 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDraw an Audio: Leveraging Multi-Instruction for Video-to-Audio Synthesis
Sep 10, 2024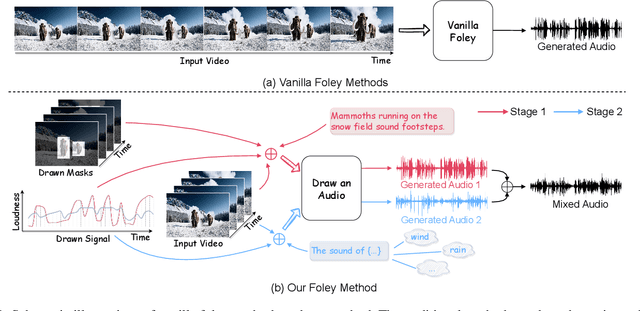
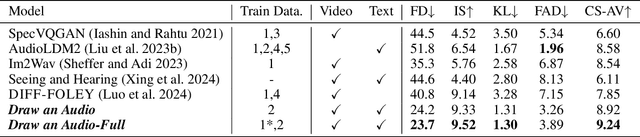
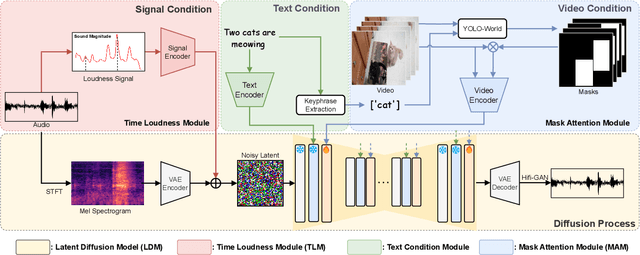
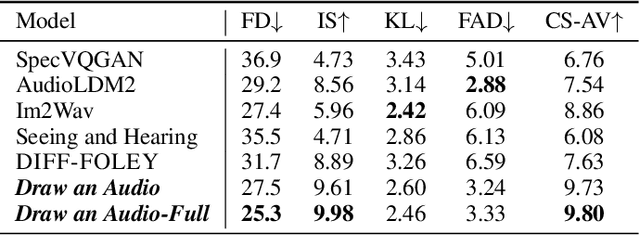
Foley is a term commonly used in filmmaking, referring to the addition of daily sound effects to silent films or videos to enhance the auditory experience. Video-to-Audio (V2A), as a particular type of automatic foley task, presents inherent challenges related to audio-visual synchronization. These challenges encompass maintaining the content consistency between the input video and the generated audio, as well as the alignment of temporal and loudness properties within the video. To address these issues, we construct a controllable video-to-audio synthesis model, termed Draw an Audio, which supports multiple input instructions through drawn masks and loudness signals. To ensure content consistency between the synthesized audio and target video, we introduce the Mask-Attention Module (MAM), which employs masked video instruction to enable the model to focus on regions of interest. Additionally, we implement the Time-Loudness Module (TLM), which uses an auxiliary loudness signal to ensure the synthesis of sound that aligns with the video in both loudness and temporal dimensions. Furthermore, we have extended a large-scale V2A dataset, named VGGSound-Caption, by annotating caption prompts. Extensive experiments on challenging benchmarks across two large-scale V2A datasets verify Draw an Audio achieves the state-of-the-art. Project page: https://yannqi.github.io/Draw-an-Audio/.
Defying Imbalanced Forgetting in Class Incremental Learning
Mar 22, 2024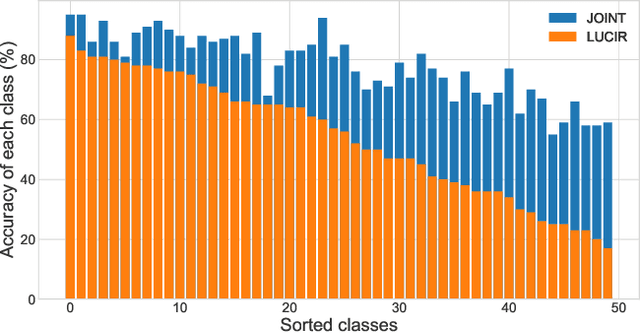
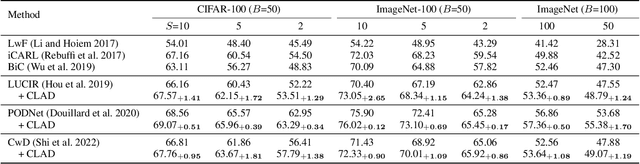
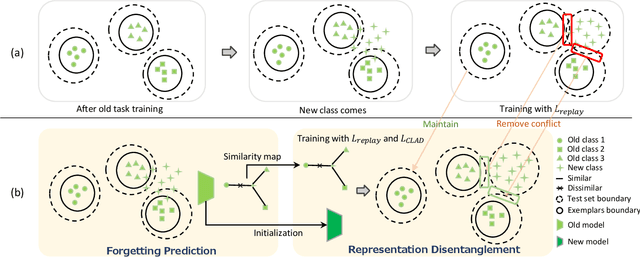
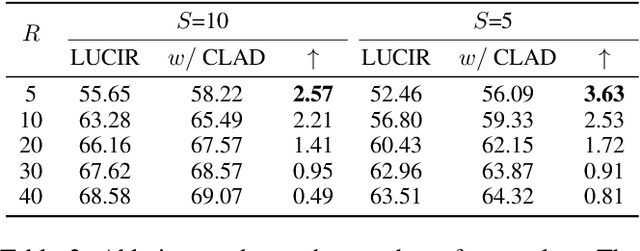
We observe a high level of imbalance in the accuracy of different classes in the same old task for the first time. This intriguing phenomenon, discovered in replay-based Class Incremental Learning (CIL), highlights the imbalanced forgetting of learned classes, as their accuracy is similar before the occurrence of catastrophic forgetting. This discovery remains previously unidentified due to the reliance on average incremental accuracy as the measurement for CIL, which assumes that the accuracy of classes within the same task is similar. However, this assumption is invalid in the face of catastrophic