 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDraw an Audio: Leveraging Multi-Instruction for Video-to-Audio Synthesis
Paper and Code
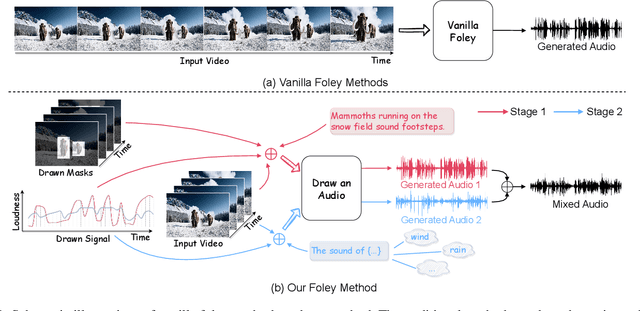
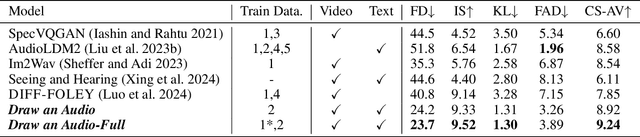
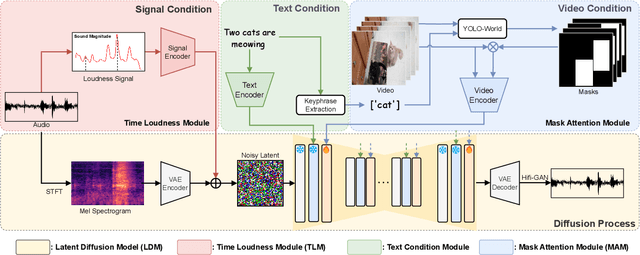
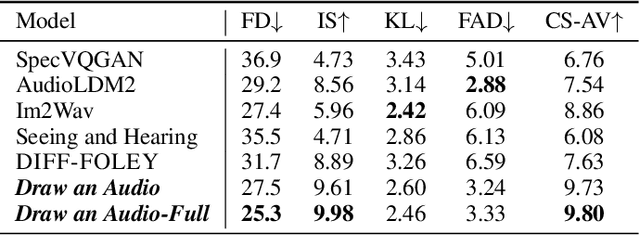
Foley is a term commonly used in filmmaking, referring to the addition of daily sound effects to silent films or videos to enhance the auditory experience. Video-to-Audio (V2A), as a particular type of automatic foley task, presents inherent challenges related to audio-visual synchronization. These challenges encompass maintaining the content consistency between the input video and the generated audio, as well as the alignment of temporal and loudness properties within the video. To address these issues, we construct a controllable video-to-audio synthesis model, termed Draw an Audio, which supports multiple input instructions through drawn masks and loudness signals. To ensure content consistency between the synthesized audio and target video, we introduce the Mask-Attention Module (MAM), which employs masked video instruction to enable the model to focus on regions of interest. Additionally, we implement the Time-Loudness Module (TLM), which uses an auxiliary loudness signal to ensure the synthesis of sound that aligns with the video in both loudness and temporal dimensions. Furthermore, we have extended a large-scale V2A dataset, named VGGSound-Caption, by annotating caption prompts. Extensive experiments on challenging benchmarks across two large-scale V2A datasets verify Draw an Audio achieves the state-of-the-art. Project page: https://yannqi.github.io/Draw-an-Audio/.