 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePro-tuning: Unified Prompt Tuning for Vision Tasks
Aug 14, 2022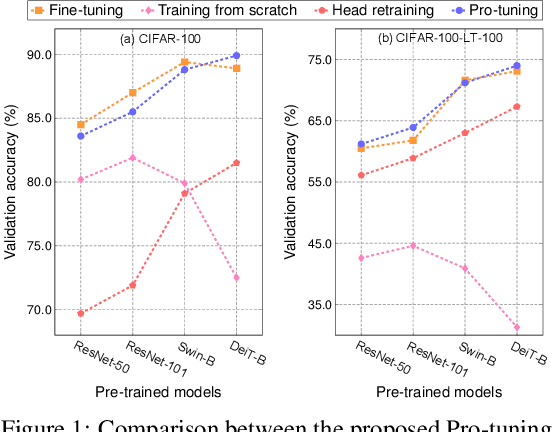
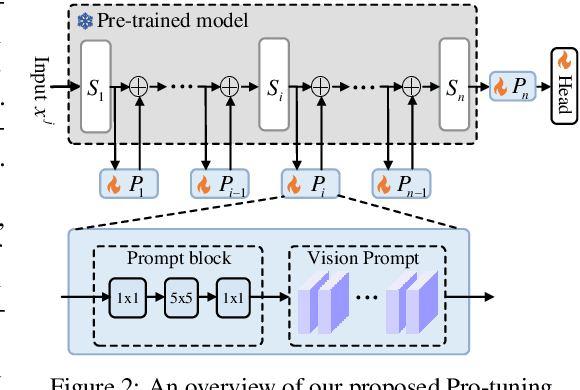
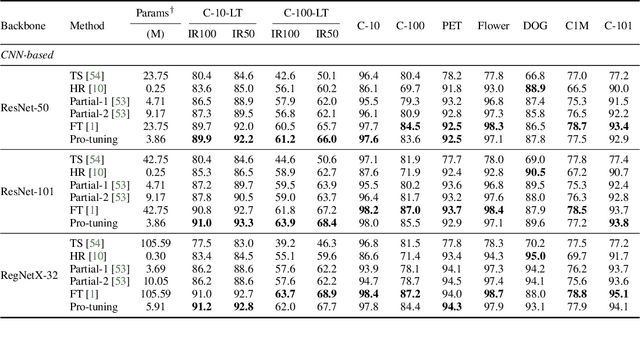
In computer vision, fine-tuning is the de-facto approach to leverage pre-trained vision models to perform downstream tasks. However, deploying it in practice is quite challenging, due to adopting parameter inefficient global update and heavily relying on high-quality downstream data. Recently, prompt-based learning, which adds a task-relevant prompt to adapt the downstream tasks to pre-trained models, has drastically boosted the performance of many natural language downstream tasks. In this work, we extend this notable transfer ability benefited from prompt into vision models as an alternative to fine-tuning. To this end, we propose parameter-efficient Prompt tuning (Pro-tuning) to adapt frozen vision models to various downstream vision tasks. The key to Pro-tuning is prompt-based tuning, i.e., learning task-specific vision prompts for downstream input images with the pre-trained model frozen. By only training a few additional parameters, it can work on diverse CNN-based and Transformer-based architectures. Extensive experiments evidence that Pro-tuning outperforms fine-tuning in a broad range of vision tasks and scenarios, including image classification (generic objects, class imbalance, image corruption, adversarial robustness, and out-of-distribution generalization), and dense prediction tasks such as object detection and semantic segmentation.