 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCorrectness isnt Efficiency: Runtime Memory Divergence in LLM-Generated Code
Jan 03, 2026Large language models (LLMs) can generate programs that pass unit tests, but passing tests does not guarantee reliable runtime behavior. We find that different correct solutions to the same task can show very different memory and performance patterns, which can lead to hidden operational risks. We present a framework to measure execution-time memory stability across multiple correct generations. At the solution level, we introduce Dynamic Mean Pairwise Distance (DMPD), which uses Dynamic Time Warping to compare the shapes of memory-usage traces after converting them into Monotonic Peak Profiles (MPPs) to reduce transient noise. Aggregating DMPD across tasks yields a model-level Model Instability Score (MIS). Experiments on BigOBench and CodeContests show substantial runtime divergence among correct solutions. Instability often increases with higher sampling temperature even when pass@1 improves. We also observe correlations between our stability measures and software engineering indicators such as cognitive and cyclomatic complexity, suggesting links between operational behavior and maintainability. Our results support stability-aware selection among passing candidates in CI/CD to reduce operational risk without sacrificing correctness. Artifacts are available.
Dynamic Stability of LLM-Generated Code
Nov 07, 2025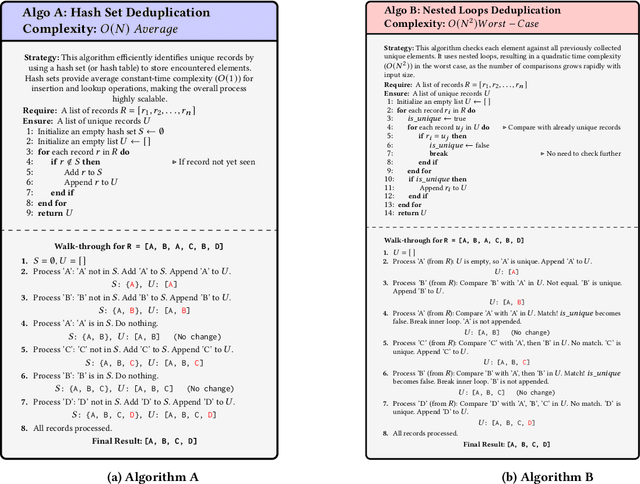
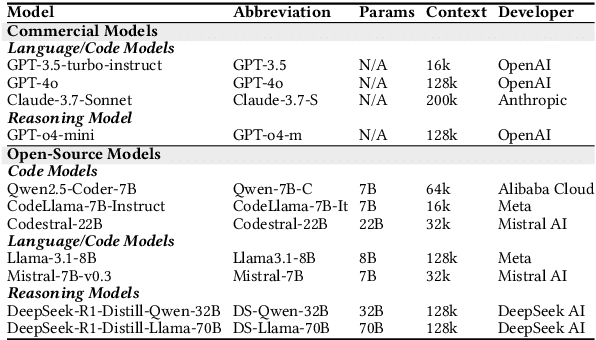
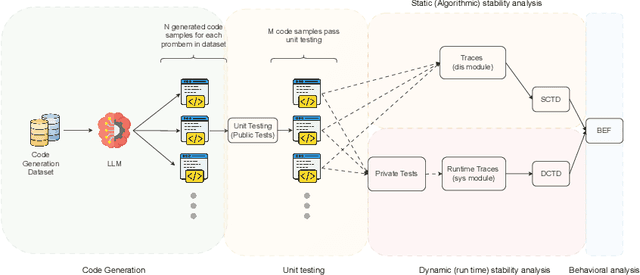
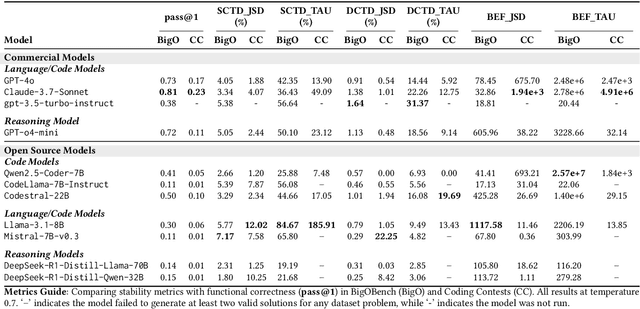
Current evaluations of LLMs for code generation emphasize functional correctness, overlooking the fact that functionally correct solutions can differ significantly in algorithmic complexity. For instance, an $(O(n^2))$ versus $(O(n \log n))$ sorting algorithm may yield similar output but incur vastly different performance costs in production. This discrepancy reveals a critical limitation in current evaluation methods: they fail to capture the behavioral and performance diversity among correct solutions. To address this, we introduce a principled framework for evaluating the dynamic stability of generated code. We propose two metrics derived from opcode distributions: Static Canonical Trace Divergence (SCTD), which captures algorithmic structure diversity across generated solutions, and Dynamic Canonical Trace Divergence (DCTD), which quantifies runtime behavioral variance. Their ratio, the Behavioral Expression Factor (BEF), serves as a diagnostic signal: it indicates critical runtime instability when BEF $\ll$ 1 and functional redundancy when BEF $\gg$ 1. Empirical results on BigOBench and CodeContests show that state-of-the-art LLMs exhibit significant algorithmic variance even among functionally correct outputs. Notably, increasing sampling temperature improves pass@1 rates but degrades stability, revealing an unrecognized trade-off: searching for correct solutions in diverse output spaces introduces a "penalty of instability" between correctness and behavioral consistency. Our findings call for stability-aware objectives in code generation and new benchmarks with asymptotic test cases for robust, real-world LLM evaluation.
