 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAssessing Brittleness of Image-Text Retrieval Benchmarks from Vision-Language Models Perspective
Paper and Code
Jul 25, 2024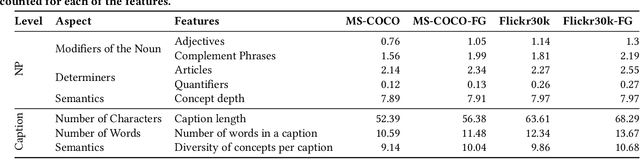
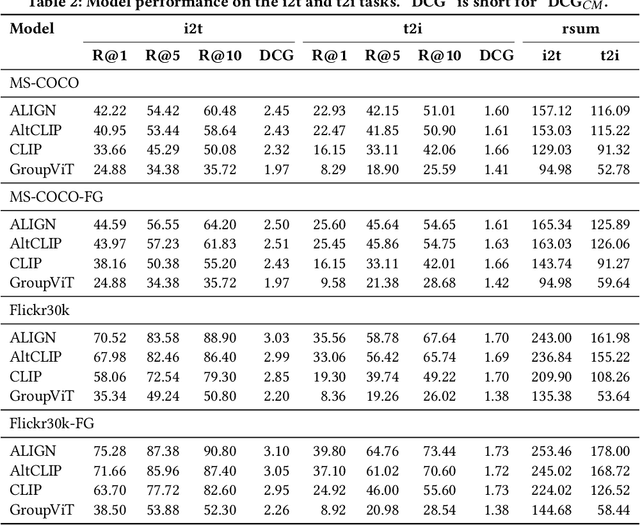
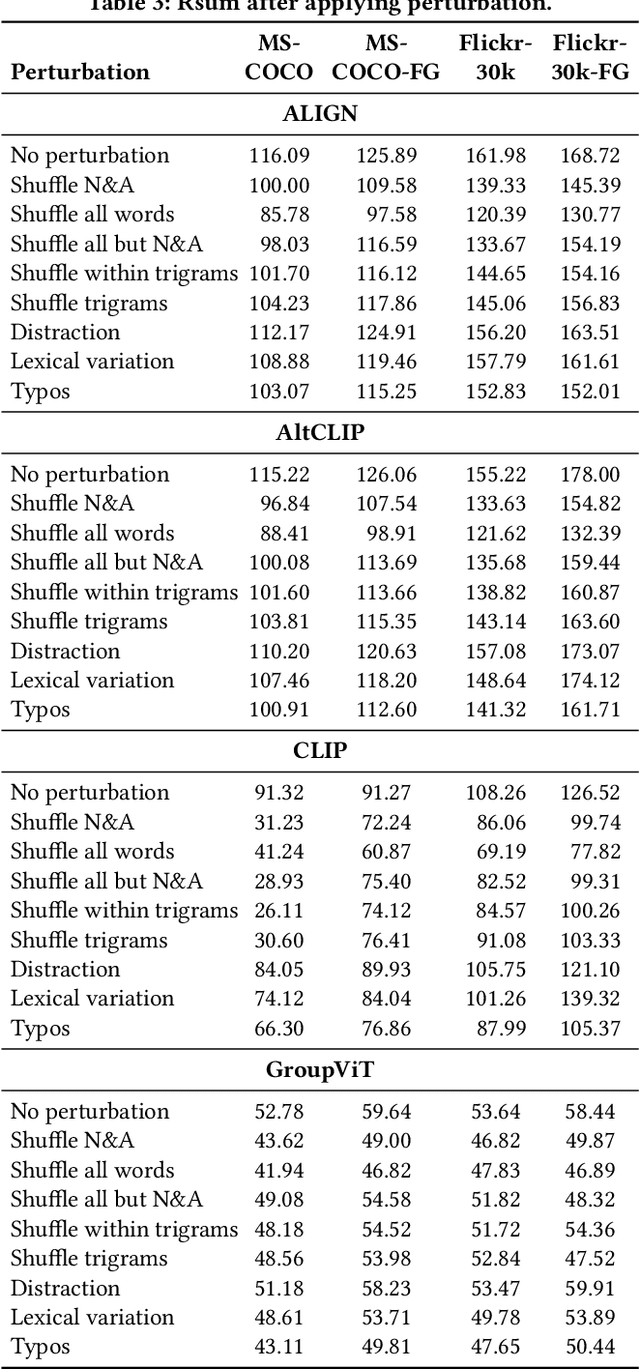

Image-text retrieval (ITR), an important task in information retrieval (IR), is driven by pretrained vision-language models (VLMs) that consistently achieve state-of-the-art performance. However, a significant challenge lies in the brittleness of existing ITR benchmarks. In standard datasets for the task, captions often provide broad summaries of scenes, neglecting detailed information about specific concepts. Additionally, the current evaluation setup assumes simplistic binary matches between images and texts and focuses on intra-modality rather than cross-modal relationships, which can lead to misinterpretations of model performance. Motivated by this gap, in this study, we focus on examining the brittleness of the ITR evaluation pipeline with a focus on concept granularity. We start by analyzing two common benchmarks, MS-COCO and Flickr30k, and compare them with their augmented versions, MS-COCO-FG and Flickr30k-FG, given a specified set of linguistic features capturing concept granularity. We discover that Flickr30k-FG and MS COCO-FG consistently achieve higher scores across all the selected features. To investigate the performance of VLMs on coarse and fine-grained datasets, we introduce a taxonomy of perturbations. We apply these perturbations to the selected datasets. We evaluate four state-of-the-art models - ALIGN, AltCLIP, CLIP, and GroupViT - on the standard and fine-grained datasets under zero-shot conditions, with and without the applied perturbations. The results demonstrate that although perturbations generally degrade model performance, the fine-grained datasets exhibit a smaller performance drop than their standard counterparts. Moreover, the relative performance drop across all setups is consistent across all models and datasets, indicating that the issue lies within the benchmarks. We conclude the paper by providing an agenda for improving ITR evaluation pipelines.