 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Shielding for Safe Reinforcement Learning
May 29, 2026Shielding is an effective approach to formally guarantee the safety of reinforcement learning agents in Markov decision processes (MDPs). However, existing shielding techniques typically assume knowledge of the safety-relevant transition dynamics - a requirement that is seldom met in practice. To address this limitation, we introduce a novel shielding framework for robust MDPs (RMDPs), i.e., MDPs with sets of transition probabilities. We define safety as the satisfaction of a linear temporal logic (LTL) formula with a certain threshold probability under the worst-case transition probabilities of the RMDP. We prove that our shielding framework is both sound and optimal for the RMDP: every policy admissible by the shield is safe, and conversely, every safe RMDP policy is admissible by the shield. We combine our approach with existing sampling methods for learning transition probabilities of MDPs with probably approximately correct (PAC) guarantees. This combination enables the construction of shields for MDPs that, with high confidence, guarantee safety while remaining minimally restrictive. Our experiments show that our shields for learned RMDPs guarantee safety in unknown MDPs while recovering strong expected return as the number of samples increases.
Scalable Verification of Neural Control Barrier Functions Using Linear Bound Propagation
Nov 09, 2025
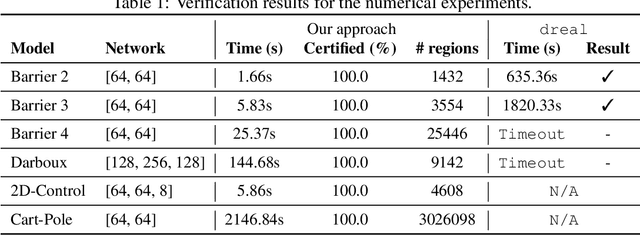
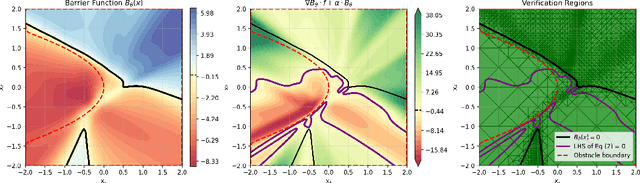
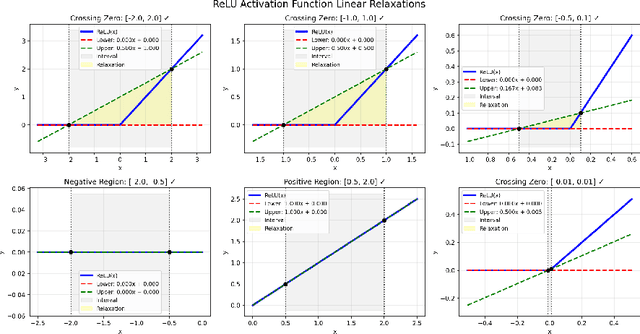
Control barrier functions (CBFs) are a popular tool for safety certification of nonlinear dynamical control systems. Recently, CBFs represented as neural networks have shown great promise due to their expressiveness and applicability to a broad class of dynamics and safety constraints. However, verifying that a trained neural network is indeed a valid CBF is a computational bottleneck that limits the size of the networks that can be used. To overcome this limitation, we present a novel framework for verifying neural CBFs based on piecewise linear upper and lower bounds on the conditions required for a neural network to be a CBF. Our approach is rooted in linear bound propagation (LBP) for neural networks, which we extend to compute bounds on the gradients of the network. Combined with McCormick relaxation, we derive linear upper and lower bounds on the CBF conditions, thereby eliminating the need for computationally expensive verification procedures. Our approach applies to arbitrary control-affine systems and a broad range of nonlinear activation functions. To reduce conservatism, we develop a parallelizable refinement strategy that adaptively refines the regions over which these bounds are computed. Our approach scales to larger neural networks than state-of-the-art verification procedures for CBFs, as demonstrated by our numerical experiments.
Best-Effort Policies for Robust Markov Decision Processes
Aug 11, 2025We study the common generalization of Markov decision processes (MDPs) with sets of transition probabilities, known as robust MDPs (RMDPs). A standard goal in RMDPs is to compute a policy that maximizes the expected return under an adversarial choice of the transition probabilities. If the uncertainty in the probabilities is independent between the states, known as s-rectangularity, such optimal robust policies can be computed efficiently using robust value iteration. However, there might still be multiple optimal robust policies, which, while equivalent with respect to the worst-case, reflect different expected returns under non-adversarial choices of the transition probabilities. Hence, we propose a refined policy selection criterion for RMDPs, drawing inspiration from the notions of dominance and best-effort in game theory. Instead of seeking a policy that only maximizes the worst-case expected return, we additionally require the policy to achieve a maximal expected return under different (i.e., not fully adversarial) transition probabilities. We call such a policy an optimal robust best-effort (ORBE) policy. We prove that ORBE policies always exist, characterize their structure, and present an algorithm to compute them with a small overhead compared to standard robust value iteration. ORBE policies offer a principled tie-breaker among optimal robust policies. Numerical experiments show the feasibility of our approach.
