 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLuxInstruct: A Cross-Lingual Instruction Tuning Dataset For Luxembourgish
Oct 08, 2025Instruction tuning has become a key technique for enhancing the performance of large language models, enabling them to better follow human prompts. However, low-resource languages such as Luxembourgish face severe limitations due to the lack of high-quality instruction datasets. Traditional reliance on machine translation often introduces semantic misalignment and cultural inaccuracies. In this work, we address these challenges by creating a cross-lingual instruction tuning dataset for Luxembourgish, without resorting to machine-generated translations into it. Instead, by leveraging aligned data from English, French, and German, we build a high-quality dataset that preserves linguistic and cultural nuances. We provide evidence that cross-lingual instruction tuning not only improves representational alignment across languages but also the model's generative capabilities in Luxembourgish. This highlights how cross-lingual data curation can avoid the common pitfalls of machine-translated data and directly benefit low-resource language development.
Enhancing Small Language Models for Cross-Lingual Generalized Zero-Shot Classification with Soft Prompt Tuning
Mar 25, 2025In NLP, Zero-Shot Classification (ZSC) has become essential for enabling models to classify text into categories unseen during training, particularly in low-resource languages and domains where labeled data is scarce. While pretrained language models (PLMs) have shown promise in ZSC, they often rely on large training datasets or external knowledge, limiting their applicability in multilingual and low-resource scenarios. Recent approaches leveraging natural language prompts reduce the dependence on large training datasets but struggle to effectively incorporate available labeled data from related classification tasks, especially when these datasets originate from different languages or distributions. Moreover, existing prompt-based methods typically rely on manually crafted prompts in a specific language, limiting their adaptability and effectiveness in cross-lingual settings. To address these challenges, we introduce RoSPrompt, a lightweight and data-efficient approach for training soft prompts that enhance cross-lingual ZSC while ensuring robust generalization across data distribution shifts. RoSPrompt is designed for small multilingual PLMs, enabling them to leverage high-resource languages to improve performance in low-resource settings without requiring extensive fine-tuning or high computational costs. We evaluate our approach on multiple multilingual PLMs across datasets covering 106 languages, demonstrating strong cross-lingual transfer performance and robust generalization capabilities over unseen classes.
LuxEmbedder: A Cross-Lingual Approach to Enhanced Luxembourgish Sentence Embeddings
Dec 05, 2024



Sentence embedding models play a key role in various Natural Language Processing tasks, such as in Topic Modeling, Document Clustering and Recommendation Systems. However, these models rely heavily on parallel data, which can be scarce for many low-resource languages, including Luxembourgish. This scarcity results in suboptimal performance of monolingual and cross-lingual sentence embedding models for these languages. To address this issue, we compile a relatively small but high-quality human-generated cross-lingual parallel dataset to train LuxEmbedder, an enhanced sentence embedding model for Luxembourgish with strong cross-lingual capabilities. Additionally, we present evidence suggesting that including low-resource languages in parallel training datasets can be more advantageous for other low-resource languages than relying solely on high-resource language pairs. Furthermore, recognizing the lack of sentence embedding benchmarks for low-resource languages, we create a paraphrase detection benchmark specifically for Luxembourgish, aiming to partially fill this gap and promote further research.
