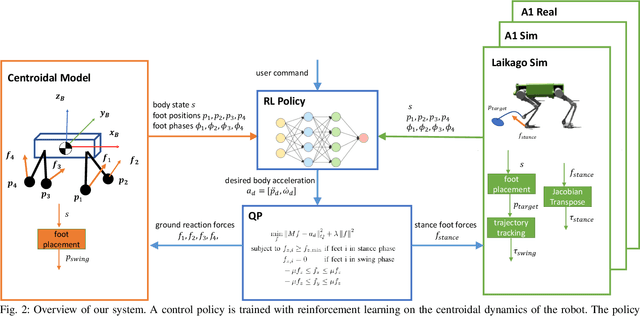

Model-free reinforcement learning (RL) for legged locomotion commonly relies on a physics simulator that can accurately predict the behaviors of every degree of freedom of the robot. In contrast, approximate reduced-order models are often sufficient for many model-based control strategies. In this work we explore how RL can be effectively used with a centroidal model to generate robust control policies for quadrupedal locomotion. Advantages over RL with a full-order model include a simple reward structure, reduced computational costs, and robust sim-to-real transfer. We further show the potential of the method by demonstrating stepping-stone locomotion, two-legged in-place balance, balance beam locomotion, and sim-to-real transfer without further adaptations. Additional Results: https://www.pair.toronto.edu/glide-quadruped/.
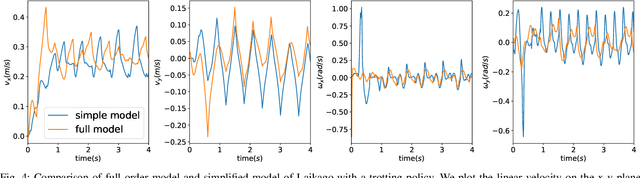
Dynamics Randomization Revisited:A Case Study for Quadrupedal Locomotion
Nov 04, 2020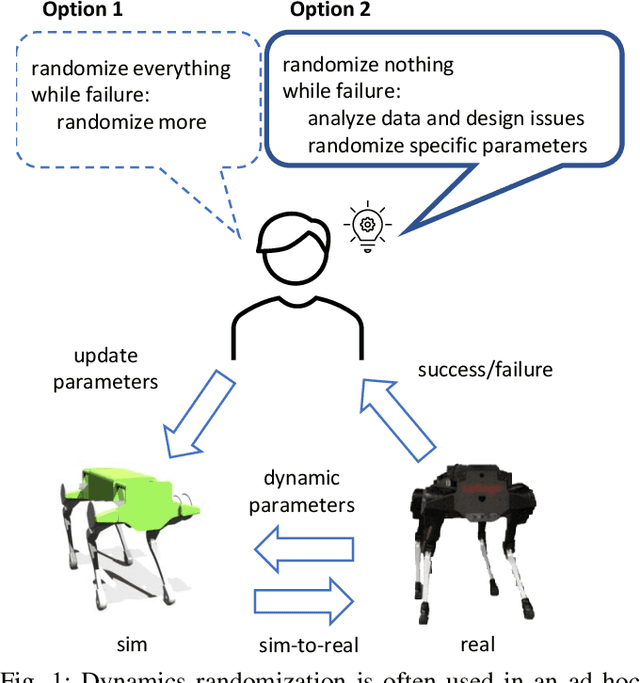
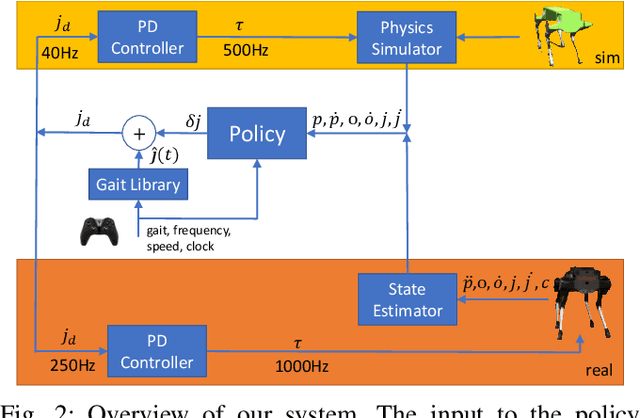