forgetting. Further empirical studies indicate that this imbalanced forgetting is caused by conflicts in representation between semantically similar old and new classes. These conflicts are rooted in the data imbalance present in replay-based CIL methods. Building on these insights, we propose CLass-Aware Disentanglement (CLAD) to predict the old classes that are more likely to be forgotten and enhance their accuracy. Importantly, CLAD can be seamlessly integrated into existing CIL methods. Extensive experiments demonstrate that CLAD consistently improves current replay-based methods, resulting in performance gains of up to 2.56%.
Cooperation Does Matter: Exploring Multi-Order Bilateral Relations for Audio-Visual Segmentation
Dec 11, 2023Recently, an audio-visual segmentation (AVS) task has been introduced, aiming to group pixels with sounding objects within a given video. This task necessitates a first-ever audio-driven pixel-level understanding of the scene, posing significant challenges. In this paper, we propose an innovative audio-visual transformer framework, termed COMBO, an acronym for COoperation of Multi-order Bilateral relatiOns. For the first time, our framework explores three types of bilateral entanglements within AVS: pixel entanglement, modality entanglement, and temporal entanglement. Regarding pixel entanglement, we employ a Siam-Encoder Module (SEM) that leverages prior knowledge to generate more precise visual features from the foundational model. For modality entanglement, we design a Bilateral-Fusion Module (BFM), enabling COMBO to align corresponding visual and auditory signals bi-directionally. As for temporal entanglement, we introduce an innovative adaptive inter-frame consistency loss according to the inherent rules of temporal. Comprehensive experiments and ablation studies on AVSBench-object (84.7 mIoU on S4, 59.2 mIou on MS3) and AVSBench-semantic (42.1 mIoU on AVSS) datasets demonstrate that COMBO surpasses previous state-of-the-art methods. Code and more results will be publicly available at https://combo-avs.github.io/.
Pro-tuning: Unified Prompt Tuning for Vision Tasks
Aug 14, 2022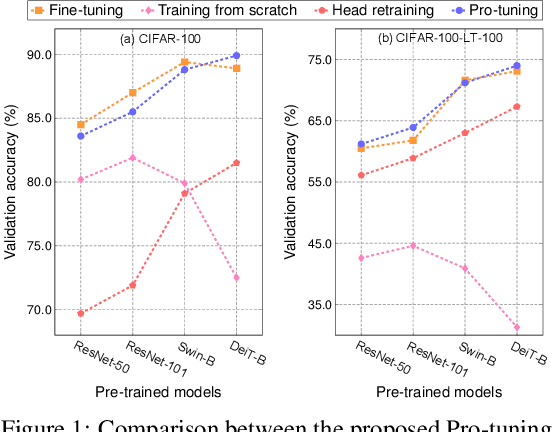
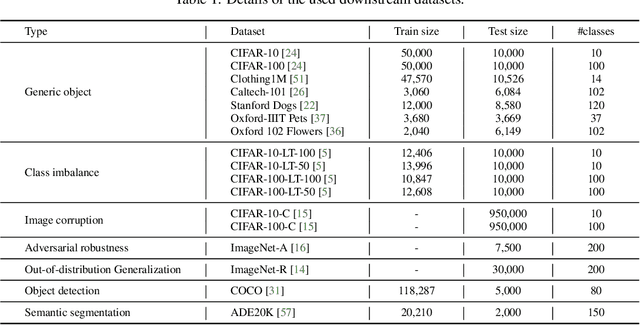
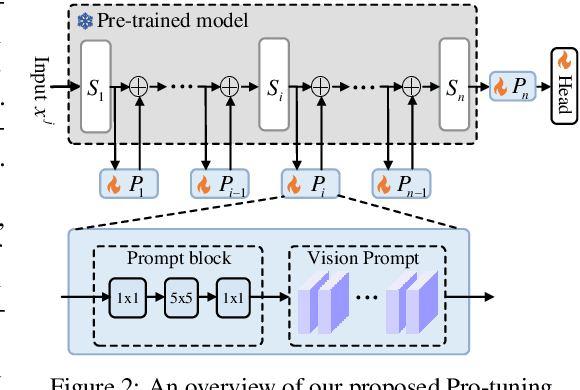
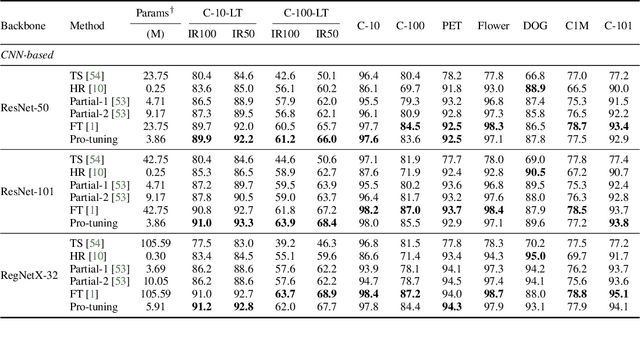