Forget NLI, Use a Dictionary: Zero-Shot Topic Classification for Low-Resource Languages with Application to Luxembourgish
Apr 05, 2024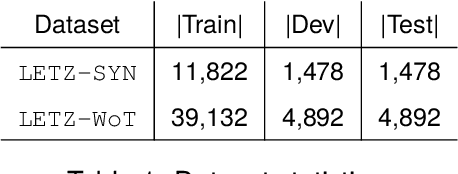
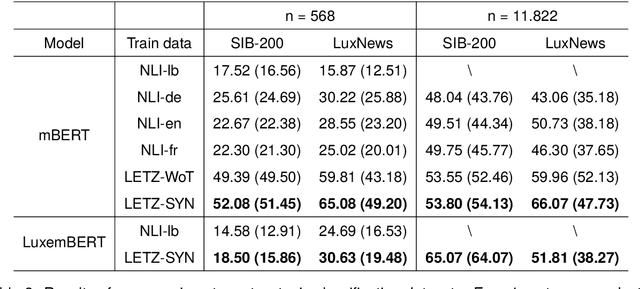
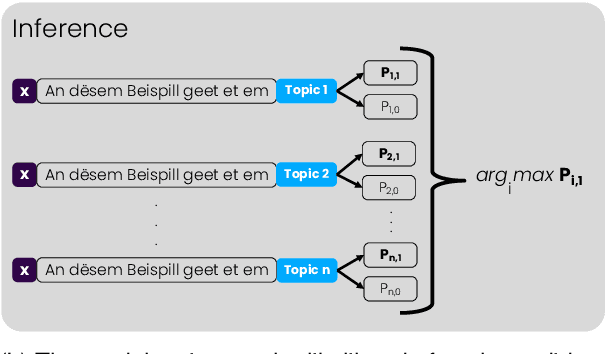
In NLP, zero-shot classification (ZSC) is the task of assigning labels to textual data without any labeled examples for the target classes. A common method for ZSC is to fine-tune a language model on a Natural Language Inference (NLI) dataset and then use it to infer the entailment between the input document and the target labels. However, this approach faces certain challenges, particularly for languages with limited resources. In this paper, we propose an alternative solution that leverages dictionaries as a source of data for ZSC. We focus on Luxembourgish, a low-resource language spoken in Luxembourg, and construct two new topic relevance classification datasets based on a dictionary that provides various synonyms, word translations and example sentences. We evaluate the usability of our dataset and compare it with the NLI-based approach on two topic classification tasks in a zero-shot manner. Our results show that by using the dictionary-based dataset, the trained models outperform the ones following the NLI-based approach for ZSC. While we focus on a single low-resource language in this study, we believe that the efficacy of our approach can also transfer to other languages where such a dictionary is available.
Soft Prompt Tuning for Cross-Lingual Transfer: When Less is More
Feb 06, 2024



Soft Prompt Tuning (SPT) is a parameter-efficient method for adapting pre-trained language models (PLMs) to specific tasks by inserting learnable embeddings, or soft prompts, at the input layer of the PLM, without modifying its parameters. This paper investigates the potential of SPT for cross-lingual transfer. Unlike previous studies on SPT for cross-lingual transfer that often fine-tune both the soft prompt and the model parameters, we adhere to the original intent of SPT by keeping the model parameters frozen and only training the soft prompt. This does not only reduce the computational cost and storage overhead of full-model fine-tuning, but we also demonstrate that this very parameter efficiency intrinsic to SPT can enhance cross-lingual transfer performance to linguistically distant languages. Moreover, we explore how different factors related to the prompt, such as the length or its reparameterization, affect cross-lingual transfer performance.
