 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGender mobility in the labor market with skills-based matching models
Jul 17, 2023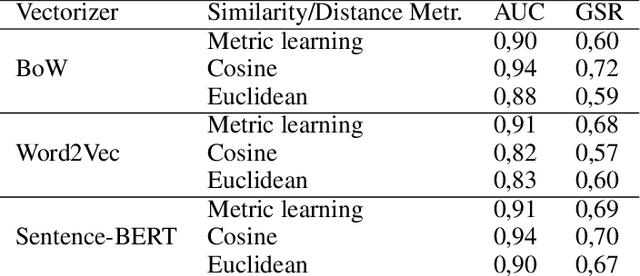
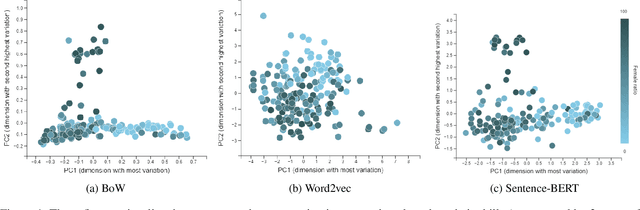
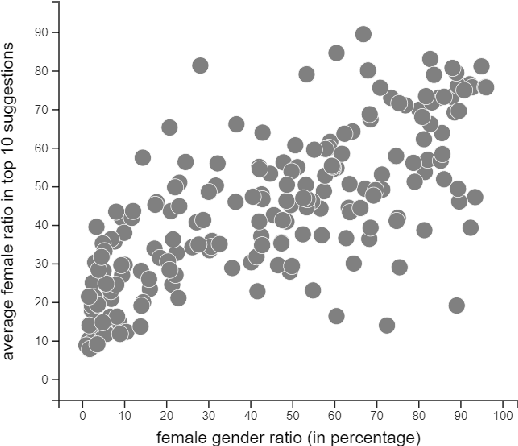
Skills-based matching promises mobility of workers between different sectors and occupations in the labor market. In this case, job seekers can look for jobs they do not yet have experience in, but for which they do have relevant skills. Currently, there are multiple occupations with a skewed gender distribution. For skills-based matching, it is unclear if and how a shift in the gender distribution, which we call gender mobility, between occupations will be effected. It is expected that the skills-based matching approach will likely be data-driven, including computational language models and supervised learning methods. This work, first, shows the presence of gender segregation in language model-based skills representation of occupations. Second, we assess the use of these representations in a potential application based on simulated data, and show that the gender segregation is propagated by various data-driven skills-based matching models.These models are based on different language representations (bag of words, word2vec, and BERT), and distance metrics (static and machine learning-based). Accordingly, we show how skills-based matching approaches can be evaluated and compared on matching performance as well as on the risk of gender segregation. Making the gender segregation bias of models more explicit can help in generating healthy trust in the use of these models in practice.
Detection of anomalously emitting ships through deviations from predicted TROPOMI NO2 retrievals
Feb 24, 2023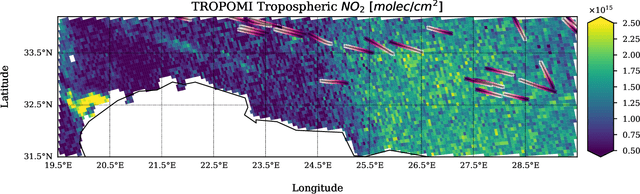


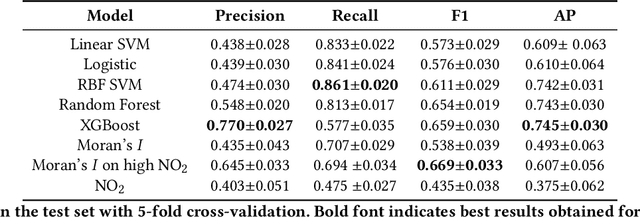
Starting from 2021, more demanding $\text{NO}_\text{x}$ emission restrictions were introduced for ships operating in the North and Baltic Sea waters. Since all methods currently used for ship compliance monitoring are financially and time demanding, it is important to prioritize the inspection of ships that have high chances of being non-compliant. The current state-of-the-art approach for a large-scale ship $\text{NO}_\text{2}$ estimation is a supervised machine learning-based segmentation of ship plumes on TROPOMI images. However, challenging data annotation and insufficiently complex ship emission proxy used for the validation limit the applicability of the model for ship compliance monitoring. In this study, we present a method for the automated selection of potentially non-compliant ships using a combination of machine learning models on TROPOMI/S5P satellite data. It is based on a proposed regression model predicting the amount of $\text{NO}_\text{2}$ that is expected to be produced by a ship with certain properties operating in the given atmospheric conditions. The model does not require manual labeling and is validated with TROPOMI data directly. The differences between the predicted and actual amount of produced $\text{NO}_\text{2}$ are integrated over different observations of the same ship in time and are used as a measure of the inspection worthiness of a ship. To assure the robustness of the results, we compare the obtained results with the results of the previously developed segmentation-based method. Ships that are also highly deviating in accordance with the segmentation method require further attention. If no other explanations can be found by checking the TROPOMI data, the respective ships are advised to be the candidates for inspection.
