 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding Text-driven Motion Synthesis with Keyframe Collaboration via Diffusion Models
May 23, 2023The emergence of text-driven motion synthesis technique provides animators with great potential to create efficiently. However, in most cases, textual expressions only contain general and qualitative motion descriptions, while lack fine depiction and sufficient intensity, leading to the synthesized motions that either (a) semantically compliant but uncontrollable over specific pose details, or (b) even deviates from the provided descriptions, bringing animators with undesired cases. In this paper, we propose DiffKFC, a conditional diffusion model for text-driven motion synthesis with keyframes collaborated. Different from plain text-driven designs, full interaction among texts, keyframes and the rest diffused frames are conducted at training, enabling realistic generation under efficient, collaborative dual-level control: coarse guidance at semantic level, with only few keyframes for direct and fine-grained depiction down to body posture level, to satisfy animator requirements without tedious labor. Specifically, we customize efficient Dilated Mask Attention modules, where only partial valid tokens participate in local-to-global attention, indicated by the dilated keyframe mask. For user flexibility, DiffKFC supports adjustment on importance of fine-grained keyframe control. Experimental results show that our model achieves state-of-the-art performance on text-to-motion datasets HumanML3D and KIT.
DeFeeNet: Consecutive 3D Human Motion Prediction with Deviation Feedback
Apr 14, 2023Let us rethink the real-world scenarios that require human motion prediction techniques, such as human-robot collaboration. Current works simplify the task of predicting human motions into a one-off process of forecasting a short future sequence (usually no longer than 1 second) based on a historical observed one. However, such simplification may fail to meet practical needs due to the neglect of the fact that motion prediction in real applications is not an isolated ``observe then predict'' unit, but a consecutive process composed of many rounds of such unit, semi-overlapped along the entire sequence. As time goes on, the predicted part of previous round has its corresponding ground truth observable in the new round, but their deviation in-between is neither exploited nor able to be captured by existing isolated learning fashion. In this paper, we propose DeFeeNet, a simple yet effective network that can be added on existing one-off prediction models to realize deviation perception and feedback when applied to consecutive motion prediction task. At each prediction round, the deviation generated by previous unit is first encoded by our DeFeeNet, and then incorporated into the existing predictor to enable a deviation-aware prediction manner, which, for the first time, allows for information transmit across adjacent prediction units. We design two versions of DeFeeNet as MLP-based and GRU-based, respectively. On Human3.6M and more complicated BABEL, experimental results indicate that our proposed network improves consecutive human motion prediction performance regardless of the basic model.
Human Joint Kinematics Diffusion-Refinement for Stochastic Motion Prediction
Oct 12, 2022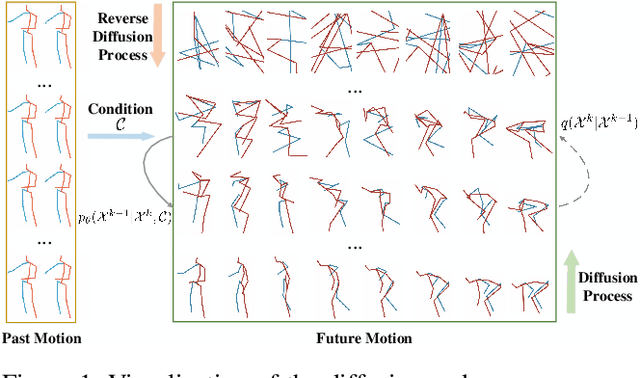
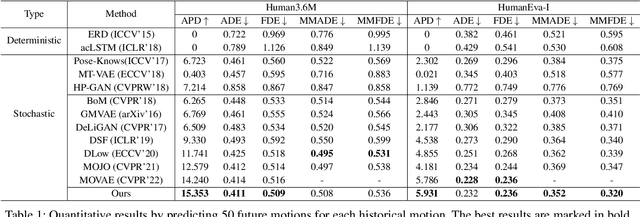
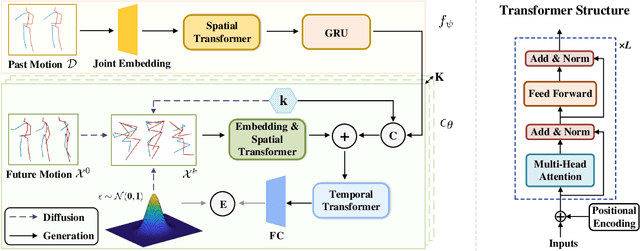

Stochastic human motion prediction aims to forecast multiple plausible future motions given a single pose sequence from the past. Most previous works focus on designing elaborate losses to improve the accuracy, while the diversity is typically characterized by randomly sampling a set of latent variables from the latent prior, which is then decoded into possible motions. This joint training of sampling and decoding, however, suffers from posterior collapse as the learned latent variables tend to be ignored by a strong decoder, leading to limited diversity. Alternatively, inspired by the diffusion process in nonequilibrium thermodynamics, we propose MotionDiff, a diffusion probabilistic model to treat the kinematics of human joints as heated particles, which will diffuse from original states to a noise distribution. This process offers a natural way to obtain the "whitened" latents without any trainable parameters, and human motion prediction can be regarded as the reverse diffusion process that converts the noise distribution into realistic future motions conditioned on the observed sequence. Specifically, MotionDiff consists of two parts: a spatial-temporal transformer-based diffusion network to generate diverse yet plausible motions, and a graph convolutional network to further refine the outputs. Experimental results on two datasets demonstrate that our model yields the competitive performance in terms of both accuracy and diversity.