Towards a Common Understanding of Contributing Factors for Cross-Lingual Transfer in Multilingual Language Models: A Review
May 26, 2023
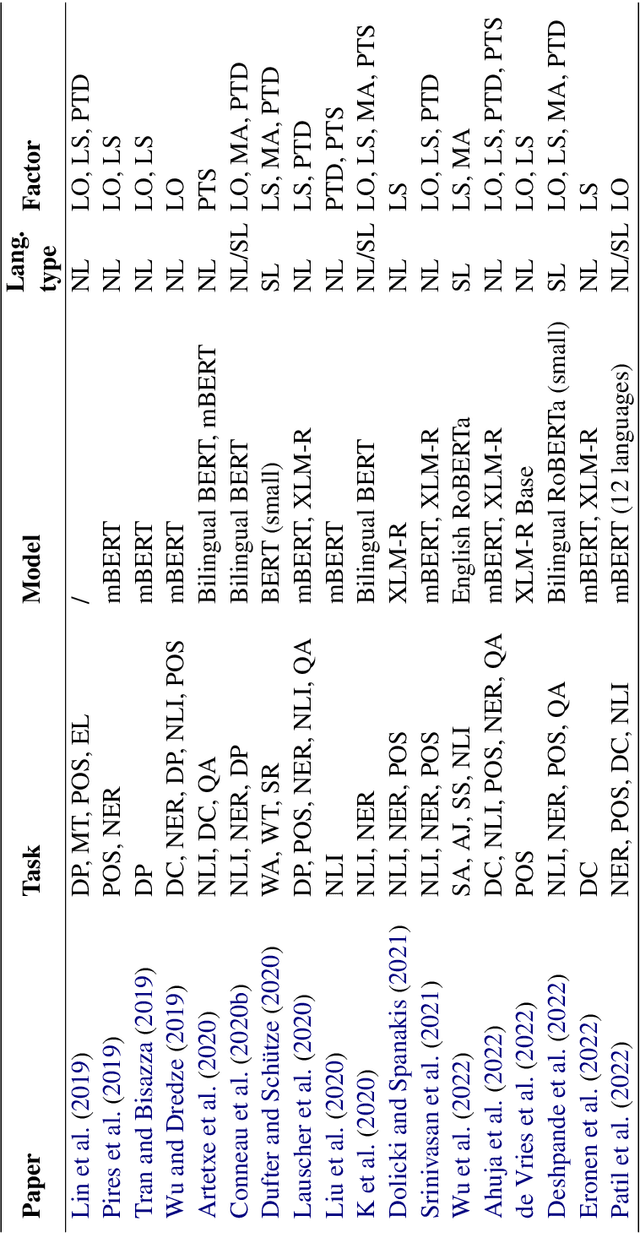
In recent years, pre-trained Multilingual Language Models (MLLMs) have shown a strong ability to transfer knowledge across different languages. However, given that the aspiration for such an ability has not been explicitly incorporated in the design of the majority of MLLMs, it is challenging to obtain a unique and straightforward explanation for its emergence. In this review paper, we survey literature that investigates different factors contributing to the capacity of MLLMs to perform zero-shot cross-lingual transfer and subsequently outline and discuss these factors in detail. To enhance the structure of this review and to facilitate consolidation with future studies, we identify five categories of such factors. In addition to providing a summary of empirical evidence from past studies, we identify consensuses among studies with consistent findings and resolve conflicts among contradictory ones. Our work contextualizes and unifies existing research streams which aim at explaining the cross-lingual potential of MLLMs. This review provides, first, an aligned reference point for future research and, second, guidance for a better-informed and more efficient way of leveraging the cross-lingual capacity of MLLMs.
Identifying the Correlation Between Language Distance and Cross-Lingual Transfer in a Multilingual Representation Space
May 03, 2023
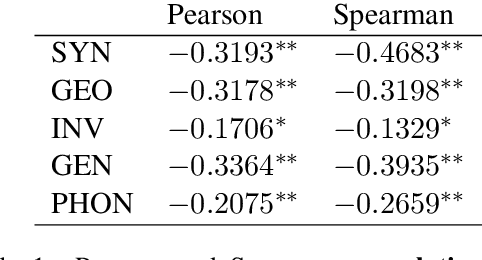

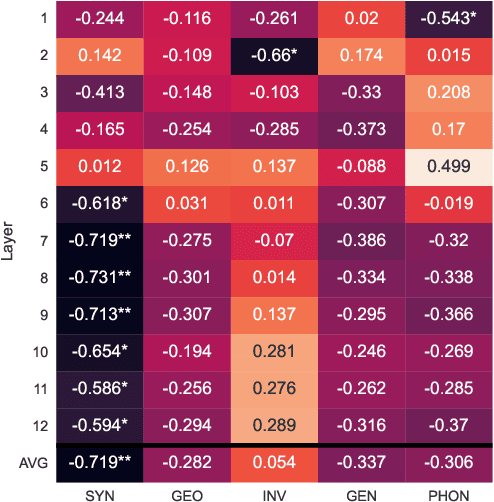
Prior research has investigated the impact of various linguistic features on cross-lingual transfer performance. In this study, we investigate the manner in which this effect can be mapped onto the representation space. While past studies have focused on the impact on cross-lingual alignment in multilingual language models during fine-tuning, this study examines the absolute evolution of the respective language representation spaces produced by MLLMs. We place a specific emphasis on the role of linguistic characteristics and investigate their inter-correlation with the impact on representation spaces and cross-lingual transfer performance. Additionally, this paper provides preliminary evidence of how these findings can be leveraged to enhance transfer to linguistically distant languages.