 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePro-tuning: Unified Prompt Tuning for Vision Tasks
Aug 14, 2022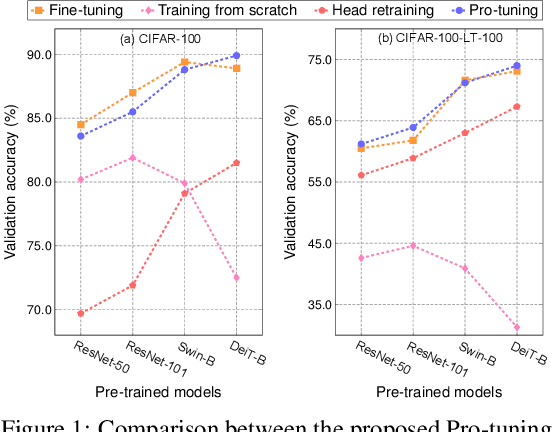
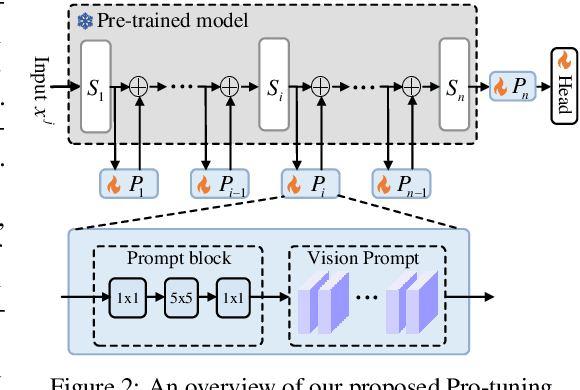
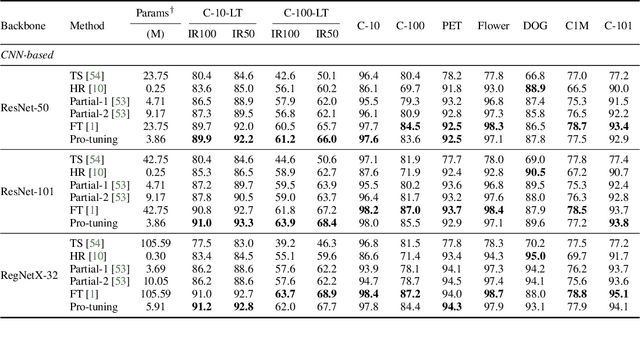
In computer vision, fine-tuning is the de-facto approach to leverage pre-trained vision models to perform downstream tasks. However, deploying it in practice is quite challenging, due to adopting parameter inefficient global update and heavily relying on high-quality downstream data. Recently, prompt-based learning, which adds a task-relevant prompt to adapt the downstream tasks to pre-trained models, has drastically boosted the performance of many natural language downstream tasks. In this work, we extend this notable transfer ability benefited from prompt into vision models as an alternative to fine-tuning. To this end, we propose parameter-efficient Prompt tuning (Pro-tuning) to adapt frozen vision models to various downstream vision tasks. The key to Pro-tuning is prompt-based tuning, i.e., learning task-specific vision prompts for downstream input images with the pre-trained model frozen. By only training a few additional parameters, it can work on diverse CNN-based and Transformer-based architectures. Extensive experiments evidence that Pro-tuning outperforms fine-tuning in a broad range of vision tasks and scenarios, including image classification (generic objects, class imbalance, image corruption, adversarial robustness, and out-of-distribution generalization), and dense prediction tasks such as object detection and semantic segmentation.
Differentiable Convolution Search for Point Cloud Processing
Aug 29, 2021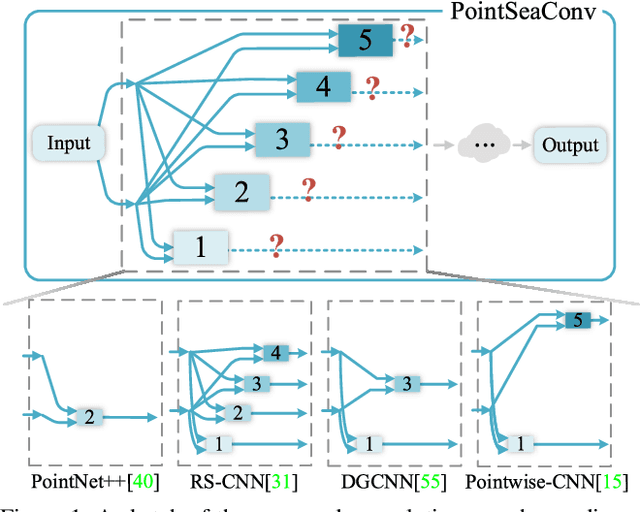

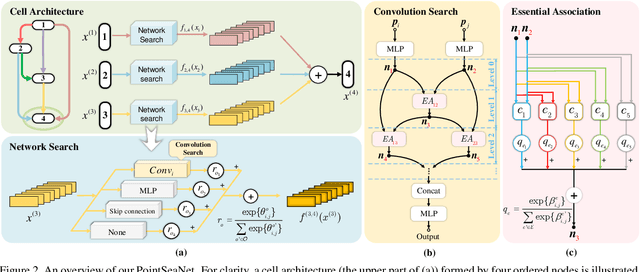

Exploiting convolutional neural networks for point cloud processing is quite challenging, due to the inherent irregular distribution and discrete shape representation of point clouds. To address these problems, many handcrafted convolution variants have sprung up in recent years. Though with elaborate design, these variants could be far from optimal in sufficiently capturing diverse shapes formed by discrete points. In this paper, we propose PointSeaConv, i.e., a novel differential convolution search paradigm on point clouds. It can work in a purely data-driven manner and thus is capable of auto-creating a group of suitable convolutions for geometric shape modeling. We also propose a joint optimization framework for simultaneous search of internal convolution and external architecture, and introduce epsilon-greedy algorithm to alleviate the effect of discretization error. As a result, PointSeaNet, a deep network that is sufficient to capture geometric shapes at both convolution level and architecture level, can be searched out for point cloud processing. Extensive experiments strongly evidence that our proposed PointSeaNet surpasses current handcrafted deep models on challenging benchmarks across multiple tasks with remarkable margins.
