 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCHESTNUT: A QoS Dataset for Mobile Edge Environments
Oct 25, 2024Quality of Service (QoS) is an important metric to measure the performance of network services. Nowadays, it is widely used in mobile edge environments to evaluate the quality of service when mobile devices request services from edge servers. QoS usually involves multiple dimensions, such as bandwidth, latency, jitter, and data packet loss rate. However, most existing QoS datasets, such as the common WS-Dream dataset, focus mainly on static QoS metrics of network services and ignore dynamic attributes such as time and geographic location. This means they should have detailed the mobile device's location at the time of the service request or the chronological order in which the request was made. However, these dynamic attributes are crucial for understanding and predicting the actual performance of network services, as QoS performance typically fluctuates with time and geographic location. To this end, we propose a novel dataset that accurately records temporal and geographic location information on quality of service during the collection process, aiming to provide more accurate and reliable data to support future QoS prediction in mobile edge environments.
Target-Prompt Online Graph Collaborative Learning for Temporal QoS Prediction
Aug 20, 2024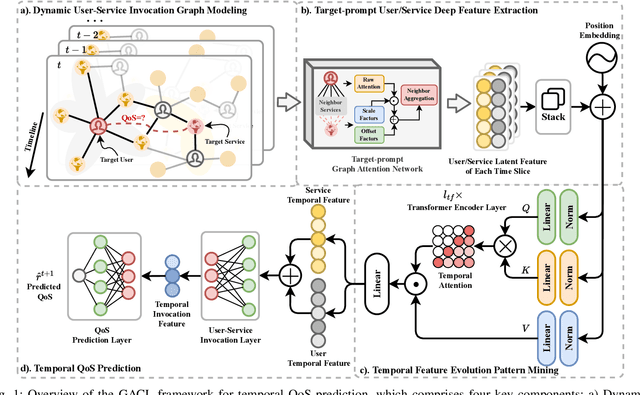
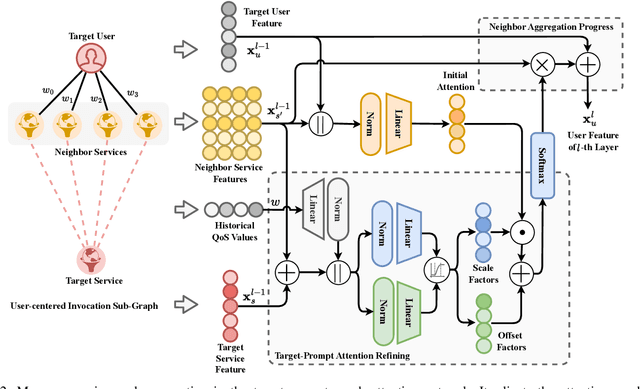

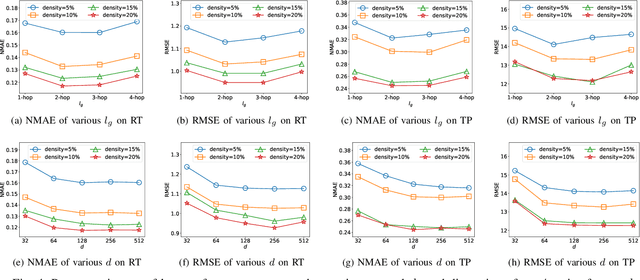
In service-oriented architecture, accurately predicting the Quality of Service (QoS) is vital for maintaining reliability and enhancing user satisfaction. However, current methods often neglect high-order latent collaborative relationships and fail to dynamically adjust feature learning for specific user-service invocations, which are critical for precise feature extraction. Moreover, relying on RNNs to capture QoS evolution limits the ability to detect long-term trends due to challenges in managing long-range dependencies. To address these issues, we propose the Target-Prompt Online Graph Collaborative Learning (TOGCL) framework for temporal QoS prediction. It leverages a dynamic user-service invocation graph to comprehensively model historical interactions. Building on this graph, it develops a target-prompt graph attention network to extract online deep latent features of users and services at each time slice, considering implicit target-neighboring collaborative relationships and historical QoS values. Additionally, a multi-layer Transformer encoder is employed to uncover temporal feature evolution patterns, enhancing temporal QoS prediction. Extensive experiments on the WS-DREAM dataset demonstrate that TOGCL significantly outperforms state-of-the-art methods across multiple metrics, achieving improvements of up to 38.80\%. These results underscore the effectiveness of TOGCL for temporal QoS prediction.
