 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSkyReels-V3 Technique Report
Jan 24, 2026Video generation serves as a cornerstone for building world models, where multimodal contextual inference stands as the defining test of capability. In this end, we present SkyReels-V3, a conditional video generation model, built upon a unified multimodal in-context learning framework with diffusion Transformers. SkyReels-V3 model supports three core generative paradigms within a single architecture: reference images-to-video synthesis, video-to-video extension and audio-guided video generation. (i) reference images-to-video model is designed to produce high-fidelity videos with strong subject identity preservation, temporal coherence, and narrative consistency. To enhance reference adherence and compositional stability, we design a comprehensive data processing pipeline that leverages cross frame pairing, image editing, and semantic rewriting, effectively mitigating copy paste artifacts. During training, an image video hybrid strategy combined with multi-resolution joint optimization is employed to improve generalization and robustness across diverse scenarios. (ii) video extension model integrates spatio-temporal consistency modeling with large-scale video understanding, enabling both seamless single-shot continuation and intelligent multi-shot switching with professional cinematographic patterns. (iii) Talking avatar model supports minute-level audio-conditioned video generation by training first-and-last frame insertion patterns and reconstructing key-frame inference paradigms. On the basis of ensuring visual quality, synchronization of audio and videos has been optimized. Extensive evaluations demonstrate that SkyReels-V3 achieves state-of-the-art or near state-of-the-art performance on key metrics including visual quality, instruction following, and specific aspect metrics, approaching leading closed-source systems. Github: https://github.com/SkyworkAI/SkyReels-V3.
MotionCharacter: Identity-Preserving and Motion Controllable Human Video Generation
Nov 30, 2024



Recent advancements in personalized Text-to-Video (T2V) generation highlight the importance of integrating character-specific identities and actions. However, previous T2V models struggle with identity consistency and controllable motion dynamics, mainly due to limited fine-grained facial and action-based textual prompts, and datasets that overlook key human attributes and actions. To address these challenges, we propose MotionCharacter, an efficient and high-fidelity human video generation framework designed for identity preservation and fine-grained motion control. We introduce