Robust Markov Decision Processes: A Place Where AI and Formal Methods Meet
Nov 18, 2024Markov decision processes (MDPs) are a standard model for sequential decision-making problems and are widely used across many scientific areas, including formal methods and artificial intelligence (AI). MDPs do, however, come with the restrictive assumption that the transition probabilities need to be precisely known. Robust MDPs (RMDPs) overcome this assumption by instead defining the transition probabilities to belong to some uncertainty set. We present a gentle survey on RMDPs, providing a tutorial covering their fundamentals. In particular, we discuss RMDP semantics and how to solve them by extending standard MDP methods such as value iteration and policy iteration. We also discuss how RMDPs relate to other models and how they are used in several contexts, including reinforcement learning and abstraction techniques. We conclude with some challenges for future work on RMDPs.
Learning-Based Verification of Stochastic Dynamical Systems with Neural Network Policies
Jun 02, 2024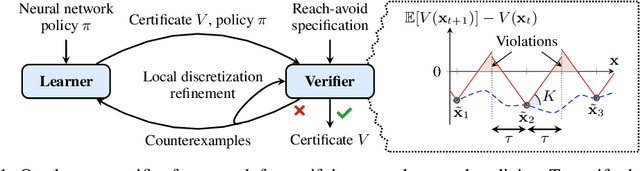

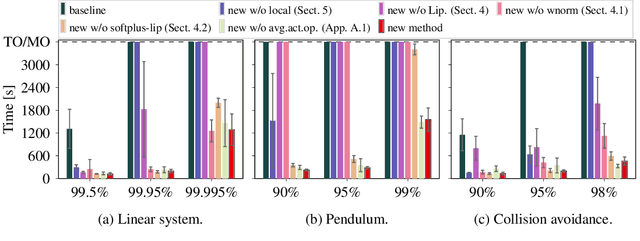

We consider the verification of neural network policies for reach-avoid control tasks in stochastic dynamical systems. We use a verification procedure that trains another neural network, which acts as a certificate proving that the policy satisfies the task. For reach-avoid tasks, it suffices to show that this certificate network is a reach-avoid supermartingale (RASM). As our main contribution, we significantly accelerate algorithmic approaches for verifying that a neural network is indeed a RASM. The main bottleneck of these approaches is the discretization of the state space of the dynamical system. The following two key contributions allow us to use a coarser discretization than existing approaches. First, we present a novel and fast method to compute tight upper bounds on Lipschitz constants of neural networks based on weighted norms. We further improve these bounds on Lipschitz constants based on the characteristics of the certificate network. Second, we integrate an efficient local refinement scheme that dynamically refines the state space discretization where necessary. Our empirical evaluation shows the effectiveness of our approach for verifying neural network policies in several benchmarks and trained with different reinforcement learning algorithms.
Correct-by-Construction Control for Stochastic and Uncertain Dynamical Models via Formal Abstractions
Nov 16, 2023Automated synthesis of correct-by-construction controllers for autonomous systems is crucial for their deployment in safety-critical scenarios. Such autonomous systems are naturally modeled as stochastic dynamical models. The general problem is to compute a controller that provably satisfies a given task, represented as a probabilistic temporal logic specification. However, factors such as stochastic uncertainty, imprecisely known parameters, and hybrid features make this problem challenging. We have developed an abstraction framework that can be used to solve this problem under various modeling assumptions. Our approach is based on a robust finite-state abstraction of the stochastic dynamical model in the form of a Markov decision process with intervals of probabilities (iMDP). We use state-of-the-art verification techniques to compute an optimal policy on the iMDP with guarantees for satisfying the given specification. We then show that, by construction, we can refine this policy into a feedback controller for which these guarantees carry over to the dynamical model. In this short paper, we survey our recent research in this area and highlight two challenges (related to scalability and dealing with nonlinear dynamics) that we aim to address with our ongoing research.