Large Language Model Meets Graph Neural Network in Knowledge Distillation
Feb 09, 2024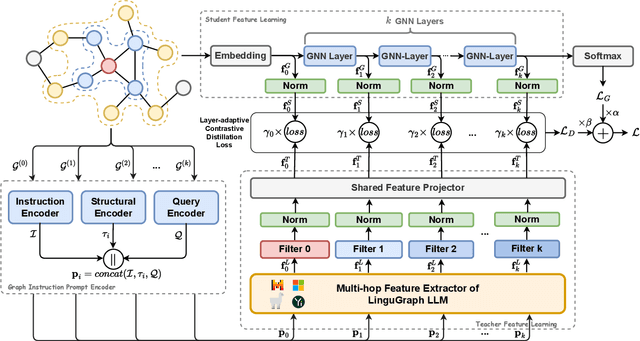
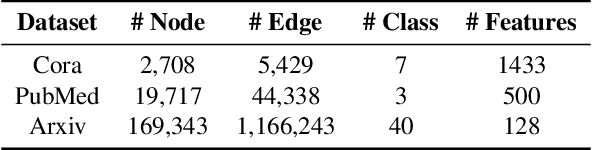
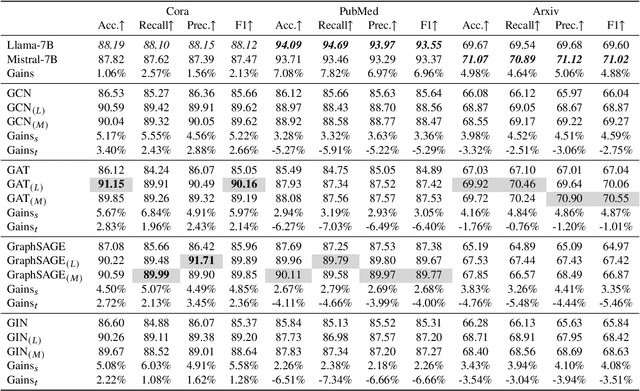
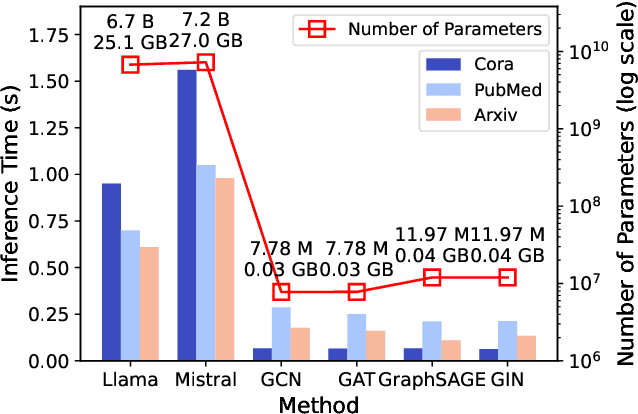
Despite recent community revelations about the advancements and potential applications of Large Language Models (LLMs) in understanding Text-Attributed Graph (TAG), the deployment of LLMs for production is hindered by its high computational and storage requirements, as well as long latencies during model inference. Simultaneously, although traditional Graph Neural Networks (GNNs) are light weight and adept at learning structural features of graphs, their ability to grasp the complex semantics in TAG is somewhat constrained for real applications. To address these limitations, we concentrate on the downstream task of node classification in TAG and propose a novel graph knowledge distillation framework, termed Linguistic Graph Knowledge Distillation (LinguGKD), using LLMs as teacher models and GNNs as student models for knowledge distillation. It involves TAG-oriented instruction tuning of LLM on designed tailored prompts, followed by propagating knowledge and aligning the hierarchically learned node features from the teacher LLM to the student GNN in latent space, employing a layer-adaptive contrastive learning strategy. Through extensive experiments on a variety of LLM and GNN models and multiple benchmark datasets, the proposed LinguGKD significantly boosts the student GNN's predictive accuracy and convergence rate, without the need of extra data or model parameters. Compared to teacher LLM, distilled GNN achieves superior inference speed equipped with much fewer computing and storage demands, when surpassing the teacher LLM's classification accuracy on some of benchmark datasets.
Understanding Text-driven Motion Synthesis with Keyframe Collaboration via Diffusion Models
May 23, 2023The emergence of text-driven motion synthesis technique provides animators with great potential to create efficiently. However, in most cases, textual expressions only contain general and qualitative motion descriptions, while lack fine depiction and sufficient intensity, leading to the synthesized motions that either (a) semantically compliant but uncontrollable over specific pose details, or (b) even deviates from the provided descriptions, bringing animators with undesired cases. In this paper, we propose DiffKFC, a conditional diffusion model for text-driven motion synthesis with keyframes collaborated. Different from plain text-driven designs, full interaction among texts, keyframes and the rest diffused frames are conducted at training, enabling realistic generation under efficient, collaborative dual-level control: coarse guidance at semantic level, with only few keyframes for direct and fine-grained depiction down to body posture level, to satisfy animator requirements without tedious labor. Specifically, we customize efficient Dilated Mask Attention modules, where only partial valid tokens participate in local-to-global attention, indicated by the dilated keyframe mask. For user flexibility, DiffKFC supports adjustment on importance of fine-grained keyframe control. Experimental results show that our model achieves state-of-the-art performance on text-to-motion datasets HumanML3D and KIT.