an ID-preserving module to maintain identity fidelity while allowing flexible attribute modifications, and further integrate ID-consistency and region-aware loss mechanisms, significantly enhancing identity consistency and detail fidelity. Additionally, our approach incorporates a motion control module that prioritizes action-related text while maintaining subject consistency, along with a dataset, Human-Motion, which utilizes large language models to generate detailed motion descriptions. For simplify user control during inference, we parameterize motion intensity through a single coefficient, allowing for easy adjustments. Extensive experiments highlight the effectiveness of MotionCharacter, demonstrating significant improvements in ID-preserving, high-quality video generation.
Draw an Audio: Leveraging Multi-Instruction for Video-to-Audio Synthesis
Sep 10, 2024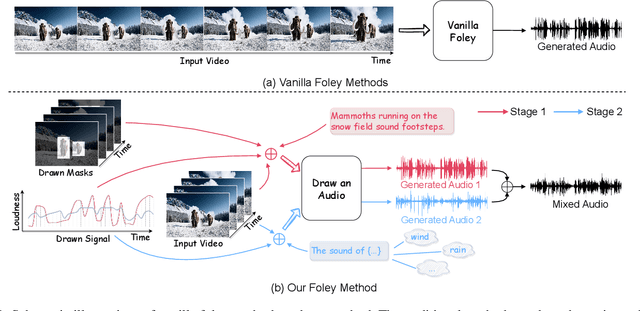
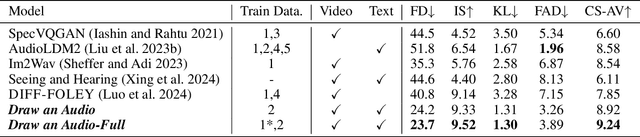
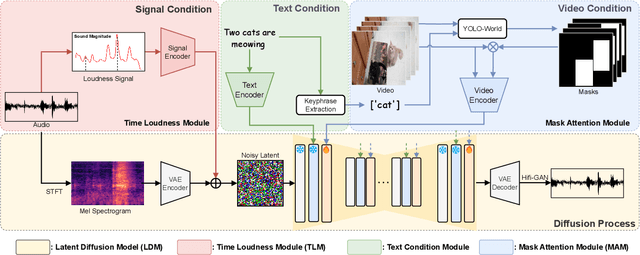
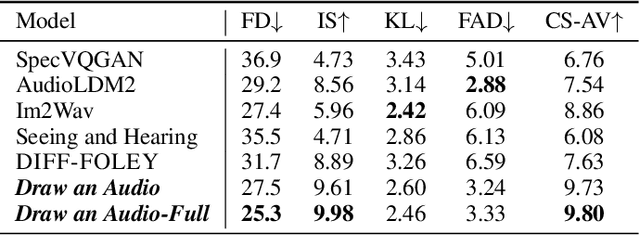
Foley is a term commonly used in filmmaking, referring to the addition of daily sound effects to silent films or videos to enhance the auditory experience. Video-to-Audio (V2A), as a particular type of automatic foley task, presents inherent challenges related to audio-visual synchronization. These challenges encompass maintaining the content consistency between the input video and the generated audio, as well as the alignment of temporal and loudness properties within the video. To address these issues, we construct a controllable video-to-audio synthesis model, termed Draw an Audio, which supports multiple input instructions through drawn masks and loudness signals. To ensure content consistency between the synthesized audio and target video, we introduce the Mask-Attention Module (MAM), which employs masked video instruction to enable the model to focus on regions of interest. Additionally, we implement the Time-Loudness Module (TLM), which uses an auxiliary loudness signal to ensure the synthesis of sound that aligns with the video in both loudness and temporal dimensions. Furthermore, we have extended a large-scale V2A dataset, named VGGSound-Caption, by annotating caption prompts. Extensive experiments on challenging benchmarks across two large-scale V2A datasets verify Draw an Audio achieves the state-of-the-art. Project page: https://yannqi.github.io/Draw-an-Audio/.
Joint Physical-Digital Facial Attack Detection Via Simulating Spoofing Clues
Apr 12, 2024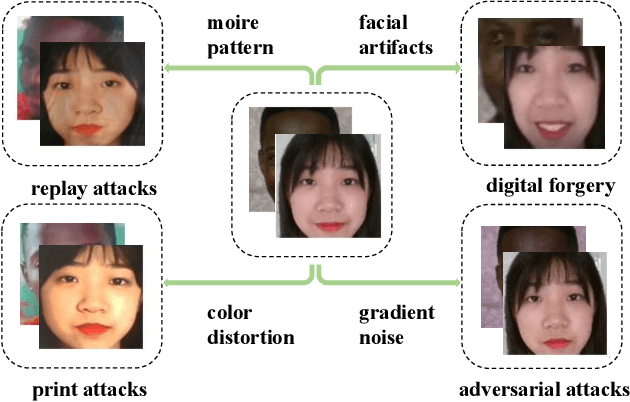
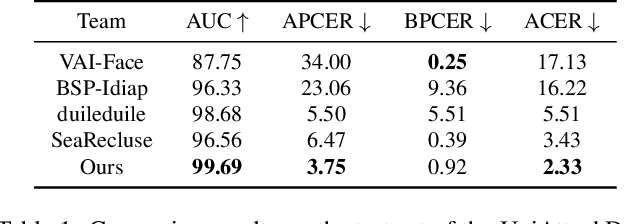
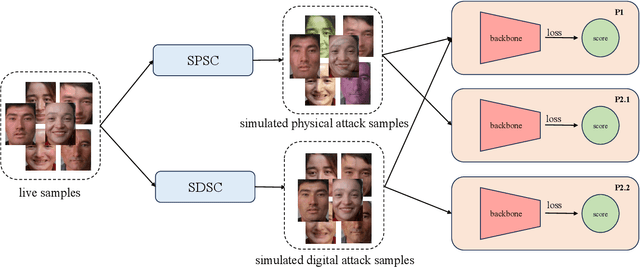
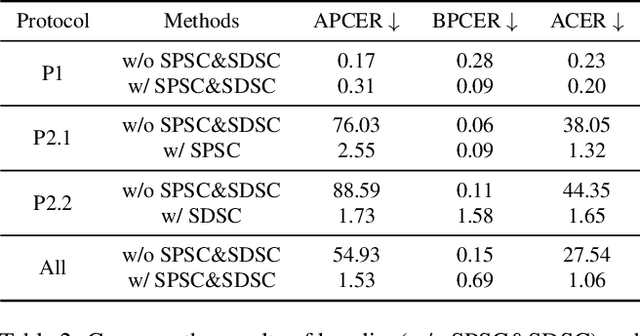
