 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMissingness-MDPs: Bridging the Theory of Missing Data and POMDPs
May 12, 2026We introduce missingness-MDPs (miss-MDPs), a novel subclass of partially observable Markov decision processes (POMDPs) that incorporates the theory of missing data. A miss-MDP is a POMDP whose observation function is a missingness function, specifying the probability that individual state features are missing (i.e., unobserved) at a time step. The literature distinguishes three canonical missingness types: missing (1) completely at random (MCAR), (2) at random (MAR), and (3) not at random (MNAR). Our planning problem is to compute near-optimal policies for a miss-MDP with an unknown missingness function, given a dataset of action-observation trajectories. Achieving such optimality guarantees for policies requires learning the missingness function from data, which is infeasible for general POMDPs. To overcome this challenge, we exploit the structural properties of different missingness types to derive probably approximately correct (PAC) algorithms for learning the missingness function. These algorithms yield an approximate but fully specified miss-MDP that we solve using off-the-shelf planning methods. We prove that, with high probability, the resulting policies are epsilon-optimal in the true miss-MDP. Empirical results confirm the theory and demonstrate superior performance of our approach over two model-free POMDP methods.
Targeted Adversarial Attacks on Deep Reinforcement Learning Policies via Model Checking
Dec 10, 2022Deep Reinforcement Learning (RL) agents are susceptible to adversarial noise in their observations that can mislead their policies and decrease their performance. However, an adversary may be interested not only in decreasing the reward, but also in modifying specific temporal logic properties of the policy. This paper presents a metric that measures the exact impact of adversarial attacks against such properties. We use this metric to craft optimal adversarial attacks. Furthermore, we introduce a model checking method that allows us to verify the robustness of RL policies against adversarial attacks. Our empirical analysis confirms (1) the quality of our metric to craft adversarial attacks against temporal logic properties, and (2) that we are able to concisely assess a system's robustness against attacks.
Safe Reinforcement Learning From Pixels Using a Stochastic Latent Representation
Oct 02, 2022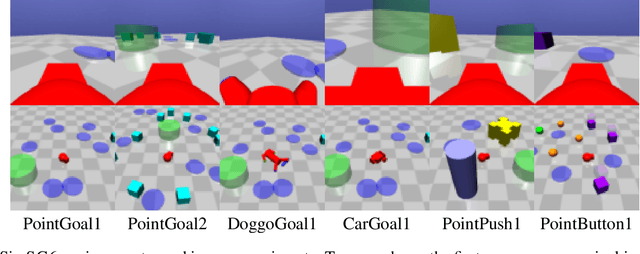
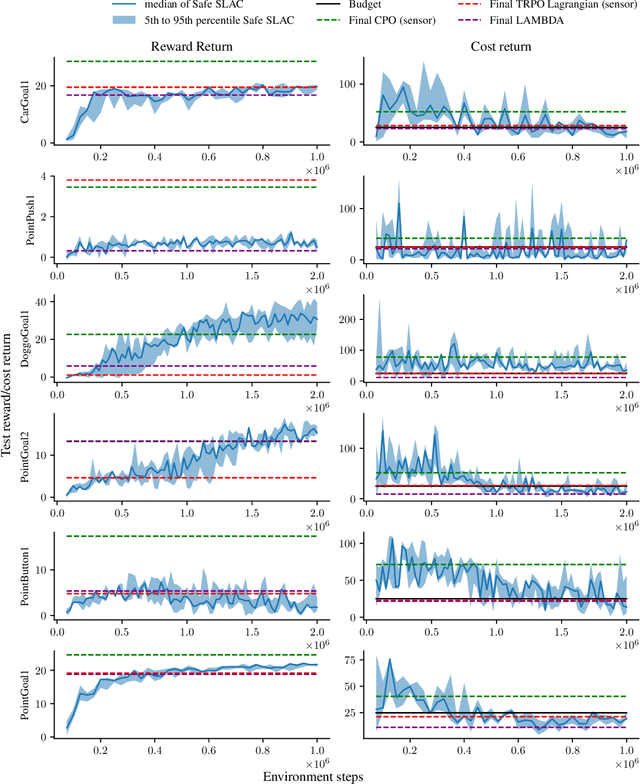
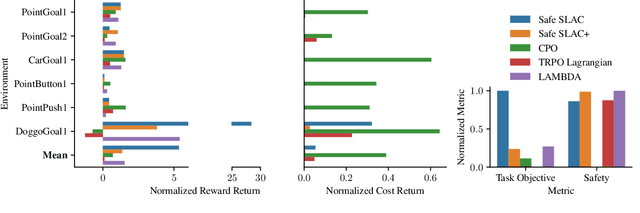
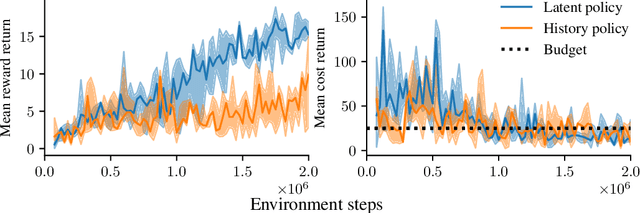
We address the problem of safe reinforcement learning from pixel observations. Inherent challenges in such settings are (1) a trade-off between reward optimization and adhering to safety constraints, (2) partial observability, and (3) high-dimensional observations. We formalize the problem in a constrained, partially observable Markov decision process framework, where an agent obtains distinct reward and safety signals. To address the curse of dimensionality, we employ a novel safety critic using the stochastic latent actor-critic (SLAC) approach. The latent variable model predicts rewards and safety violations, and we use the safety critic to train safe policies. Using well-known benchmark environments, we demonstrate competitive performance over existing approaches with respects to computational requirements, final reward return, and satisfying the safety constraints.