 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeurosymbolic Inference On Foundation Models For Remote Sensing Text-to-image Retrieval With Complex Queries
Dec 16, 2025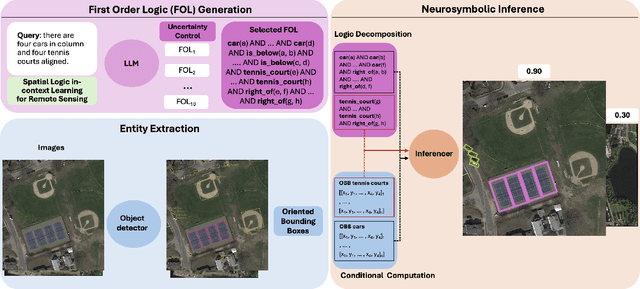
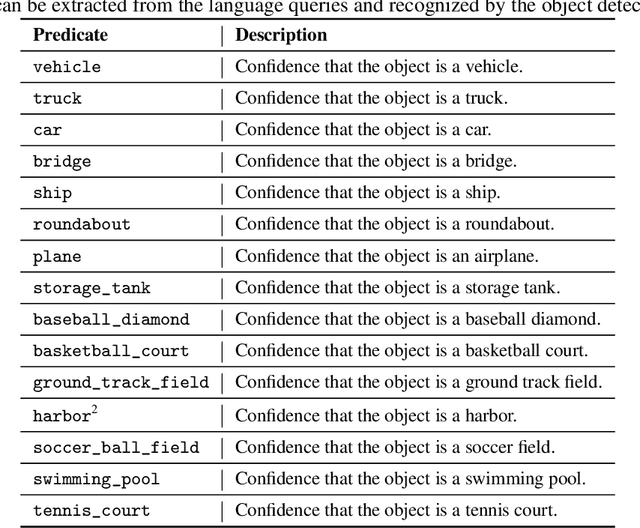

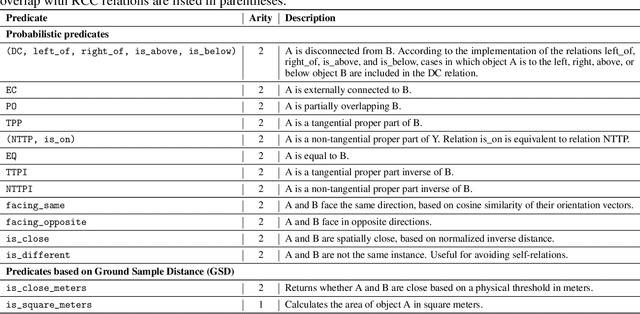
Text-to-image retrieval in remote sensing (RS) has advanced rapidly with the rise of large vision-language models (LVLMs) tailored for aerial and satellite imagery, culminating in remote sensing large vision-language models (RS-LVLMS). However, limited explainability and poor handling of complex spatial relations remain key challenges for real-world use. To address these issues, we introduce RUNE (Reasoning Using Neurosymbolic Entities), an approach that combines Large Language Models (LLMs) with neurosymbolic AI to retrieve images by reasoning over the compatibility between detected entities and First-Order Logic (FOL) expressions derived from text queries. Unlike RS-LVLMs that rely on implicit joint embeddings, RUNE performs explicit reasoning, enhancing performance and interpretability. For scalability, we propose a logic decomposition strategy that operates on conditioned subsets of detected entities, guaranteeing shorter execution time compared to neural approaches. Rather than using foundation models for end-to-end retrieval, we leverage them only to generate FOL expressions, delegating reasoning to a neurosymbolic inference module. For evaluation we repurpose the DOTA dataset, originally designed for object detection, by augmenting it with more complex queries than in existing benchmarks. We show the LLM's effectiveness in text-to-logic translation and compare RUNE with state-of-the-art RS-LVLMs, demonstrating superior performance. We introduce two metrics, Retrieval Robustness to Query Complexity (RRQC) and Retrieval Robustness to Image Uncertainty (RRIU), which evaluate performance relative to query complexity and image uncertainty. RUNE outperforms joint-embedding models in complex RS retrieval tasks, offering gains in performance, robustness, and explainability. We show RUNE's potential for real-world RS applications through a use case on post-flood satellite image retrieval.
Adversarial Patch Camouflage against Aerial Detection
Aug 31, 2020
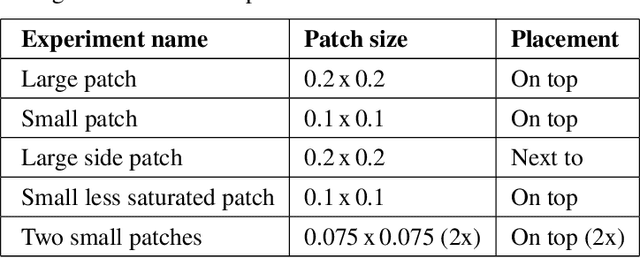

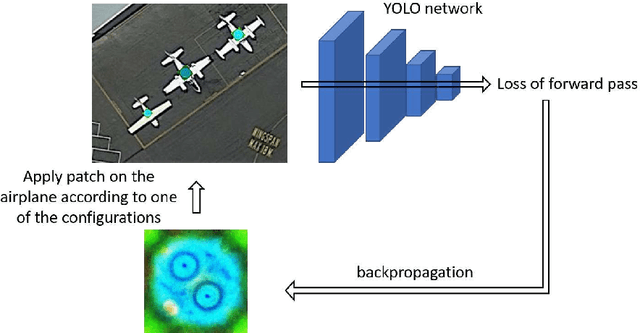
Detection of military assets on the ground can be performed by applying deep learning-based object detectors on drone surveillance footage. The traditional way of hiding military assets from sight is camouflage, for example by using camouflage nets. However, large assets like planes or vessels are difficult to conceal by means of traditional camouflage nets. An alternative type of camouflage is the direct misleading of automatic object detectors. Recently, it has been observed that small adversarial changes applied to images of the object can produce erroneous output by deep learning-based detectors. In particular, adversarial attacks have been successfully demonstrated to prohibit person detections in images, requiring a patch with a specific pattern held up in front of the person, thereby essentially camouflaging the person for the detector. Research into this type of patch attacks is still limited and several questions related to the optimal patch configuration remain open. This work makes two contributions. First, we apply patch-based adversarial attacks for the use case of unmanned aerial surveillance, where the patch is laid on top of large military assets, camouflaging them from automatic detectors running over the imagery. The patch can prevent automatic detection of the whole object while only covering a small part of it. Second, we perform several experiments with different patch configurations, varying their size, position, number and saliency. Our results show that adversarial patch attacks form a realistic alternative to traditional camouflage activities, and should therefore be considered in the automated analysis of aerial surveillance imagery.