PERFEX: Classifier Performance Explanations for Trustworthy AI Systems
Dec 12, 2022Explainability of a classification model is crucial when deployed in real-world decision support systems. Explanations make predictions actionable to the user and should inform about the capabilities and limitations of the system. Existing explanation methods, however, typically only provide explanations for individual predictions. Information about conditions under which the classifier is able to support the decision maker is not available, while for instance information about when the system is not able to differentiate classes can be very helpful. In the development phase it can support the search for new features or combining models, and in the operational phase it supports decision makers in deciding e.g. not to use the system. This paper presents a method to explain the qualities of a trained base classifier, called PERFormance EXplainer (PERFEX). Our method consists of a meta tree learning algorithm that is able to predict and explain under which conditions the base classifier has a high or low error or any other classification performance metric. We evaluate PERFEX using several classifiers and datasets, including a case study with urban mobility data. It turns out that PERFEX typically has high meta prediction performance even if the base classifier is hardly able to differentiate classes, while giving compact performance explanations.
Supervised segmentation of NO2 plumes from individual ships using TROPOMI satellite data
Mar 14, 2022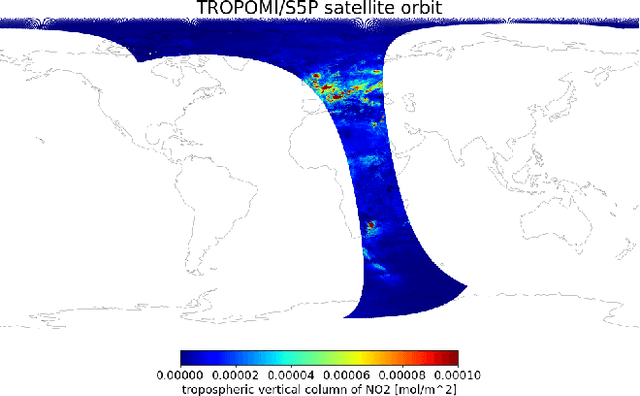
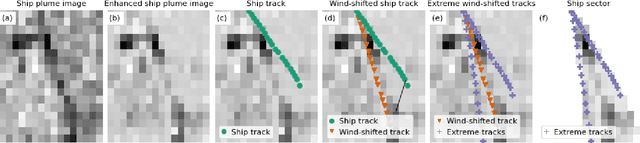

Starting from 2021, the International Maritime Organization significantly tightened the $\text{NO}_\text{x}$ emission requirements for ships entering the Baltic and North Sea waters. Since all methods currently used for the ships' compliance monitoring are costly and require proximity to the ship, the performance of a global and continuous monitoring of the emission standards' fulfillment has been impossible up to now. A promising approach is the use of remote sensing with the recently launched TROPOMI/S5P satellite. Due to its unprecedentedly high spatial resolution, it allows for the visual distinction of $\text{NO}_\text{2}$ plumes of individual ships. To successfully deploy a compliance monitoring system that is based on TROPOMI data, an automated procedure for the attribution of $\text{NO}_\text{2}$ to individual ships has to be developed. However, due to the extremely low signal-to-noise ratio, interference with the signal from other - often stronger - sources, and the absence of ground truth, the task is very challenging. In this study, we present an automated method for segmentation of plumes produced by individual ships using TROPOMI satellite data - a first step towards the automated procedure for global ship compliance monitoring. We develop a multivariate plume segmentation method based on various ships', wind's and spatial properties. For this, we propose to automatically define a region of interest - a ship sector that we normalize with respect to scale and orientation. We create a dataset, where each pixel has a label for belonging to the respective ship plume or not. We train five linear and nonlinear classifiers. The results show a significant improvement over the threshold-based baselines. Moreover, the aggregated $\text{NO}_\text{2}$ levels of the segmented plumes show high correlation with the theoretically derived measure of ship's emission potential.