In computer vision, fine-tuning is the de-facto approach to leverage pre-trained vision models to perform downstream tasks. However, deploying it in practice is quite challenging, due to adopting parameter inefficient global update and heavily relying on high-quality downstream data. Recently, prompt-based learning, which adds a task-relevant prompt to adapt the downstream tasks to pre-trained models, has drastically boosted the performance of many natural language downstream tasks. In this work, we extend this notable transfer ability benefited from prompt into vision models as an alternative to fine-tuning. To this end, we propose parameter-efficient Prompt tuning (Pro-tuning) to adapt frozen vision models to various downstream vision tasks. The key to Pro-tuning is prompt-based tuning, i.e., learning task-specific vision prompts for downstream input images with the pre-trained model frozen. By only training a few additional parameters, it can work on diverse CNN-based and Transformer-based architectures. Extensive experiments evidence that Pro-tuning outperforms fine-tuning in a broad range of vision tasks and scenarios, including image classification (generic objects, class imbalance, image corruption, adversarial robustness, and out-of-distribution generalization), and dense prediction tasks such as object detection and semantic segmentation.
Differentiable Convolution Search for Point Cloud Processing
Aug 29, 2021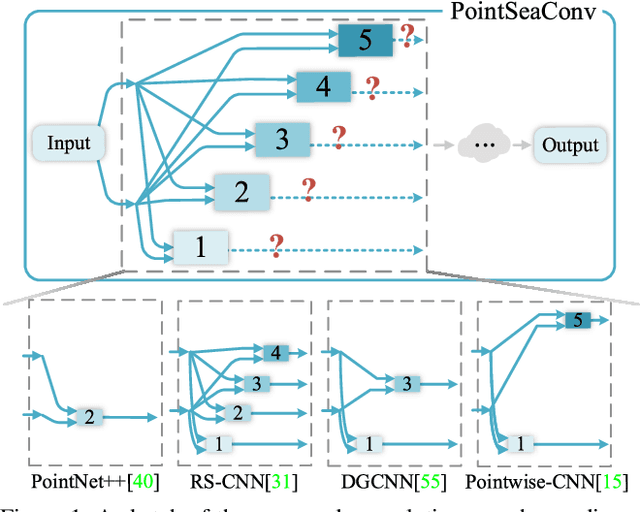

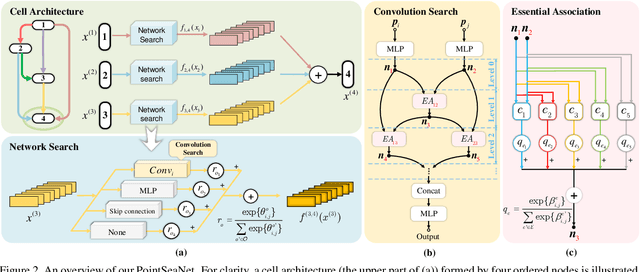

Exploiting convolutional neural networks for point cloud processing is quite challenging, due to the inherent irregular distribution and discrete shape representation of point clouds. To address these problems, many handcrafted convolution variants have sprung up in recent years. Though with elaborate design, these variants could be far from optimal in sufficiently capturing diverse shapes formed by discrete points. In this paper, we propose PointSeaConv, i.e., a novel differential convolution search paradigm on point clouds. It can work in a purely data-driven manner and thus is capable of auto-creating a group of suitable convolutions for geometric shape modeling. We also propose a joint optimization framework for simultaneous search of internal convolution and external architecture, and introduce epsilon-greedy algorithm to alleviate the effect of discretization error. As a result, PointSeaNet, a deep network that is sufficient to capture geometric shapes at both convolution level and architecture level, can be searched out for point cloud processing. Extensive experiments strongly evidence that our proposed PointSeaNet surpasses current handcrafted deep models on challenging benchmarks across multiple tasks with remarkable margins.