Overlooked Poses Actually Make Sense: Distilling Privileged Knowledge for Human Motion Prediction
Aug 02, 2022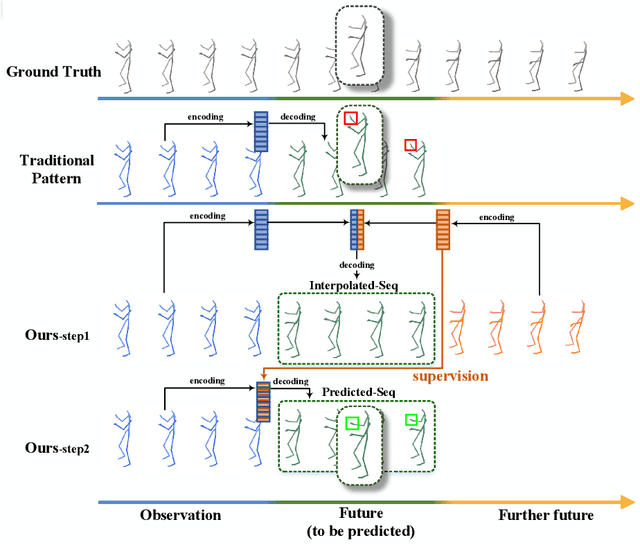
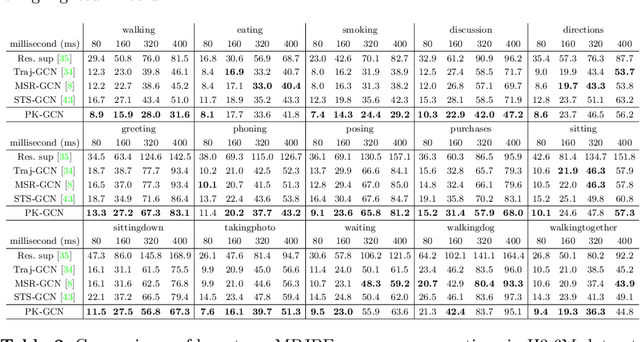
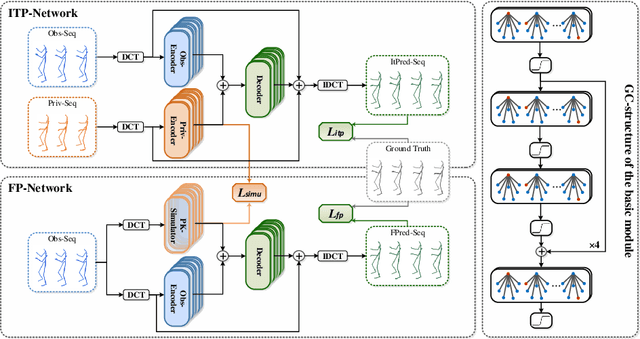
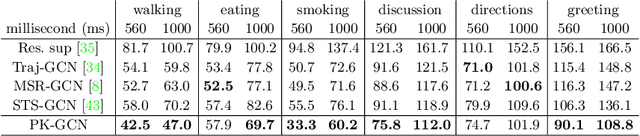
Previous works on human motion prediction follow the pattern of building a mapping relation between the sequence observed and the one to be predicted. However, due to the inherent complexity of multivariate time series data, it still remains a challenge to find the extrapolation relation between motion sequences. In this paper, we present a new prediction pattern, which introduces previously overlooked human poses, to implement the prediction task from the view of interpolation. These poses exist after the predicted sequence, and form the privileged sequence. To be specific, we first propose an InTerPolation learning Network (ITP-Network) that encodes both the observed sequence and the privileged sequence to interpolate the in-between predicted sequence, wherein the embedded Privileged-sequence-Encoder (Priv-Encoder) learns the privileged knowledge (PK) simultaneously. Then, we propose a Final Prediction Network (FP-Network) for which the privileged sequence is not observable, but is equipped with a novel PK-Simulator that distills PK learned from the previous network. This simulator takes as input the observed sequence, but approximates the behavior of Priv-Encoder, enabling FP-Network to imitate the interpolation process. Extensive experimental results demonstrate that our prediction pattern achieves state-of-the-art performance on benchmarked H3.6M, CMU-Mocap and 3DPW datasets in both short-term and long-term predictions.