Fair Tree Learning
Oct 25, 2021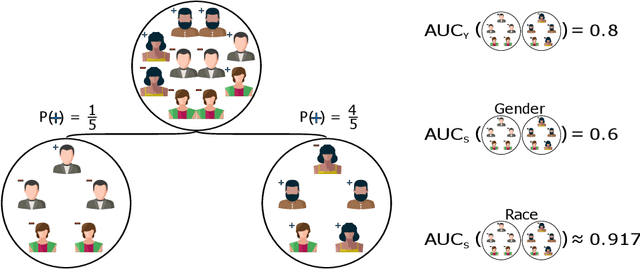
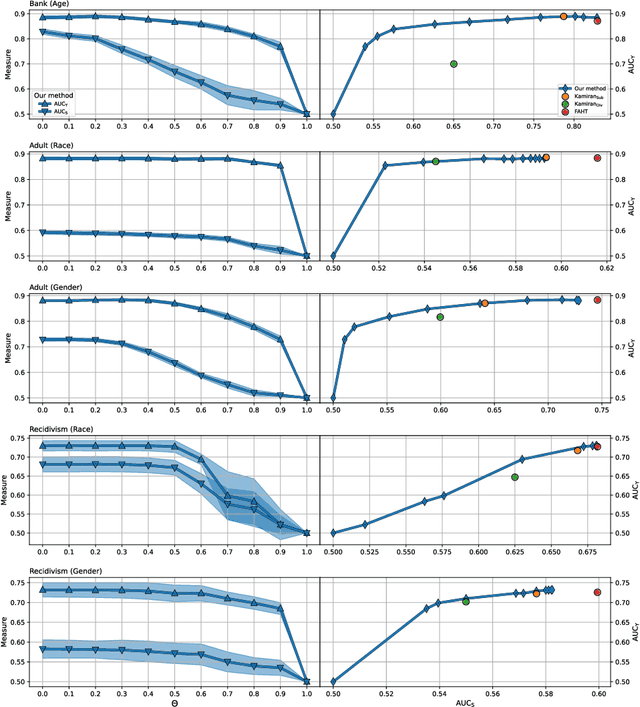
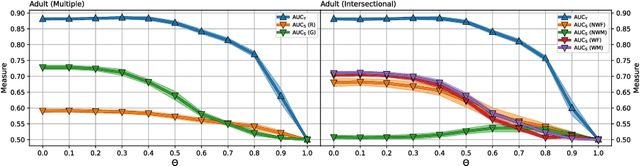
When dealing with sensitive data in automated data-driven decision-making, an important concern is to learn predictors with high performance towards a class label, whilst minimising for the discrimination towards some sensitive attribute, like gender or race, induced from biased data. Various hybrid optimisation criteria exist which combine classification performance with a fairness metric. However, while the threshold-free ROC-AUC is the standard for measuring traditional classification model performance, current fair decision tree methods only optimise for a fixed threshold on both the classification task as well as the fairness metric. Moreover, current tree learning frameworks do not allow for fair treatment with respect to multiple categories or multiple sensitive attributes. Lastly, the end-users of a fair model should be able to balance fairness and classification performance according to their specific ethical, legal, and societal needs. In this paper we address these shortcomings by proposing a threshold-independent fairness metric termed uniform demographic parity, and a derived splitting criterion entitled SCAFF -- Splitting Criterion AUC for Fairness -- towards fair decision tree learning, which extends to bagged and boosted frameworks. Compared to the state-of-the-art, our method provides three main advantages: (1) classifier performance and fairness are defined continuously instead of relying upon an, often arbitrary, decision threshold; (2) it leverages multiple sensitive attributes simultaneously, of which the values may be multicategorical; and (3) the unavoidable performance-fairness trade-off is tunable during learning. In our experiments, we demonstrate how SCAFF attains high predictive performance towards the class label and low discrimination with respect to binary, multicategorical, and multiple sensitive attributes, further substantiating our claims.