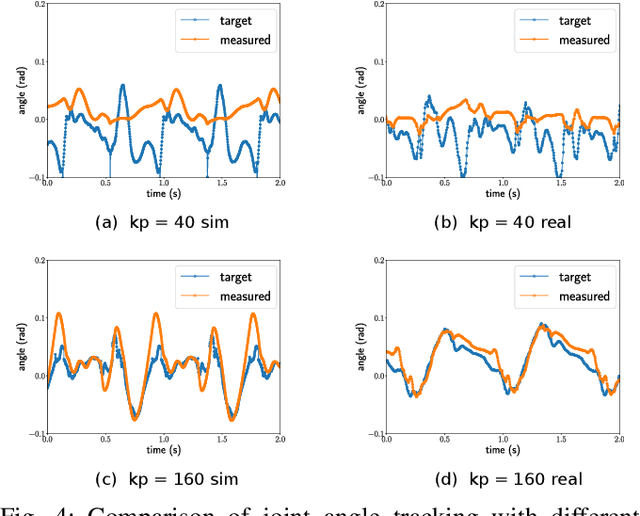
Understanding the gap between simulation andreality is critical for reinforcement learning with legged robots,which are largely trained in simulation. However, recent workhas resulted in sometimes conflicting conclusions with regardto which factors are important for success, including therole of dynamics randomization. In this paper, we aim toprovide clarity and understanding on the role of dynamicsrandomization in learning robust locomotion policies for theLaikago quadruped robot. Surprisingly, in contrast to priorwork with the same robot model, we find that direct sim-to-real transfer is possible without dynamics randomizationor on-robot adaptation schemes. We conduct extensive abla-tion studies in a sim-to-sim setting to understand the keyissues underlying successful policy transfer, including otherdesign decisions that can impact policy robustness. We furtherground our conclusions via sim-to-real experiments with variousgaits, speeds, and stepping frequencies. Additional Details: https://www.pair.toronto.edu/understanding-dr/.
Learning a Contact-Adaptive Controller for Robust, Efficient Legged Locomotion
Oct 05, 2020
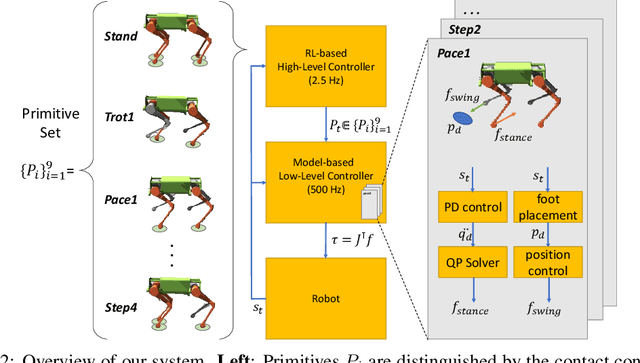

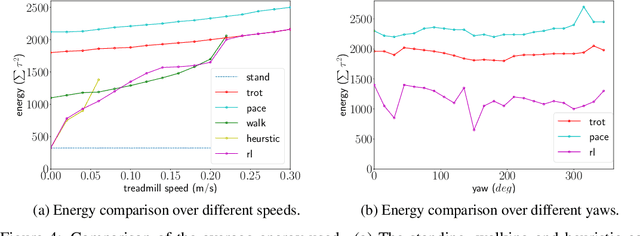
We present a hierarchical framework that combines model-based control and reinforcement learning (RL) to synthesize robust controllers for a quadruped (the Unitree Laikago). The system consists of a high-level controller that learns to choose from a set of primitives in response to changes in the environment and a low-level controller that utilizes an established control method to robustly execute the primitives. Our framework learns a controller that can adapt to challenging environmental changes on the fly, including novel scenarios not seen during training. The learned controller is up to 85~percent more energy efficient and is more robust compared to baseline methods. We also deploy the controller on a physical robot without any randomization or adaptation scheme.