Adaptive Remote Sensing Image Attribute Learning for Active Object Detection
Jan 16, 2021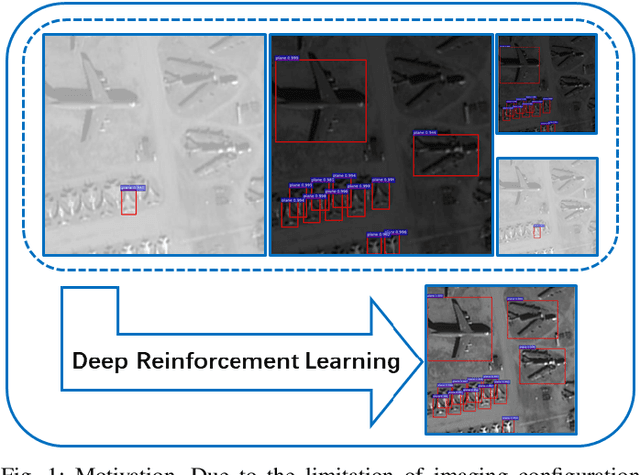
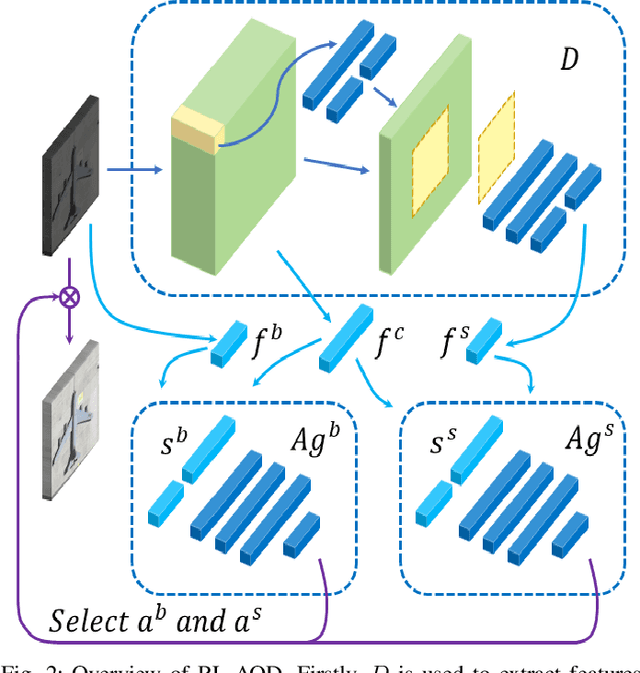
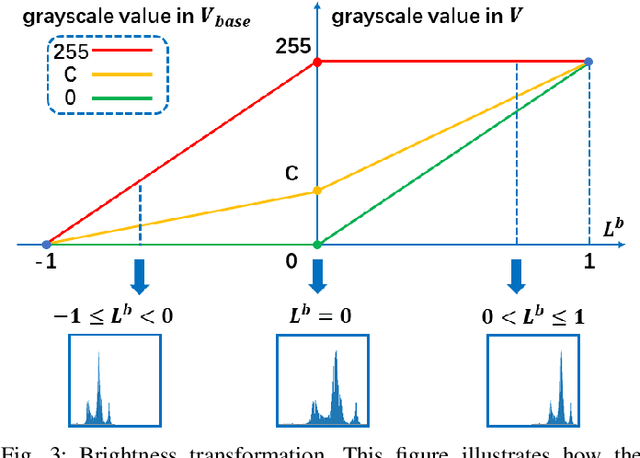
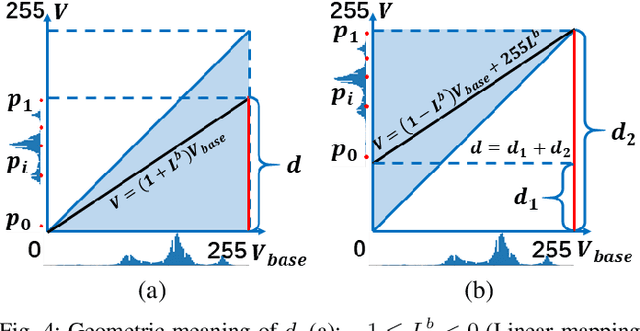
In recent years, deep learning methods bring incredible progress to the field of object detection. However, in the field of remote sensing image processing, existing methods neglect the relationship between imaging configuration and detection performance, and do not take into account the importance of detection performance feedback for improving image quality. Therefore, detection performance is limited by the passive nature of the conventional object detection framework. In order to solve the above limitations, this paper takes adaptive brightness adjustment and scale adjustment as examples, and proposes an active object detection method based on deep reinforcement learning. The goal of adaptive image attribute learning is to maximize the detection performance. With the help of active object detection and image attribute adjustment strategies, low-quality images can be converted into high-quality images, and the overall performance is improved without retraining the detector.