Recurrent Transformer for Dynamic Graph Representation Learning with Edge Temporal States
Apr 20, 2023



Dynamic graph representation learning is growing as a trending yet challenging research task owing to the widespread demand for graph data analysis in real world applications. Despite the encouraging performance of many recent works that build upon recurrent neural networks (RNNs) and graph neural networks (GNNs), they fail to explicitly model the impact of edge temporal states on node features over time slices. Additionally, they are challenging to extract global structural features because of the inherent over-smoothing disadvantage of GNNs, which further restricts the performance. In this paper, we propose a recurrent difference graph transformer (RDGT) framework, which firstly assigns the edges in each snapshot with various types and weights to illustrate their specific temporal states explicitly, then a structure-reinforced graph transformer is employed to capture the temporal node representations by a recurrent learning paradigm. Experimental results on four real-world datasets demonstrate the superiority of RDGT for discrete dynamic graph representation learning, as it consistently outperforms competing methods in dynamic link prediction tasks.
Human Joint Kinematics Diffusion-Refinement for Stochastic Motion Prediction
Oct 12, 2022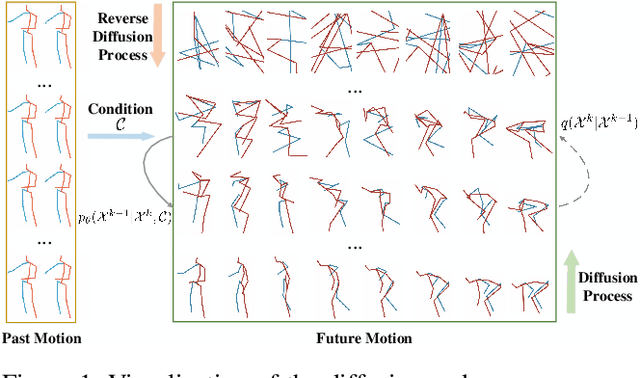
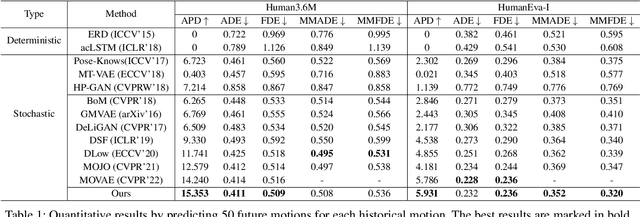
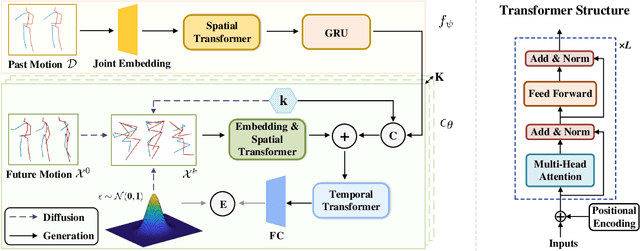

Stochastic human motion prediction aims to forecast multiple plausible future motions given a single pose sequence from the past. Most previous works focus on designing elaborate losses to improve the accuracy, while the diversity is typically characterized by randomly sampling a set of latent variables from the latent prior, which is then decoded into possible motions. This joint training of sampling and decoding, however, suffers from posterior collapse as the learned latent variables tend to be ignored by a strong decoder, leading to limited diversity. Alternatively, inspired by the diffusion process in nonequilibrium thermodynamics, we propose MotionDiff, a diffusion probabilistic model to treat the kinematics of human joints as heated particles, which will diffuse from original states to a noise distribution. This process offers a natural way to obtain the "whitened" latents without any trainable parameters, and human motion prediction can be regarded as the reverse diffusion process that converts the noise distribution into realistic future motions conditioned on the observed sequence. Specifically, MotionDiff consists of two parts: a spatial-temporal transformer-based diffusion network to generate diverse yet plausible motions, and a graph convolutional network to further refine the outputs. Experimental results on two datasets demonstrate that our model yields the competitive performance in terms of both accuracy and diversity.