 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTOP: Time Optimization Policy for Stable and Accurate Standing Manipulation with Humanoid Robots
Aug 01, 2025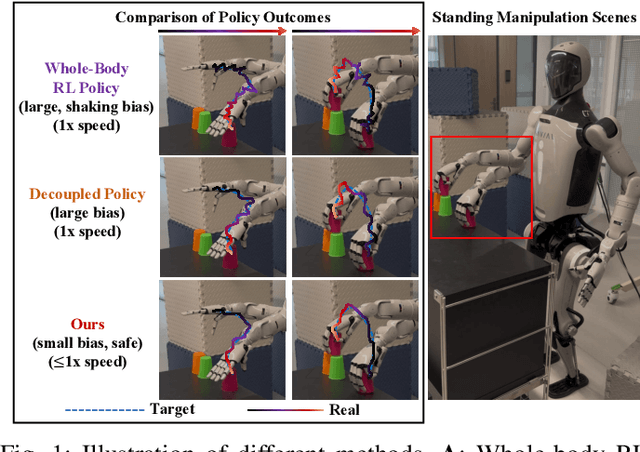
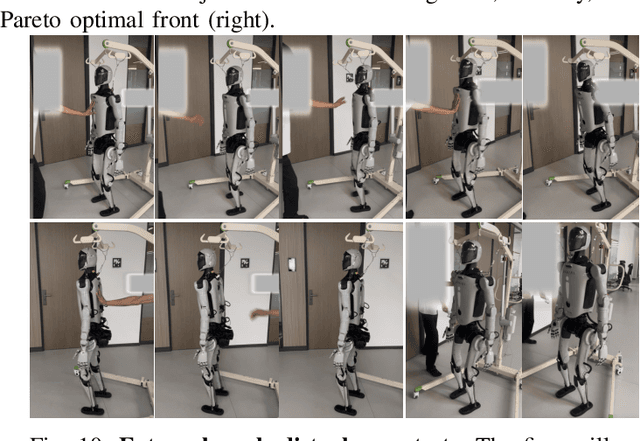

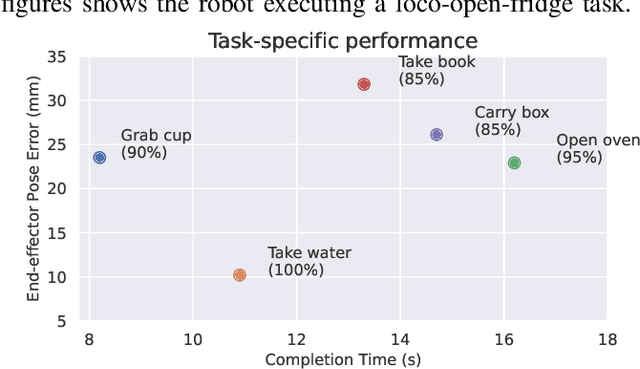
Humanoid robots have the potential capability to perform a diverse range of manipulation tasks, but this is based on a robust and precise standing controller. Existing methods are either ill-suited to precisely control high-dimensional upper-body joints, or difficult to ensure both robustness and accuracy, especially when upper-body motions are fast. This paper proposes a novel time optimization policy (TOP), to train a standing manipulation control model that ensures balance, precision, and time efficiency simultaneously, with the idea of adjusting the time trajectory of upper-body motions but not only strengthening the disturbance resistance of the lower-body. Our approach consists of three parts. Firstly, we utilize motion prior to represent upper-body motions to enhance the coordination ability between the upper and lower-body by training a variational autoencoder (VAE). Then we decouple the whole-body control into an upper-body PD controller for precision and a lower-body RL controller to enhance robust stability. Finally, we train TOP method in conjunction with the decoupled controller and VAE to reduce the balance burden resulting from fast upper-body motions that would destabilize the robot and exceed the capabilities of the lower-body RL policy. The effectiveness of the proposed approach is evaluated via both simulation and real world experiments, which demonstrate the superiority on standing manipulation tasks stably and accurately. The project page can be found at https://anonymous.4open.science/w/top-258F/.
Natural Humanoid Robot Locomotion with Generative Motion Prior
Mar 12, 2025Natural and lifelike locomotion remains a fundamental challenge for humanoid robots to interact with human society. However, previous methods either neglect motion naturalness or rely on unstable and ambiguous style rewards. In this paper, we propose a novel Generative Motion Prior (GMP) that provides fine-grained motion-level supervision for the task of natural humanoid robot locomotion. To leverage natural human motions, we first employ whole-body motion retargeting to effectively transfer them to the robot. Subsequently, we train a generative model offline to predict future natural reference motions for the robot based on a conditional variational auto-encoder. During policy training, the generative motion prior serves as a frozen online motion generator, delivering precise and comprehensive supervision at the trajectory level, including joint angles and keypoint positions. The generative motion prior significantly enhances training stability and improves interpretability by offering detailed and dense guidance throughout the learning process. Experimental results in both simulation and real-world environments demonstrate that our method achieves superior motion naturalness compared to existing approaches. Project page can be found at https://sites.google.com/view/humanoid-gmp
Domain Adaptive Graph Classification
Dec 21, 2023Despite the remarkable accomplishments of graph neural networks (GNNs), they typically rely on task-specific labels, posing potential challenges in terms of their acquisition. Existing work have been made to address this issue through the lens of unsupervised domain adaptation, wherein labeled source graphs are utilized to enhance the learning process for target data. However, the simultaneous exploration of graph topology and reduction of domain disparities remains a substantial hurdle. In this paper, we introduce the Dual Adversarial Graph Representation Learning (DAGRL), which explore the graph topology from dual branches and mitigate domain discrepancies via dual adversarial learning. Our method encompasses a dual-pronged structure, consisting of a graph convolutional network branch and a graph kernel branch, which enables us to capture graph semantics from both implicit and explicit perspectives. Moreover, our approach incorporates adaptive perturbations into the dual branches, which align the source and target distribution to address domain discrepancies. Extensive experiments on a wild range graph classification datasets demonstrate the effectiveness of our proposed method.
