 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning-Based Verification of Stochastic Dynamical Systems with Neural Network Policies
Paper and Code
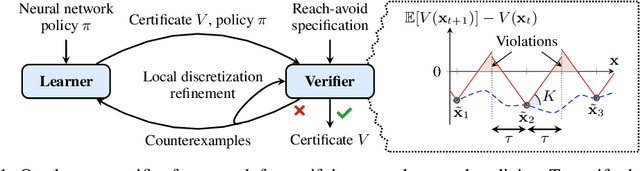

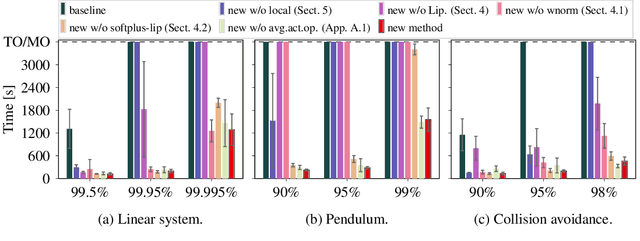

We consider the verification of neural network policies for reach-avoid control tasks in stochastic dynamical systems. We use a verification procedure that trains another neural network, which acts as a certificate proving that the policy satisfies the task. For reach-avoid tasks, it suffices to show that this certificate network is a reach-avoid supermartingale (RASM). As our main contribution, we significantly accelerate algorithmic approaches for verifying that a neural network is indeed a RASM. The main bottleneck of these approaches is the discretization of the state space of the dynamical system. The following two key contributions allow us to use a coarser discretization than existing approaches. First, we present a novel and fast method to compute tight upper bounds on Lipschitz constants of neural networks based on weighted norms. We further improve these bounds on Lipschitz constants based on the characteristics of the certificate network. Second, we integrate an efficient local refinement scheme that dynamically refines the state space discretization where necessary. Our empirical evaluation shows the effectiveness of our approach for verifying neural network policies in several benchmarks and trained with different reinforcement learning algorithms.