 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpot What Matters: Learning Context Using Graph Convolutional Networks for Weakly-Supervised Action Detection
Paper and Code
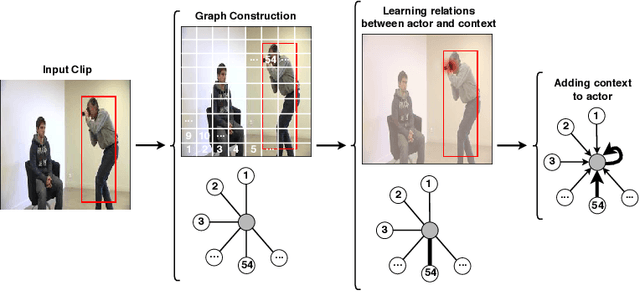
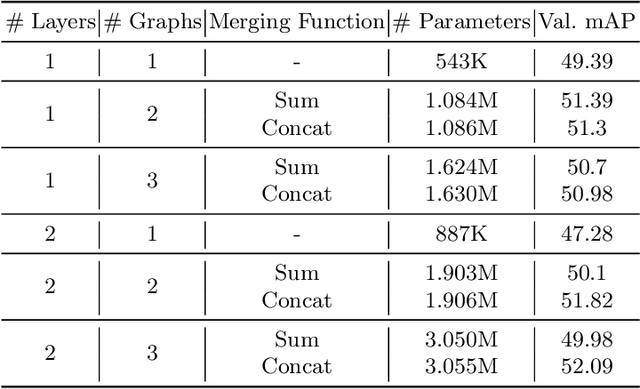
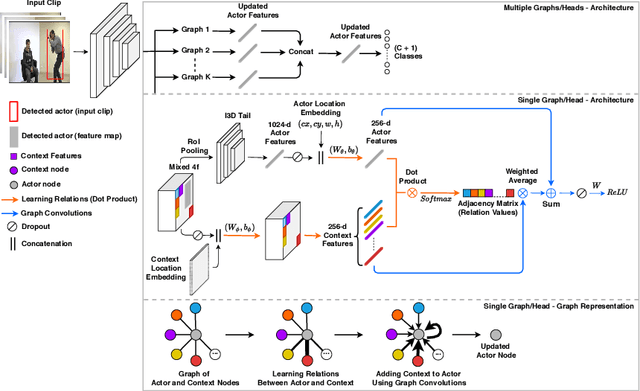
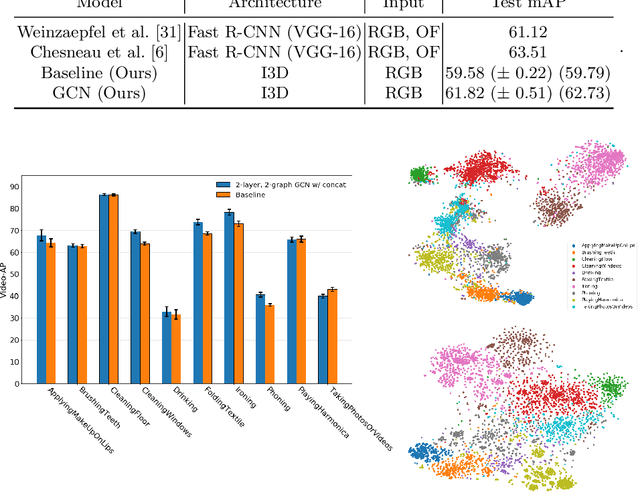
The dominant paradigm in spatiotemporal action detection is to classify actions using spatiotemporal features learned by 2D or 3D Convolutional Networks. We argue that several actions are characterized by their context, such as relevant objects and actors present in the video. To this end, we introduce an architecture based on self-attention and Graph Convolutional Networks in order to model contextual cues, such as actor-actor and actor-object interactions, to improve human action detection in video. We are interested in achieving this in a weakly-supervised setting, i.e. using as less annotations as possible in terms of action bounding boxes. Our model aids explainability by visualizing the learned context as an attention map, even for actions and objects unseen during training. We evaluate how well our model highlights the relevant context by introducing a quantitative metric based on recall of objects retrieved by attention maps. Our model relies on a 3D convolutional RGB stream, and does not require expensive optical flow computation. We evaluate our models on the DALY dataset, which consists of human-object interaction actions. Experimental results show that our contextualized approach outperforms a baseline action detection approach by more than 2 points in Video-mAP. Code is available at \url{https://github.com/micts/acgcn}