Just-in-Time Security Patch Detection -- LLM At the Rescue for Data Augmentation
Dec 02, 2023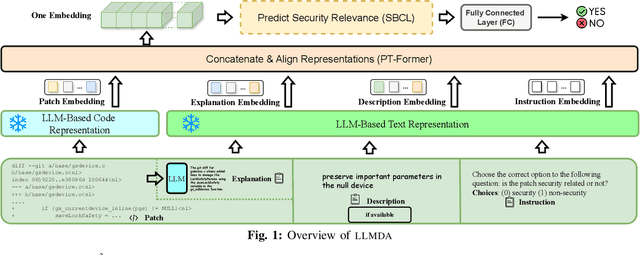
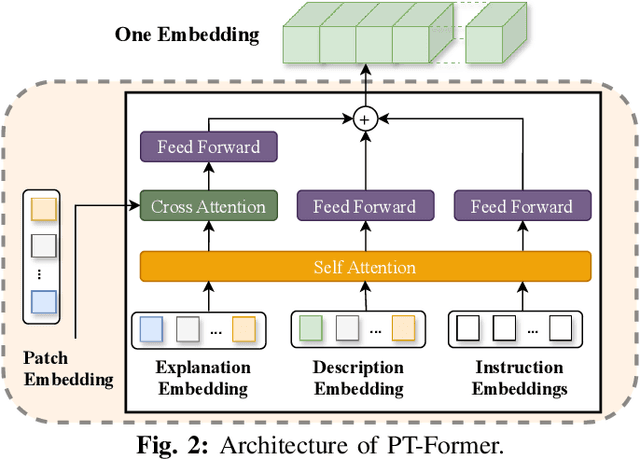
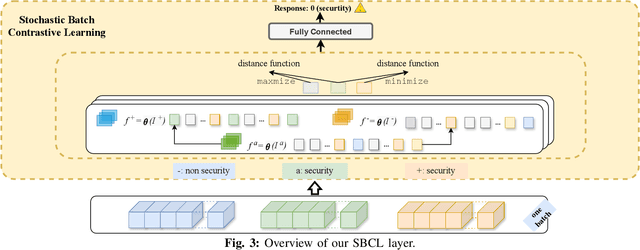
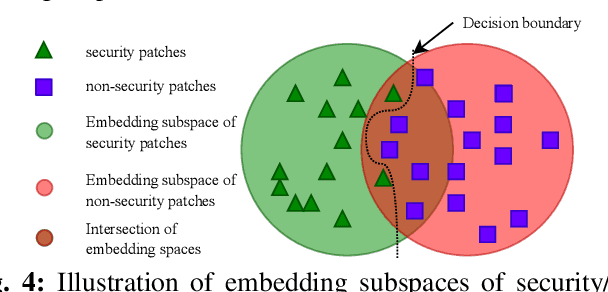
In the face of growing vulnerabilities found in open-source software, the need to identify {discreet} security patches has become paramount. The lack of consistency in how software providers handle maintenance often leads to the release of security patches without comprehensive advisories, leaving users vulnerable to unaddressed security risks. To address this pressing issue, we introduce a novel security patch detection system, LLMDA, which capitalizes on Large Language Models (LLMs) and code-text alignment methodologies for patch review, data enhancement, and feature combination. Within LLMDA, we initially utilize LLMs for examining patches and expanding data of PatchDB and SPI-DB, two security patch datasets from recent literature. We then use labeled instructions to direct our LLMDA, differentiating patches based on security relevance. Following this, we apply a PTFormer to merge patches with code, formulating hybrid attributes that encompass both the innate details and the interconnections between the patches and the code. This distinctive combination method allows our system to capture more insights from the combined context of patches and code, hence improving detection precision. Finally, we devise a probabilistic batch contrastive learning mechanism within batches to augment the capability of the our LLMDA in discerning security patches. The results reveal that LLMDA significantly surpasses the start of the art techniques in detecting security patches, underscoring its promise in fortifying software maintenance.
Music Generation based on Generative Adversarial Networks with Transformer
Oct 03, 2023
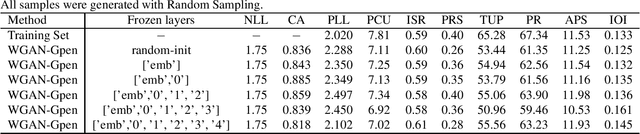
Autoregressive models based on Transformers have become the prevailing approach for generating music compositions that exhibit comprehensive musical structure. These models are typically trained by minimizing the negative log-likelihood (NLL) of the observed sequence in an autoregressive manner. However, when generating long sequences, the quality of samples from these models tends to significantly deteriorate due to exposure bias. To address this issue, we leverage classifiers trained to differentiate between real and sampled sequences to identify these failures. This observation motivates our exploration of adversarial losses as a complement to the NLL objective. We employ a pre-trained Span-BERT model as the discriminator in the Generative Adversarial Network (GAN) framework, which enhances training stability in our experiments. To optimize discrete sequences within the GAN framework, we utilize the Gumbel-Softmax trick to obtain a differentiable approximation of the sampling process. Additionally, we partition the sequences into smaller chunks to ensure that memory constraints are met. Through human evaluations and the introduction of a novel discriminative metric, we demonstrate that our approach outperforms a baseline model trained solely on likelihood maximization.