Face recognition systems are frequently subjected to a variety of physical and digital attacks of different types. Previous methods have achieved satisfactory performance in scenarios that address physical attacks and digital attacks, respectively. However, few methods are considered to integrate a model that simultaneously addresses both physical and digital attacks, implying the necessity to develop and maintain multiple models. To jointly detect physical and digital attacks within a single model, we propose an innovative approach that can adapt to any network architecture. Our approach mainly contains two types of data augmentation, which we call Simulated Physical Spoofing Clues augmentation (SPSC) and Simulated Digital Spoofing Clues augmentation (SDSC). SPSC and SDSC augment live samples into simulated attack samples by simulating spoofing clues of physical and digital attacks, respectively, which significantly improve the capability of the model to detect "unseen" attack types. Extensive experiments show that SPSC and SDSC can achieve state-of-the-art generalization in Protocols 2.1 and 2.2 of the UniAttackData dataset, respectively. Our method won first place in "Unified Physical-Digital Face Attack Detection" of the 5th Face Anti-spoofing Challenge@CVPR2024. Our final submission obtains 3.75% APCER, 0.93% BPCER, and 2.34% ACER, respectively. Our code is available at https://github.com/Xianhua-He/cvpr2024-face-anti-spoofing-challenge.
Knowledge Guided Metric Learning for Few-Shot Text Classification
Apr 04, 2020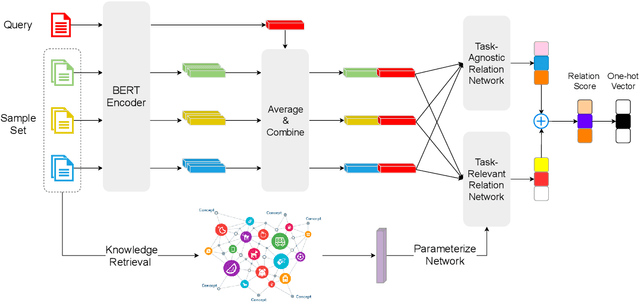
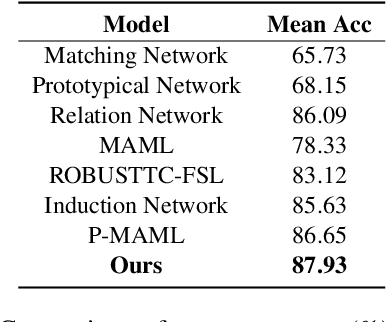
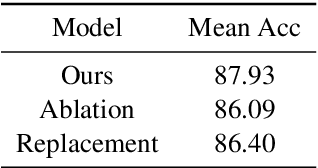
The training of deep-learning-based text classification models relies heavily on a huge amount of annotation data, which is difficult to obtain. When the labeled data is scarce, models tend to struggle to achieve satisfactory performance. However, human beings can distinguish new categories very efficiently with few examples. This is mainly due to the fact that human beings can leverage knowledge obtained from relevant tasks. Inspired by human intelligence, we propose to introduce external knowledge into few-shot learning to imitate human knowledge. A novel parameter generator network is investigated to this end, which is able to use the external knowledge to generate relation network parameters. Metrics can be transferred among tasks when equipped with these generated parameters, so that similar tasks use similar metrics while different tasks use different metrics. Through experiments, we demonstrate that our method outperforms the state-of-the-art few-shot text classification models.