Large Language Models for cross-language code clone detection
Aug 08, 2024With the involvement of multiple programming languages in modern software development, cross-lingual code clone detection has gained traction with the software engineering community. Numerous studies have explored this topic, proposing various promising approaches. Inspired by the significant advances in machine learning in recent years, particularly Large Language Models (LLMs), which have demonstrated their ability to tackle various tasks, this paper revisits cross-lingual code clone detection. We investigate the capabilities of four (04) LLMs and eight (08) prompts for the identification of cross-lingual code clones. Additionally, we evaluate a pre-trained embedding model to assess the effectiveness of the generated representations for classifying clone and non-clone pairs. Both studies (based on LLMs and Embedding models) are evaluated using two widely used cross-lingual datasets, XLCoST and CodeNet. Our results show that LLMs can achieve high F1 scores, up to 0.98, for straightforward programming examples (e.g., from XLCoST). However, they not only perform less well on programs associated with complex programming challenges but also do not necessarily understand the meaning of code clones in a cross-lingual setting. We show that embedding models used to represent code fragments from different programming languages in the same representation space enable the training of a basic classifier that outperforms all LLMs by ~2 and ~24 percentage points on the XLCoST and CodeNet datasets, respectively. This finding suggests that, despite the apparent capabilities of LLMs, embeddings provided by embedding models offer suitable representations to achieve state-of-the-art performance in cross-lingual code clone detection.
DexRay: A Simple, yet Effective Deep Learning Approach to Android Malware Detection based on Image Representation of Bytecode
Sep 05, 2021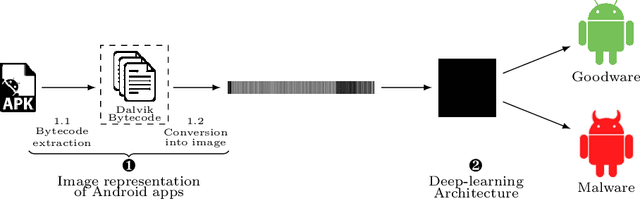


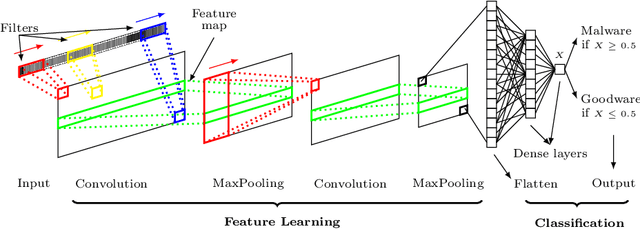
Computer vision has witnessed several advances in recent years, with unprecedented performance provided by deep representation learning research. Image formats thus appear attractive to other fields such as malware detection, where deep learning on images alleviates the need for comprehensively hand-crafted features generalising to different malware variants. We postulate that this research direction could become the next frontier in Android malware detection, and therefore requires a clear roadmap to ensure that new approaches indeed bring novel contributions. We contribute with a first building block by developing and assessing a baseline pipeline for image-based malware detection with straightforward steps. We propose DexRay, which converts the bytecode of the app DEX files into grey-scale "vector" images and feeds them to a 1-dimensional Convolutional Neural Network model. We view DexRay as foundational due to the exceedingly basic nature of the design choices, allowing to infer what could be a minimal performance that can be obtained with image-based learning in malware detection. The performance of DexRay evaluated on over 158k apps demonstrates that, while simple, our approach is effective with a high detection rate(F1-score= 0.96). Finally, we investigate the impact of time decay and image-resizing on the performance of DexRay and assess its resilience to obfuscation. This work-in-progress paper contributes to the domain of Deep Learning based Malware detection by providing a sound, simple, yet effective approach (with available artefacts) that can be the basis to scope the many profound questions that will need to be investigated to fully develop this domain.