 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHuman Joint Kinematics Diffusion-Refinement for Stochastic Motion Prediction
Paper and Code
Oct 12, 2022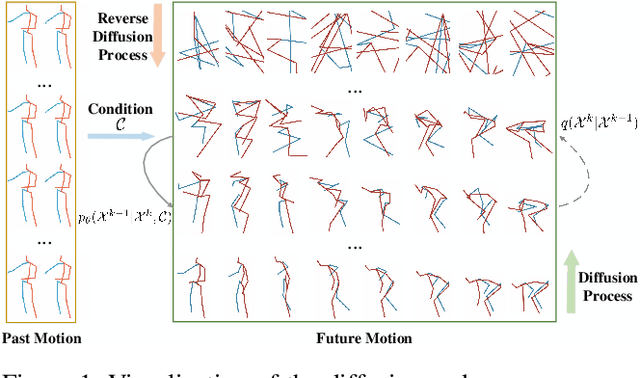
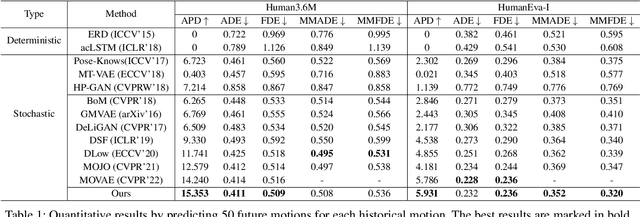
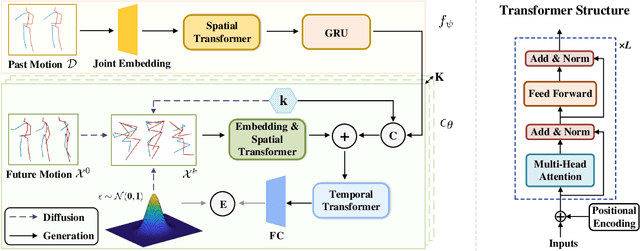

Stochastic human motion prediction aims to forecast multiple plausible future motions given a single pose sequence from the past. Most previous works focus on designing elaborate losses to improve the accuracy, while the diversity is typically characterized by randomly sampling a set of latent variables from the latent prior, which is then decoded into possible motions. This joint training of sampling and decoding, however, suffers from posterior collapse as the learned latent variables tend to be ignored by a strong decoder, leading to limited diversity. Alternatively, inspired by the diffusion process in nonequilibrium thermodynamics, we propose MotionDiff, a diffusion probabilistic model to treat the kinematics of human joints as heated particles, which will diffuse from original states to a noise distribution. This process offers a natural way to obtain the "whitened" latents without any trainable parameters, and human motion prediction can be regarded as the reverse diffusion process that converts the noise distribution into realistic future motions conditioned on the observed sequence. Specifically, MotionDiff consists of two parts: a spatial-temporal transformer-based diffusion network to generate diverse yet plausible motions, and a graph convolutional network to further refine the outputs. Experimental results on two datasets demonstrate that our model yields the competitive performance in terms of both accuracy and diversity.