* In Proceedings FMAS 2023, arXiv:2311.08987. arXiv admin note: text overlap with arXiv:2301.01526
Efficient Sensitivity Analysis for Parametric Robust Markov Chains
May 01, 2023We provide a novel method for sensitivity analysis of parametric robust Markov chains. These models incorporate parameters and sets of probability distributions to alleviate the often unrealistic assumption that precise probabilities are available. We measure sensitivity in terms of partial derivatives with respect to the uncertain transition probabilities regarding measures such as the expected reward. As our main contribution, we present an efficient method to compute these partial derivatives. To scale our approach to models with thousands of parameters, we present an extension of this method that selects the subset of $k$ parameters with the highest partial derivative. Our methods are based on linear programming and differentiating these programs around a given value for the parameters. The experiments show the applicability of our approach on models with over a million states and thousands of parameters. Moreover, we embed the results within an iterative learning scheme that profits from having access to a dedicated sensitivity analysis.
Decision-Making Under Uncertainty: Beyond Probabilities
Mar 10, 2023This position paper reflects on the state-of-the-art in decision-making under uncertainty. A classical assumption is that probabilities can sufficiently capture all uncertainty in a system. In this paper, the focus is on the uncertainty that goes beyond this classical interpretation, particularly by employing a clear distinction between aleatoric and epistemic uncertainty. The paper features an overview of Markov decision processes (MDPs) and extensions to account for partial observability and adversarial behavior. These models sufficiently capture aleatoric uncertainty but fail to account for epistemic uncertainty robustly. Consequently, we present a thorough overview of so-called uncertainty models that exhibit uncertainty in a more robust interpretation. We show several solution techniques for both discrete and continuous models, ranging from formal verification, over control-based abstractions, to reinforcement learning. As an integral part of this paper, we list and discuss several key challenges that arise when dealing with rich types of uncertainty in a model-based fashion.
Robust Control for Dynamical Systems With Non-Gaussian Noise via Formal Abstractions
Jan 04, 2023



Controllers for dynamical systems that operate in safety-critical settings must account for stochastic disturbances. Such disturbances are often modeled as process noise in a dynamical system, and common assumptions are that the underlying distributions are known and/or Gaussian. In practice, however, these assumptions may be unrealistic and can lead to poor approximations of the true noise distribution. We present a novel controller synthesis method that does not rely on any explicit representation of the noise distributions. In particular, we address the problem of computing a controller that provides probabilistic guarantees on safely reaching a target, while also avoiding unsafe regions of the state space. First, we abstract the continuous control system into a finite-state model that captures noise by probabilistic transitions between discrete states. As a key contribution, we adapt tools from the scenario approach to compute probably approximately correct (PAC) bounds on these transition probabilities, based on a finite number of samples of the noise. We capture these bounds in the transition probability intervals of a so-called interval Markov decision process (iMDP). This iMDP is, with a user-specified confidence probability, robust against uncertainty in the transition probabilities, and the tightness of the probability intervals can be controlled through the number of samples. We use state-of-the-art verification techniques to provide guarantees on the iMDP and compute a controller for which these guarantees carry over to the original control system. In addition, we develop a tailored computational scheme that reduces the complexity of the synthesis of these guarantees on the iMDP. Benchmarks on realistic control systems show the practical applicability of our method, even when the iMDP has hundreds of millions of transitions.
Formal Controller Synthesis for Markov Jump Linear Systems with Uncertain Dynamics
Dec 01, 2022



Automated synthesis of provably correct controllers for cyber-physical systems is crucial for deploying these systems in safety-critical scenarios. However, their hybrid features and stochastic or unknown behaviours make this synthesis problem challenging. In this paper, we propose a method for synthesizing controllers for Markov jump linear systems (MJLSs), a particular class of cyber-physical systems, that certifiably satisfy a requirement expressed as a specification in probabilistic computation tree logic (PCTL). An MJLS consists of a finite set of linear dynamics with unknown additive disturbances, where jumps between these modes are governed by a Markov decision process (MDP). We consider both the case where the transition function of this MDP is given by probability intervals or where it is completely unknown. Our approach is based on generating a finite-state abstraction which captures both the discrete and the continuous behaviour of the original system. We formalise such abstraction as an interval Markov decision process (iMDP): intervals of transition probabilities are computed using sampling techniques from the so-called "scenario approach", resulting in a probabilistically sound approximation of the MJLS. This iMDP abstracts both the jump dynamics between modes, as well as the continuous dynamics within the modes. To demonstrate the efficacy of our technique, we apply our method to multiple realistic benchmark problems, in particular, temperature control, and aerial vehicle delivery problems.