 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeForget NLI, Use a Dictionary: Zero-Shot Topic Classification for Low-Resource Languages with Application to Luxembourgish
Paper and Code
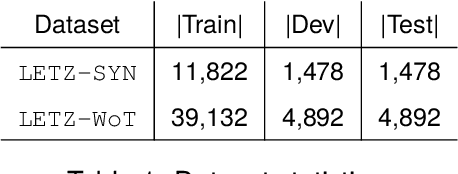
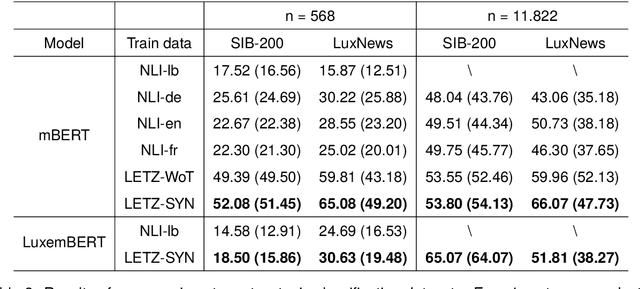
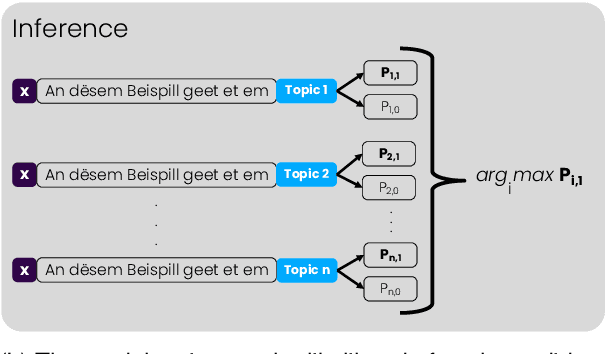
In NLP, zero-shot classification (ZSC) is the task of assigning labels to textual data without any labeled examples for the target classes. A common method for ZSC is to fine-tune a language model on a Natural Language Inference (NLI) dataset and then use it to infer the entailment between the input document and the target labels. However, this approach faces certain challenges, particularly for languages with limited resources. In this paper, we propose an alternative solution that leverages dictionaries as a source of data for ZSC. We focus on Luxembourgish, a low-resource language spoken in Luxembourg, and construct two new topic relevance classification datasets based on a dictionary that provides various synonyms, word translations and example sentences. We evaluate the usability of our dataset and compare it with the NLI-based approach on two topic classification tasks in a zero-shot manner. Our results show that by using the dictionary-based dataset, the trained models outperform the ones following the NLI-based approach for ZSC. While we focus on a single low-resource language in this study, we believe that the efficacy of our approach can also transfer to other languages where such a dictionary is available.