 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevisiting Code Similarity Evaluation with Abstract Syntax Tree Edit Distance
Paper and Code
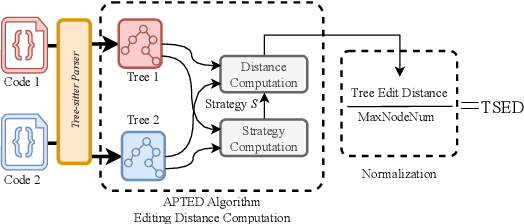
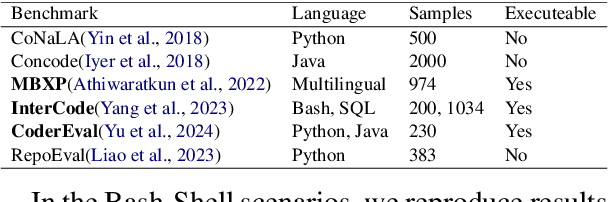
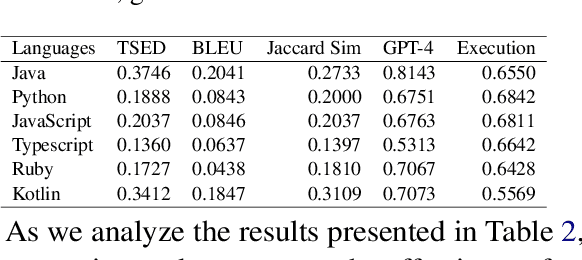
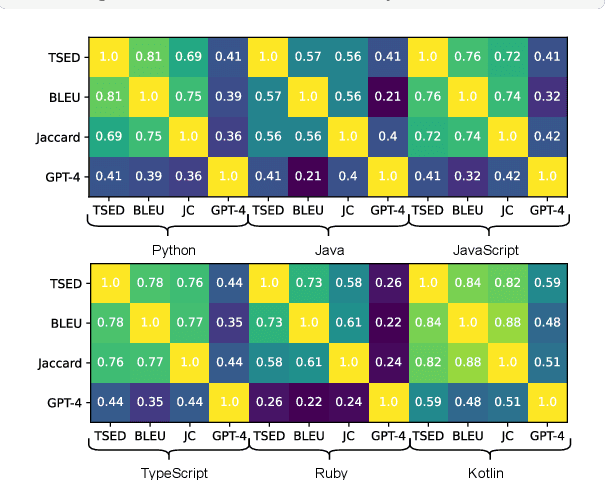
This paper revisits recent code similarity evaluation metrics, particularly focusing on the application of Abstract Syntax Tree (AST) editing distance in diverse programming languages. In particular, we explore the usefulness of these metrics and compare them to traditional sequence similarity metrics. Our experiments showcase the effectiveness of AST editing distance in capturing intricate code structures, revealing a high correlation with established metrics. Furthermore, we explore the strengths and weaknesses of AST editing distance and prompt-based GPT similarity scores in comparison to BLEU score, execution match, and Jaccard Similarity. We propose, optimize, and publish an adaptable metric that demonstrates effectiveness across all tested languages, representing an enhanced version of Tree Similarity of Edit Distance (TSED).